


LEAP: Learning to Prescribe Effective and Safe Treatment Combinations for Multimorbidity
LEAP: Learning to Prescribe Effective and Safe Treatment Combinations for Multimorbidity
Authors: Yutao Zhang, Robert Chen, Jie Tang, Walter F. Stewart, Jimeng Sun
Keywords: Treatment Recommendation, Multimorbidity, Multi-Instance MultiLabel Learning
- 关键词:治疗方案推荐,多发病,多实例多标签学习
KDD’17 清华大学,佐治亚理工学院 (Georgia Institute of Technology),萨特健康 (Sutter Health)
论文链接:https://dl.acm.org/doi/pdf/10.1145/3097983.3098109
代码链接:https://github.com/neozhangthe1/AutoPrescribe
0. 总结
-
使用RNN+强化学习,根据病人的疾病给出对应药物。
-
RNN用于学习疾病和药物之间的对应关系,强化学习部分用于避免药物之间的互斥作用,以及使模型推荐结果更完整。
-
使用了MIMIC3和另一个私有数据集。
-
没有考虑病人的历史诊疗记录,也没有对剂量和服用频次等信息的考量。
1.研究目标
利用历史诊疗信息和额外的药物互斥信息,对输入的诊断,给出对应的药物推荐。
2.问题背景
针对患有多种疾病的患者,经常需要多种药物联合治疗。而药物之间可能有对抗性;治疗A疾病的药物可能对B疾病有加重效果。
3. 方法——LEAP模型
3.1 问题定义
治疗方案推荐的目标是:基于患者历史诊断记录,从所有治疗方案中选择一种最佳的推荐给患者。
面临的主要挑战:
- 学习药物和疾病之间的映射关系
- 学习药物之间的相互作用关系
3.2 Basic LEAP模型
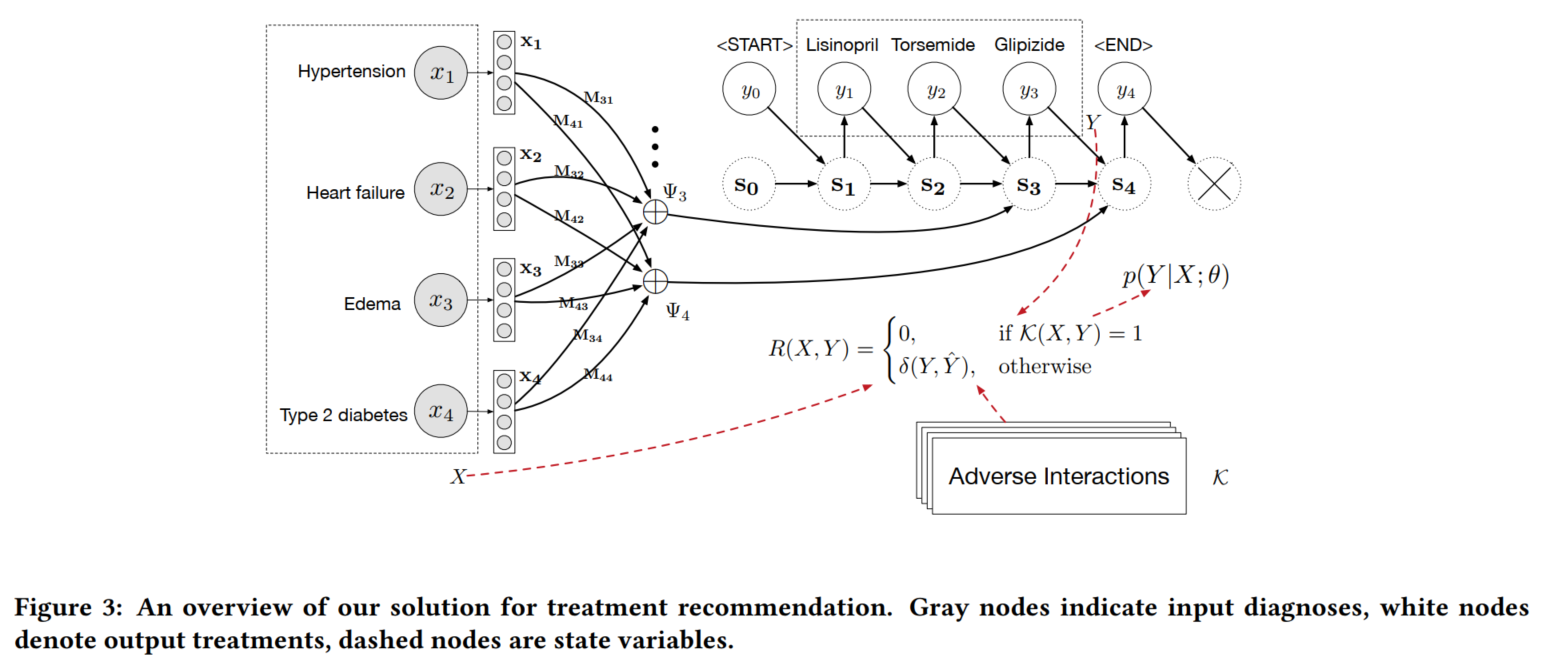
模型输入是疾病名称的集合,映射到响应的embedding ,然后通过一个注意力机制,得到这些疾病向量对应的药物向量,再结合RNN模型中的当前状态和上一个药物名称,生成当前状态向量,进而得到当前的输出药品。
模型训练时,由于病人实际使用的药物是一个集合,不是一个序列,因此需要指定一种排序方式,比如最流行的药品放前面、最罕见的药品放前面、按药品名称排序、随机排序等方法。
预测时用K=2的beam search来得到输出。
3.3 基于强化学习的fine-tune
Basic LEAP模型可以学到疾病和药品之间的对应关系,但无法学到药品之间的互斥关系;模型生成的药品序列也不够完整。
本文提出利用额外的药品-药品互斥、药品-疾病互斥信息来进一步指导模型的训练。
简单来说,就是如果模型输出序列包含上述互斥对,就把模型Reward置零,否则,模型Reward就是输出序列和groud truth之间的Jaccard相似度。
这样的模型设计同时解决了上面提到的两个问题:模型包含互斥信息直接白给,如果输出序列不够完整也不能得到高的Reward。
