
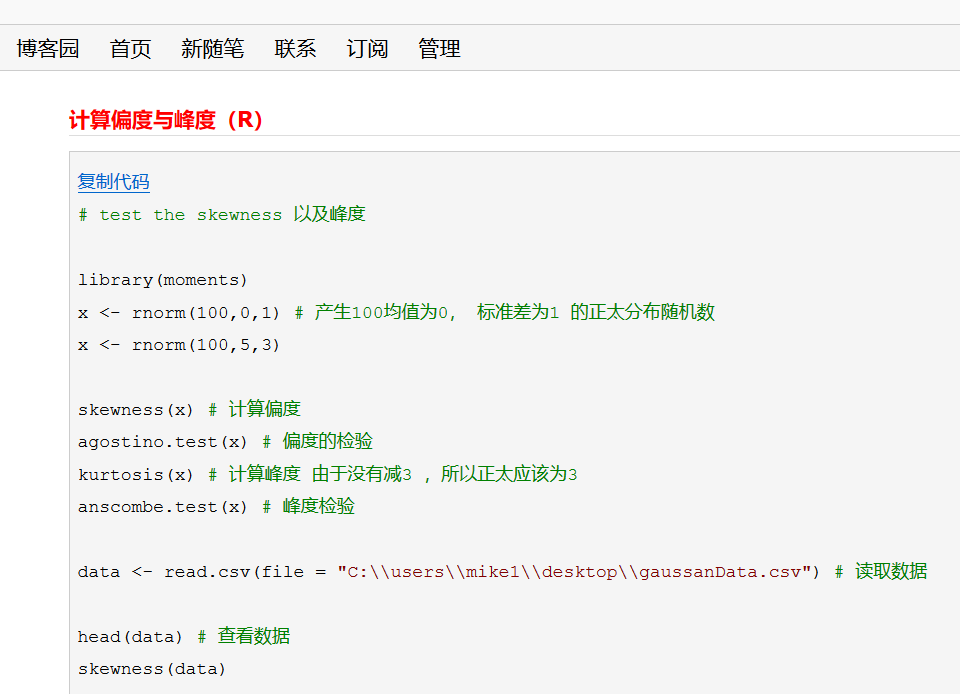
爬取一张网页(retrieve)

# 设置爬虫的用户代理池以及ip代理池 import urllib.request import random def set_user_ip_proxy(): #设置用户代理池 header_list = ["Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:78.0) Gecko/20100101 Firefox/78.0","Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3704.400 QQBrowser/10.4.3587.400"] #设置ip池 ip_pools = ["123.54.44.4:9999","110.243.13.120:9999", "183.166.97.101:9999"] #构建ip代理以及用户代理 random_ip = random.choice(ip_pools) creat_ip = urllib.request.ProxyHandler({"http" : random_ip}) creat_opener = urllib.request.build_opener(creat_ip) header = ("User-Agent", random.choice(header_list)) creat_opener.addheaders = [header] urllib.request.install_opener(creat_opener) print("当前的header是:", header) print("当前的ip是:",random_ip) return 0 for i in range(2): try: set_user_ip_proxy() urllib.request.urlretrieve("https://www.cnblogs.com/zijidefengge/p/12445145.html", "C:/users/mike1/desktop/" + str(i) + ".html") except Exception as error: continue

下图为爬取取得html网页


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律