
Python操作rabbitmq系列(一)
从本文开始,接下来的内容,我们将讨论rabbitmq的相关功能。我的这些文章,最终是要实现一个项目(具体是什么暂不透露)。前面每一篇,都是在为这个系统做准备。rabbitmq,是我们这个项目的关键部分之一。所以牛小妹,这个系列,请务必搞懂rabbitmq是怎么回事,并知道,该如何操作。
在这一篇文章里,我们知道rabbitmq简单逻辑即可。
生产消息:
消费消息:
就跟QQ一样,我在这边发,并不是直接发给你,而是发给了中间的服务器,你接收也不直接从我这里接,从服务器去取。
上图红色部分,就是队列,队列就是用来缓冲消息的。这样,我们双边不断发消息,就不会让自己受阻。
在开始编码实践之前。我们需要安装rabbitmq server和python client。
安装rabbitmq server参考文章
安装python client:使用pip install pika
安装完后,我们就可以尝试官方文档的demo:
发送端:
import pika
#连接队列服务器
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
#创建队列。有就不管,没有就自动创建
channel.queue_declare(queue='hello')
#使用默认的交换机发送消息。exchange为空就使用默认的
channel.basic_publish(exchange='', routing_key='hello', body='Hello World!')
print(" [x] Sent 'Hello World!'")
connection.close()
服务器收到的消息效果如图:
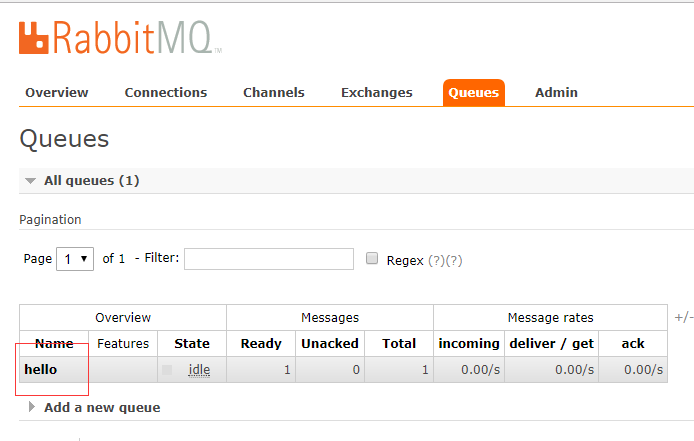
客户端消费消息:
import pika
# 连接服务器
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
# rabbitmq消费端仍然使用此方法创建队列。这样做的意思是:若是没有就创建。和发送端道理道理。目的是为了保证队列一定会有
channel.queue_declare(queue='hello')
# 收到消息后的回调
def callback(ch, method, properties, body):
print(" [x] Received %r" % body)
channel.basic_consume(callback, queue='hello', no_ack=True)
print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming()
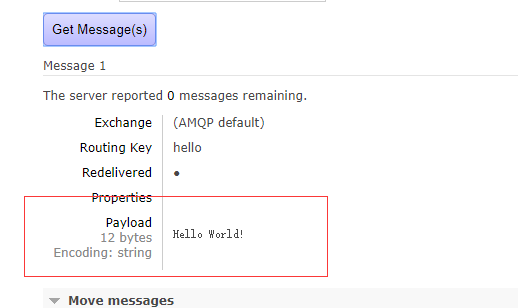
收到的消息:
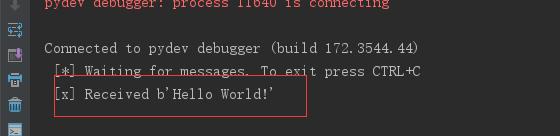
然后回头看服务器管理台:
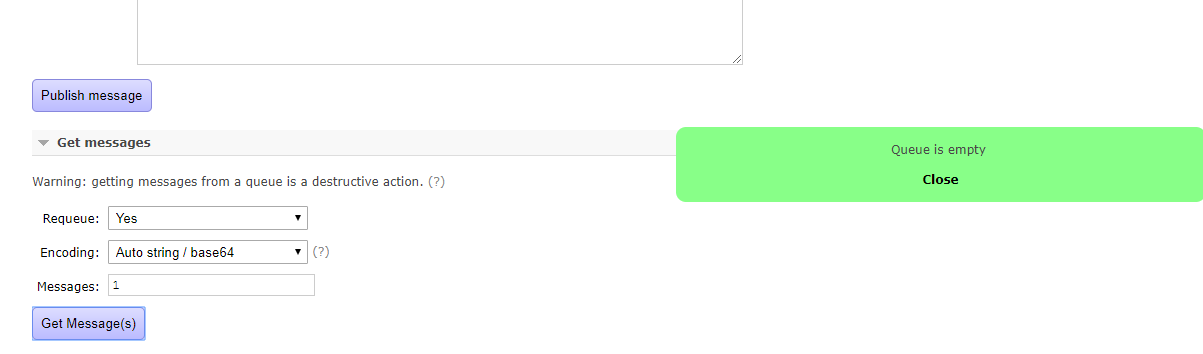
消息被消费后,队列就相应的移除。
今天,我们就对rabbitmq入门以下即可。在下一章,我们将讨论用于在多个工作人员之间分配耗时的任务。这个在并发比较高的web应用中尤为有用。
备注:代码来源于官方文档。因为是英文,专业性较强,有些同学看起吃力,这里就我司的实际运用后的理解,重新阐述一遍,希望它更容易学习。

