Python(模块(modue)、包(package))
''' 一 模块 模块一共三种: python标准库 第三方模块 应用程序自定义模块 模块两种执行方式: 1 用于启动执行 2 用于被调用执行
key:import module: 将执行文件(module)的目录路径插入到sys.path的第一个位置 import的两个过程: 1 创建新的名称空间 {名字:对象} 2 执行被调用的模块 (第二次不会被执行) 修改调用模块的名字:import logging as log from 模块 import 变量名 from modname import name1, name2, ... nameN 二 包(package) 组织模块的方式:包 在python中,包可以理解成一个文件夹,但是没一个文件夹里必须要有一个__init__文件 from 包 import 模块 同级目录下的被调用模块之间的相互调用 if __name__=='__main__': from 包.包 import 模块 from 包.包.模块 import 变量名字 __init__文件的作用 为了方便包的使用者调用各模块,可能要将包里的各级目录下的模块改成可以直接调用的方式。 '''
模块(modue)的概念
在计算机程序的开发过程中,随着程序代码越写越多,在一个文件里代码就会越来越长,越来越不容易维护。
为了编写可维护的代码,我们把很多函数分组,分别放到不同的文件里,这样,每个文件包含的代码就相对较少,很多编程语言都采用这种组织代码的方式。在Python中,一个.py文件就称之为一个模块(Module)。
使用模块有什么好处?
最大的好处是大大提高了代码的可维护性。
其次,编写代码不必从零开始。当一个模块编写完毕,就可以被其他地方引用。我们在编写程序的时候,也经常引用其他模块,包括Python内置的模块和来自第三方的模块。
所以,模块一共三种:
- python标准库
- 第三方模块
- 应用程序自定义模块
另外,使用模块还可以避免函数名和变量名冲突。相同名字的函数和变量完全可以分别存在不同的模块中,因此,我们自己在编写模块时,不必考虑名字会与其他模块冲突。但是也要注意,尽量不要与内置函数名字冲突。
模块导入方法
1 import 语句
|
1
|
import module1, module2,... moduleN |
当我们使用import语句的时候,Python解释器是怎样找到对应的文件的呢?答案就是解释器有自己的搜索路径,存在sys.path里。
因此若像我一样在当前目录下存在与要引入模块同名的文件,就会把要引入的模块屏蔽掉。
当import foo时,首先会立刻创建一个新的名称空间,用来存放所有foo.py中定义的名字;然后会在该名称空间内执行foo.py内所
有的代码,最后需要知道的是import关键字
就是定义了一个名字,只不过此刻我们用import定义的是一个模块名字foo,该名字就是指
向foo.py的名称空间,而foo.的方式就是从该名称空间里找名字,可以使用foo.__dict__来查看这些名字。
在新建的名称空间里执行源文件(foo.py)代码时,所有对全局名称空间的引用或修改,都是以foo.py为准,而不是当前文件(test.py)的全局名称空间
注意1:
个模块可以在当前位置import多次,但只有第一次导入会执行源文件内的代码,原因是:第一次导入就会将模块包含的内
容统统加载到内存了,以后在当前文件位置的导入都是指向内存中已有的模块
注意2:
|
1
2
3
|
import logging as loglog.critical("www") |
2 from…import 语句
|
1
|
from modname import name1, name2, ... nameN |
这个声明不会把整个modulename模块导入到当前的命名空间中,只会将它里面的name1或name2单个引入到执行这个声明的模块的全局符号表。
其中, from…import* 语句提供了一个简单的方法来导入一个模块中的所有项目。然而这种声明不该被过多地使用。大多数情况, Python程序员不使用这种方法,因为引入的其它来源的命名,很可能覆盖了已有的定义。


from 包.包.包 import 模块
from 包.包.包.模块 import 函数
包(package)
如果不同的人编写的模块名相同怎么办?为了避免模块名冲突,Python又引入了按目录来组织模块的方法,称为包(Package)。