4. 实验
4.1 数据集
- MIMIC-3:公开。包含6,700疾病,4,000药物,涵盖11年,50,000次医疗记录
- Sutter:私有。包含8,000疾病,7,500药物,涵盖18年,2,400,000医疗记录。
sutter中的药物使用GPI一级和三级编码系统,MIMIC-3中的药物使用NDC编码系统,但被转换为GPI一级和三级编码。
训练集、验证集、测试集按7:1:2划分,应该是按病人划分,没有考虑根据病人的历史诊疗记录做进一步推荐的场景。
4.2 baselines
- Rule-based:使用一个药物-疾病映射数据集来推荐药物
- K-Most frequent:选择与该疾病相关的K个最相关的药物。Sutter和MIMIC-3上分别设K为1和3
- Softmax MLP:3层神经网络,阈值等超参做grid-search
- Classifier Chains:分类器链,把前面的分类结果作为后面的分类器的输入。输入信息使用multi-hot编码,使用SVM作为分类器
- LEAP:本文提出的基于RNN、强化学习和额外药物关系数据库的算法。基于Theano实现(开源)、使用ADAM优化器。
4.3 实验结果
实验分为定量实验和定性实验,分别验证推荐的准确度和完整性、安全性等。
4.3.1 定量实验
使用Jaccard相似度来衡量推荐结果与ground truth的相似性:
- 实验结果如下。当分类级别比较多(3)时,药物推荐难度升高,性能相对较低。
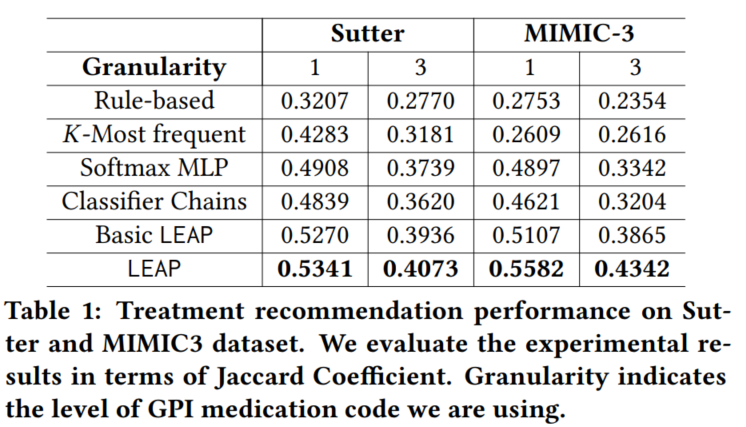
