


【论文笔记】用反事实推断方法缓解标题党内容对推荐系统的影响 Click can be Cheating: Counterfactual Recommendation for Mitigating Clickbait Issue
Click can be Cheating: Counterfactual Recommendation for Mitigating Clickbait Issue
Authors: 王文杰,冯福利,何向南,张含望,蔡达成
SIGIR'21 新加坡国立大学,中国科学技术大学,南洋理工大学
论文链接:https://dl.acm.org/doi/pdf/10.1145/3404835.3462962
本文链接:https://www.cnblogs.com/zihaojun/p/15713705.html
0. 总结
这篇文章在不引入用户反馈信息的情况下,利用物品的外观特征(exposure feature)和内容特征(content feature),用反事实推断的方法,去除物品外观特征对推荐结果的直接影响,解决推荐系统中“标题党”的问题。
1. 问题背景
在推荐系统的训练数据中,通常将用户点击过的物品作为正样本进行训练。但是,用户点击一个物品不一定是因为用户喜欢这个物品,也可能是因为物品的外观很吸引人,但是内容很差。这种现象称为Clickbait Issue——引诱点击问题。
- 例如,在视频推荐场景下,用户点击一个视频,可能只是因为视频的封面和标题做的很好,但点进去可能并不喜欢看。
- 在文章/新闻推荐场景下也是如此,很多标题党文章可以获得很多点击,但用户对这种文章是深恶痛绝的。
Clickbait Issue会导致用户对推荐系统的信任度下降,也会导致低质量的标题党信息在系统中泛滥,产生劣币驱逐良币的效果和马太效应。
因此,设计和训练推荐模型时,不能只追求点击率优化,而应该追求更高的用户满意度,避免陷入“推荐标题党内容-标题党获得更多点击-推荐更多标题党内容”的恶性循环中。
2. 研究目标
利用物品的外观信息和内容信息,区分用户的点击是因为被标题/封面吸引,还是真的喜欢物品的内涵。
3. 方法
3.1 符号和概念
数据集包含历史点击数据,其中,分别表示没有/有点击交互。物品特征包括暴露信息(Exposure features)和内容信息(Content features),,暴露信息(e)在用户点击之前就能看到,比如标题和封面图;内容信息(t)在点击之后才能看到,例如文章内容、视频内容或物品详情等。
推荐模型预测结果,优化目标为:
Clickbait Issue:如果推荐系统给出的推荐列表中,把标题很吸引人,但是内容很差的物品排在标题不太吸引人,但是内容比较好的物品之前,则认为发生了Clickbait Issue。
Causal effect:因果效应分解,参见【因果推断】中介因果效应分解 汇总与理解(为了读懂这个分解方法,花了很多时间来研究,才写成此文)