举个例子,一个abc.py的文件就是一个名字叫abc的模块,一个xyz.py的文件就是一个名字叫xyz的模块。
现在,假设我们的abc和xyz这两个模块名字与其他模块冲突了,于是我们可以通过包来组织模块,避免冲突。方法是选择一个顶层包名:
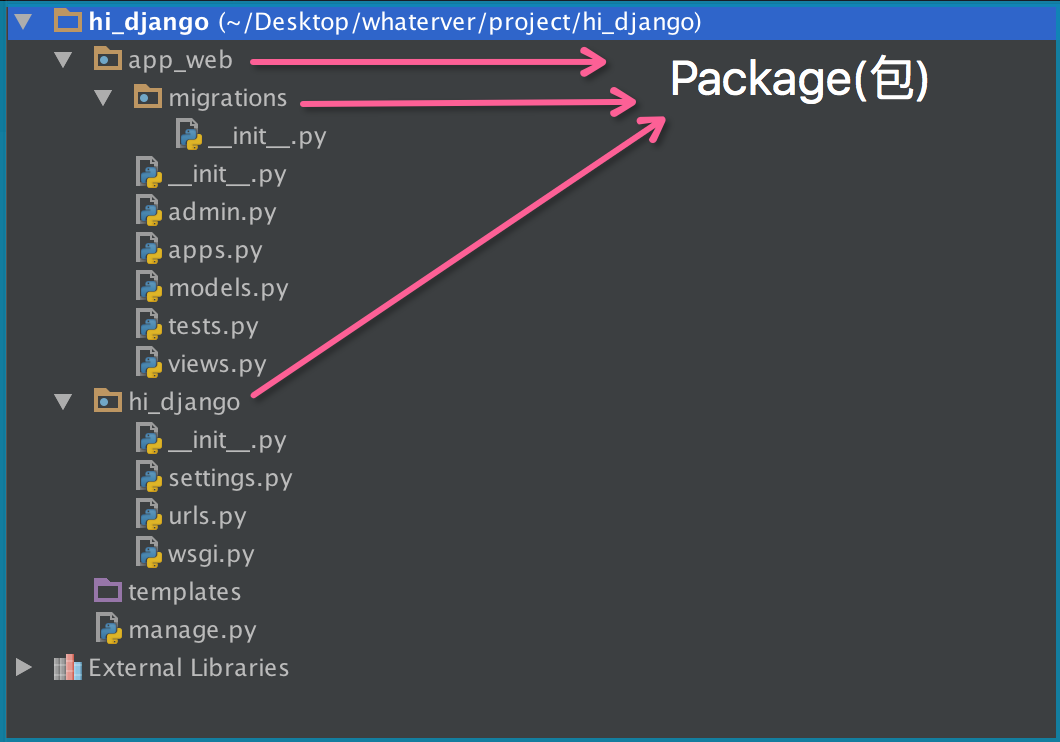
引入了包以后,只要顶层的包名不与别人冲突,那所有模块都不会与别人冲突。现在,view.py模块的名字就变成了hello_django.app01.views,类似的,manage.py的模块名则是hello_django.manage。
请注意,每一个包目录下面都会有一个__init__.py的文件,这个文件是必须存在的,否则,Python就把这个目录当成普通目录(文件夹),而不是一个包。__init__.py可以是空文件,也可以有Python代码,因为__init__.py本身就是一个模块,而它的模块名就是对应包的名字。
调用包就是执行包下的__init__.py文件
注意点(important)
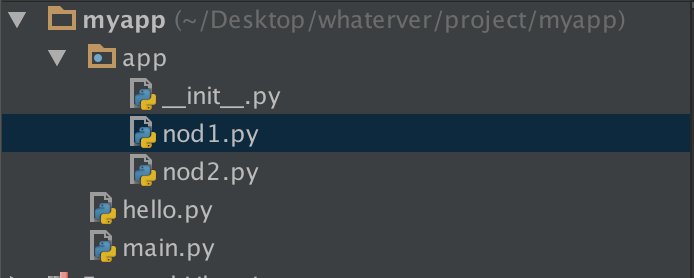
1--------------
在nod1里import hello是找不到的,有同学说可以找到呀,那是因为你的pycharm为你把myapp这一层路径加入到了sys.path里面,所以可以找到,然而程序一旦在命令行运行,则报错。有同学问那怎么办?简单啊,自己把这个路径加进去不就OK啦:
由于程序运行过程中,sys.path 总是使用的调用发起方的 sys.path ,不会使用当前程序的 sys.path ,所以每次 import 都要使用进入接口的层级来 import 。
一般来说,完整的程序都会有:一个入口包(import 、sys.path 就以其为准),一个主逻辑包(入口接过来,包含程序的主要逻辑,一般是 main 包),提供调用的各个功能的包以及模块。
|
1
2
3
4
5
|
import sys,osBASE_DIR=os.path.dirname(os.path.dirname(os.path.abspath(__file__)))sys.path.append(BASE_DIR)import hellohello.hello1() |
2 --------------
|
1
2
|
if __name__=='__main__': print('ok') |
“Make a .py both importable and executable”
如果我们是直接执行某个.py文件的时候,该文件中那么”__name__ == '__main__'“是True,但是我们如果从另外一个.py文件通过import导入该文件的时候,这时__name__的值就是我们这个py文件的名字而不是__main__。
这个功能还有一个用处:调试代码的时候,在”if __name__ == '__main__'“中加入一些我们的调试代码,我们可以让外部模块调用的时候不执行我们的调试代码,但是如果我们想排查问题的时候,直接执行该模块文件,调试代码能够正常运行!
3

##-------------cal.py
def add(x,y):
return x+y
##-------------main.py
import cal #from module import cal
def main():
cal.add(1,2)
##--------------bin.py
from module import main
main.main()
注意:
# from module import cal 改成 from . import cal同样可以,这是因为bin.py是我们的执行脚本, # sys.path里有bin.py的当前环境。即/Users/yuanhao/Desktop/whaterver/project/web这层路径, # 无论import what , 解释器都会按这个路径找。所以当执行到main.py时,import cal会找不到,因为 # sys.path里没有/Users/yuanhao/Desktop/whaterver/project/web/module这个路径,而 # from module/. import cal 时,解释器就可以找到了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号