在结构方程模型中,调节参数,卡方的含义,mplus的参数与amos的参数, 标准化系数的标准差(mplus)
title: zhanglijiaRegression; data: file is C:\\users\\mike1\\desktop\\data\\zhanglijia\\dataExperiment.csv; variable: names are x,y1,y2,y3; usevariables are x,y1,y2,y3; analysis: type=general; estimator=ML; model: y by y1,y2,y3; y on x; y1 with y2; output: sampstat standardized modindices;
在这里必须要写上, modindices 才能够产生关于调节参数的结果

可以看到调参的建议
与amos参数的区别,amos有很多的参数,但是,mplus只有 卡方of model fit , 卡方 model fit for baseline model , CFI ,TLI, RMSEA, SRMR, 这几个参数,其中,第一个卡方说明的是样本的数据与模型的拟合程度,要不显著,并且与DF的比较要小于3, 第二个卡方要显著,说明与最烂的模型有差异,RMSEA, SRMER 要小于0.08,
CFI,TLI 要大于0.95.
下图说明模型并不好,要调参.

调参代码, 只是增加了 y1 with y2
title: zhanglijiaRegression; data: file is C:\\users\\mike1\\desktop\\data\\zhanglijia\\dataExperiment.csv; variable: names are x,y1,y2,y3; usevariables are x,y1,y2,y3; analysis: type=general; estimator=ML; model: y by y1,y2,y3; y on x; y1 with y2; output: sampstat standardized modindices;
调参结果: 结果显示,良好

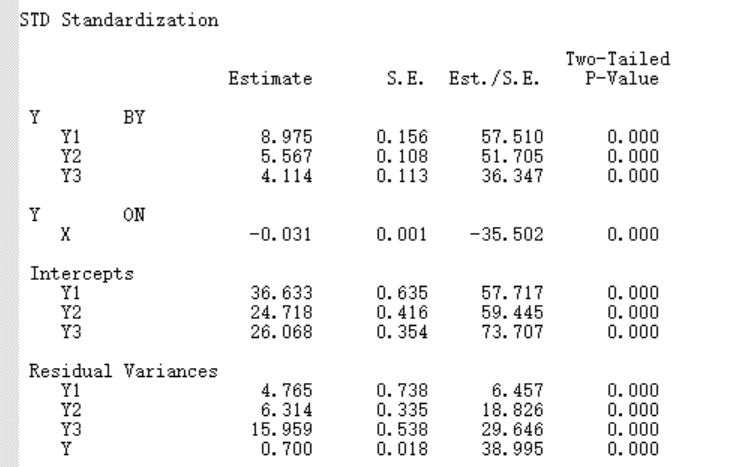
这个R方,说明了自变量对因变量的解释程度,用1-R方, 就是 残差的R方值.

这是标准化的系数,但是标准化的系数标准差应该是1, 这里的标准差,应该是一个估计值, 一般在报告结果时, 只会报告,非标的T值,置信区间,P值,对于标准化系数,报告一个值,就可以了.
但是如果先将原来的数据标准化,在求非标的系数,其结果应该就是标准化的系数.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号