- 总体因果效应:包含直接路径和间接路径的因果效应。
- 直接因果效应:通过直接路径产生的因果效应。
- 间接因果效应:通过中介节点产生的因果效应。
3.2 因果推荐模型
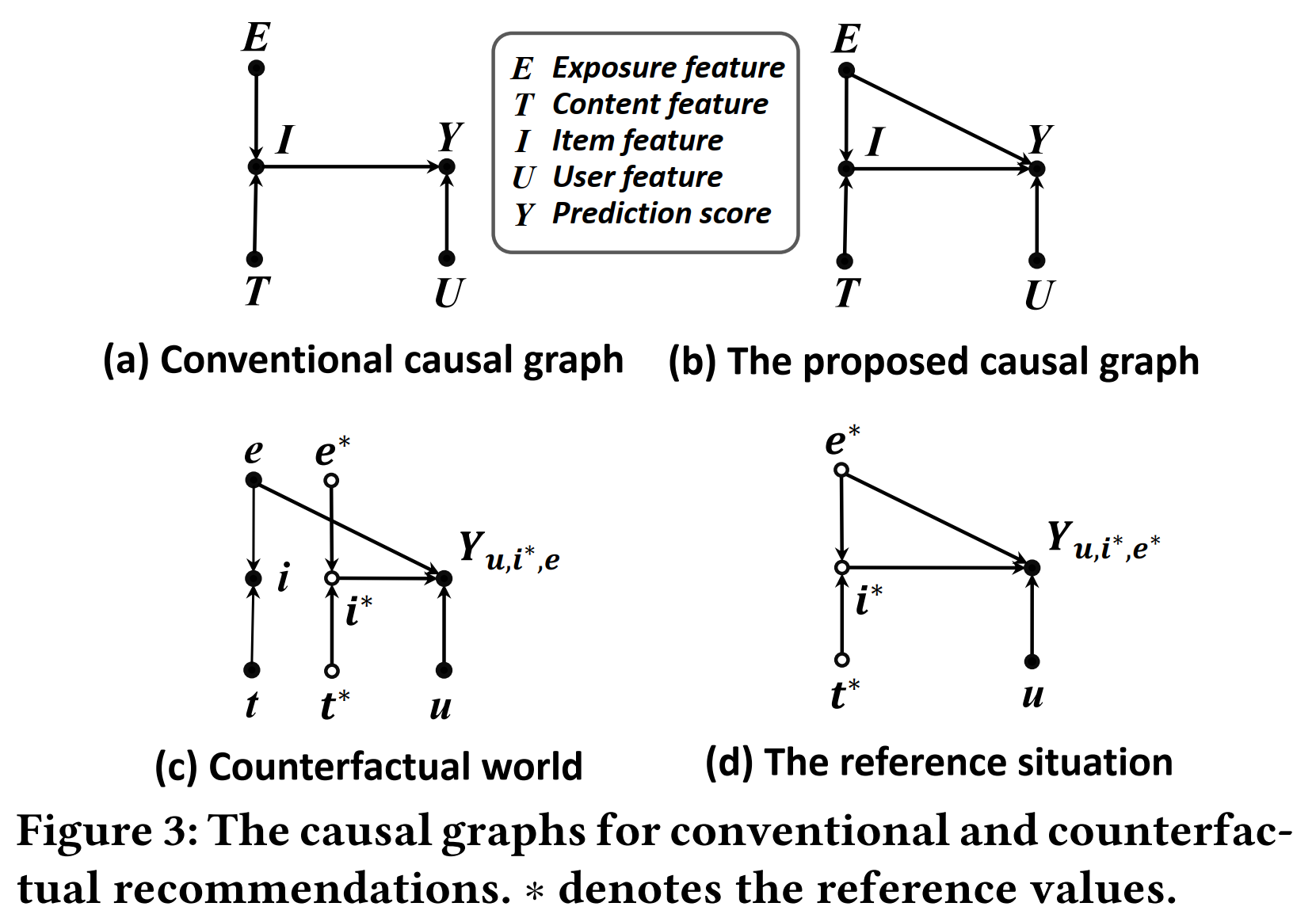
如图3(a),在传统的基于特征的推荐模型中,会将物品特征(E, T)都作为输入,通过MLP等模型,得到item的表示(I)。
但是用户可能只是被标题等信息吸引而点击一个物品,因此,本文提出,建模曝光特征(E)对点击(Y)的直接因果效应,如图3(b)。
Mitigating Clickbait Issue
- 为了解决推荐结果的Clickbait Issue,需要将这条路径的影响去掉。我们希望去除的是E对Y自然直接效应,保留E对Y的自然间接效应和交互效应,即保留总体间接效应TIE,因此,不能直接对这条路径做干预,否则就会去除掉总体直接效应,只剩自然间接效应NIE:
本文希望得到的总体间接效应:
- 具体请参考博文【论文笔记】Direct and Indirect Effects、【因果推断】中介因果效应分解 汇总与理解
- 从因果图的角度来理解,和的因果图中,这条边是一样的(都是e),因此的直接影响可以被减掉,还剩下的影响。
- 直观理解,如果一个物品是靠标题党来吸引流量的,则这个物品在反事实世界中的点击率()会很高,从而在反事实推荐模型中被排到后面去。
3.3 模型设计
在因果图中,影响点击概率Y的变量有三个(e,u,i),本文分别建立了u-e模型和u-i模型,分别捕捉物品曝光特征和总体特征对用户点击概率的影响:
模型训练:
模型预测:
是用户u对所有物品特征的平均兴趣:
4. 实验
4.1 实验结果
使用了两个有物品特征和用户反馈的数据集,统计信息见下表:
对于每个用户,将正样本按8:1:1的比例随机划分训练集、验证集和测试集,其中测试集中只包含用户给出正反馈的物品。
baseline:
- NT:(Normal Training)使用正常的训练数据,即使用曝光特征+内容特征作为模型输入,使用点击数据(而不是只使用正反馈数据)作为正样本参与训练。
- CFT:(Content Feature Training)只使用内容特征来训练模型,同样使用点击数据作为正样本参与训练。
- IPW:训练阶段使用Inverse Propensity Score的方法来做debias[27,28]。
以下三个baseline是利用了用户反馈数据的:
- CT:(Clean Training)只使用正反馈数据作为正样本来训练。
- NR:(Negative feedback Re-weighting)将点击但不喜欢的样本,与未点击的样本一起作为负样本进行训练。
- RR:(Re-Rank)在NT的基础上,对每个用户前20的推荐物品,结合物品的点赞率进行重排序。