论文argue了AUC等传统评价指标对于此任务并不合适——我们不仅需要把相关药物排到前面,还需要避免药物之间以及药物和其他疾病之间的互斥性。
4.3.2 label输入顺序
训练的时候,ground truth要一个一个输入进去,顺序有怎样的影响:
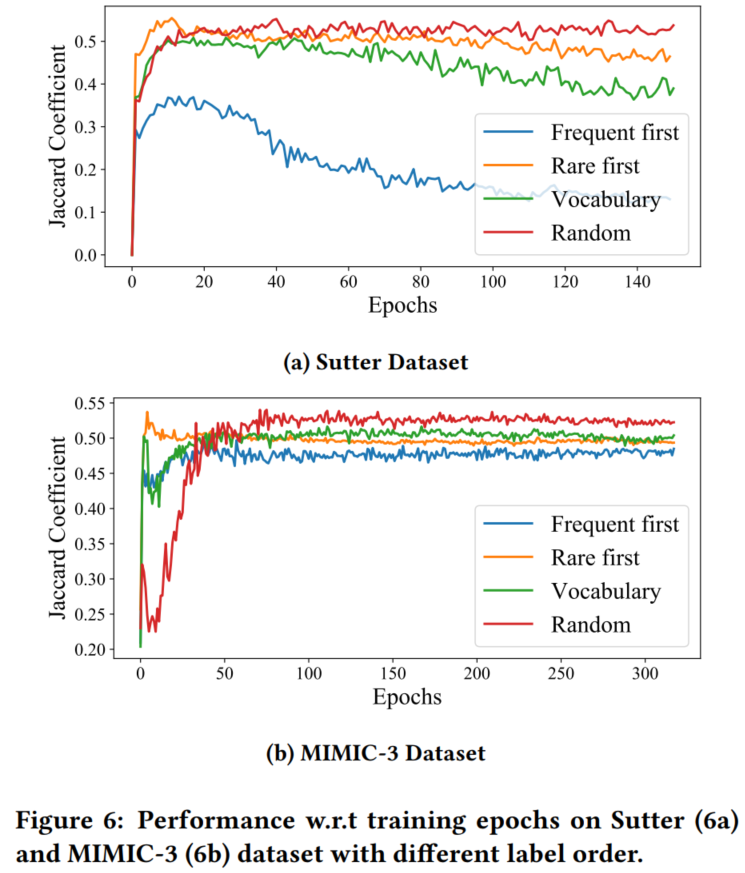
- 随机输入效果最好,优先输入流行药物效果最差。
4.3.3 去除药物相互作用的效果
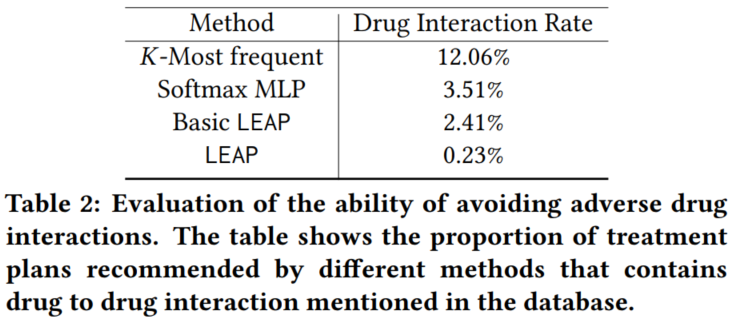
4.3.4 定性分析
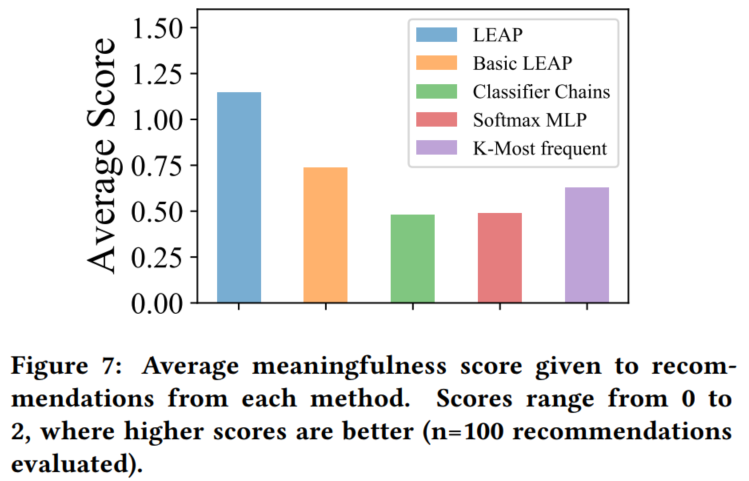
邀请专家,对100个随机诊断对应的推荐结果进行评分。
- 2分:解决所有疾病且没有药物相互作用
- 1分:解决50%以上的疾病且没有药物相互作用
- 0分:解决50%以下的疾病或者有药物相互作用
结果:
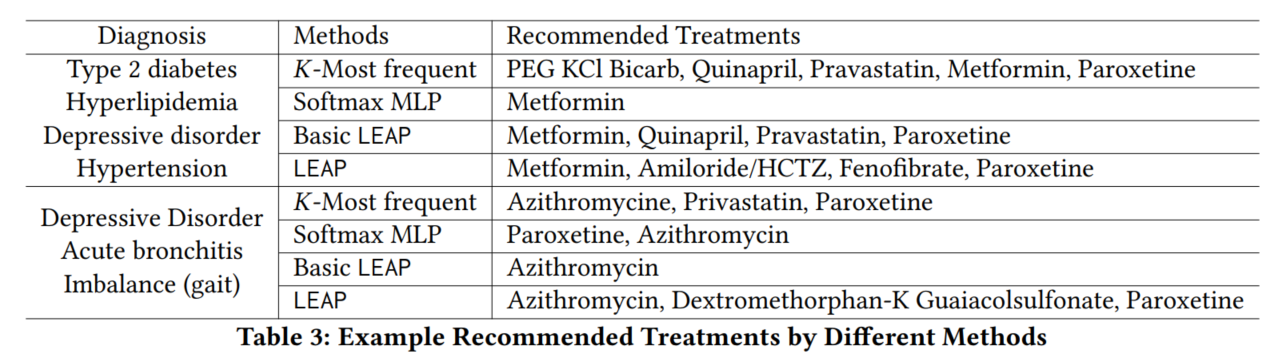
4.3.5 case study
两个病人的诊断,以及各种方法得到的推荐结果对比:
本文来自博客园,作者:赵子豪,中国科学技术大学LDS实验室博士在读
转载请注明原文链接:https://www.cnblogs.com/zihaojun/p/16118864.html
原创不易,如果感觉不错,希望给个推荐!您的支持是我写作的最大动力!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 上周热点回顾(3.3-3.9)
· AI 智能体引爆开源社区「GitHub 热点速览」
· 写一个简单的SQL生成工具