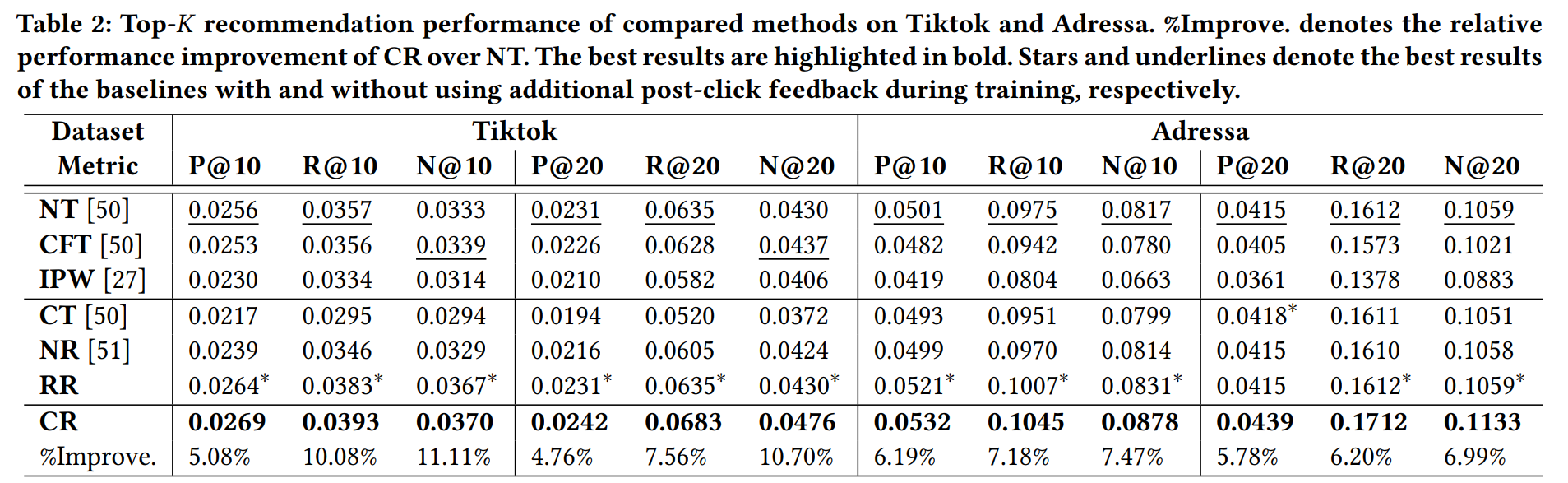
实验表明,本文提出的方法CR(Counterfactual Recommendation)的性能高于所有baseline。
4.2 性能比较
- CFT性能比NT要差,说明简单地去除曝光特征是不行的。IPW性能也很差,这可能与本文的设定下,propensity score很难估计有关。
- CR的性能高于NT,说明利用用户反馈数据的有效性,更能捕捉用户对内容的兴趣。但CT和NR的性能比较差,这可能是因为直接抛弃用户点击但未给出正反馈的那些数据,会使得数据量大大减少。
一些想法
- 有些物品可能难以收集或者定义曝光特征,此时就无法应用此方法
- 本文的模型设计是比较反直觉的,不是直接在预测时把包含e的项去掉,而是减去一项。这也是因果推断理论的作用——给出不怎么符合直觉但是更合理更有效的模型设计方法。
- 这是2021年的最后一个晚上发表的今年最后一篇随笔,2021年我发生了很大的变化,希望在即将到来的2022年,能尽快达到自己满意的学术水平,顺利开启博士生涯,抓紧在校园的时光,努力学本领。加油加油!
进一步阅读
[45] Tyler J VanderWeele. 2013. A three-way decomposition of a total effect into direct, indirect, and interactive effects. Epidemiology (Cambridge, Mass.) 24, 2 (2013), 224
[30] Dugang Liu, Pengxiang Cheng, Zhenhua Dong, Xiuqiang He, Weike Pan, and Zhong Ming. 2020. A General Knowledge Distillation Framework for Counterfactual Recommendation via Uniform Data. In SIGIR. ACM, 831–840
[35] Yulei Niu, Kaihua Tang, Hanwang Zhang, Zhiwu Lu, Xian-Sheng Hua, and JiRong Wen. 2020. Counterfactual VQA: A Cause-Effect Look at Language Bias. In arXiv:2006.04315
[37] Judea Pearl. 2001. Direct and indirect effects. In UAI. Morgan Kaufmann Publishers Inc, 411–420.
[43] Kaihua Tang, Jianqiang Huang, and Hanwang Zhang. 2020. Long-Tailed Classification by Keeping the Good and Removing the Bad Momentum Causal Effect. In NeurIPS.
[44] Kaihua Tang, Yulei Niu, Jianqiang Huang, Jiaxin Shi, and Hanwang Zhang. 2020. Unbiased scene graph generation from biased training. In arXiv:2002.11949
[27] Dawen Liang, Laurent Charlin, and David M Blei. 2016. Causal inference for recommendation. In UAI. AUAI.
[28] Dawen Liang, Laurent Charlin, James McInerney, and David M Blei. 2016. Modeling user exposure in recommendation. In WWW. ACM, 951–961
[32] Hongyu Lu, Min Zhang, and Shaoping Ma. 2018. Between Clicks and Satisfaction: Study on Multi-Phase User Preferences and Satisfaction for Online News Reading. In SIGIR. ACM, 435–444.
[52] Hong Wen, Jing Zhang, Yuan Wang, Fuyu Lv, Wentian Bao, Quan Lin, and Keping Yang. 2020. Entire space multi-task modeling via post-click behavior decomposition for conversion rate prediction. In SIGIR. ACM, 2377–2386
本文来自博客园,作者:赵子豪,中国科学技术大学LDS实验室博士在读
转载请注明原文链接:https://www.cnblogs.com/zihaojun/p/15713705.html
原创不易,如果感觉不错,希望给个推荐!您的支持是我写作的最大动力!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· winform 绘制太阳,地球,月球 运作规律
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 上周热点回顾(3.3-3.9)
· AI 智能体引爆开源社区「GitHub 热点速览」
· 写一个简单的SQL生成工具