Modeling User Exposure in Recommendation
【论文作者】Dawen Liang, David M. Blei, etc.
WWW’16 Columbia University
0. 总结
这篇文章构建了曝光概率这个隐变量,用EM算法进行参数优化,并提出了基于流行度和基于内容的两种曝光概率参数模型。实验表明,提出的方法性能得到了较大提升。
1.研究目标
通过建模曝光概率,去除推荐系统中的Exposure bias。
2.问题背景
在推荐系统场景下,显示反馈数据可以同时获得用户的正负反馈信息,但获取难度较大,相关数据较少。在隐式反馈数据中,所有未发生交互的user-item pairs都被视为负样本,但是用户没有与一个物品发生交互,有可能是因为用户真的不喜欢,也可能是因为用户不知道这个物品,这就是推荐系统当中的exposure bias。
3. 方法
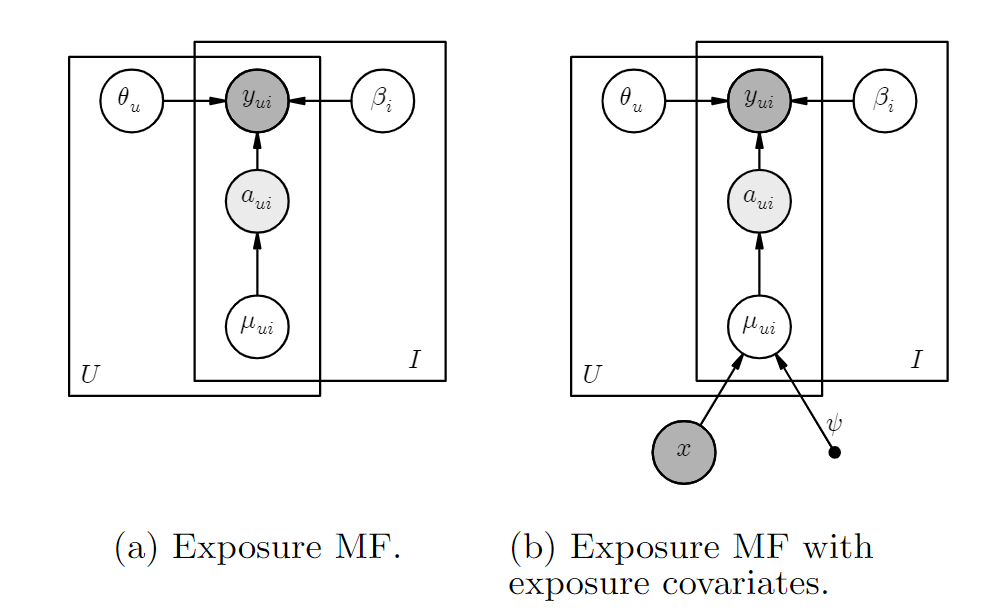
3.1 模型描述
本文将曝光与否建模为隐变量aui,aui服从参数为μui的伯努利分布(0-1分布)。
u和i的embedding的各维度独立同分布,分别服从一个均值为0,方差为λ−1θ的正态分布。
当aui=1时,yui服从均值为θ⊤uβi,方差为λ−1y的正态分布。
当aui=0时,表明i没有被u观测到,交互概率yui趋近于0。
θu∼N(0,λ−1θIK)βi∼N(0,λ−1βIK)aui∼Bernoulli(μui)yui|aui=1∼N(θ⊤uβi,λ−1y)yui|aui=0∼δ0,
基于上述概率分布,可以推导出aui和yui的联合条件概率分布为
logp(aui,yui|μui,θu,βi,λ−1y)=log[p(aui|μui,θu,βi,λ−1y)∗p(yui|aui,μui,θu,βi,λ−1y)]=logp(aui|μui)+logp(yui|aui,μui,θu,βi,λ−1y)=logp(aui|μui)+I[aui=1]logp(yui|aui=1,μui,θu,βi,λ−1y)+I[aui=0]logp(yui|aui=0,μui,θu,βi,λ−1y)=logBernoulli(aui|μui)+auilogN(yui|θ⊤uβi,λ−1y)+(1−aui)logI[yui=0]
当yui=1时,aui=1,因此我们只考虑yui=0的情况。
当yui=0时,若θ⊤uβi较大,则N(yui=0|θ⊤uβi,λ−1y)较小,使得p(aui=1,yui=0)较小,迫使我们相信aui=0。直观上讲,若一个物品符合用户兴趣(θ⊤uβi较大),且没有发生交互(yui=0),则用户很可能是因为没有看到这个物品(aui=0)。
3.2 对曝光概率的建模
- per item μi:直接用物品流行度作为曝光参数μui的初始值,只使用点击数据,不使用额外信息,μi∼Beta(α1,α2)。
- 基于上下文的建模:首先基于提取物品的特征向量xi,并为每个user学习一个表示ψu,则μui=σ(ψ⊤uxi)。
3.3 参数学习
由于模型中含有因变量aui,使用EM算法来学习模型参数。
- E-step:对于yui=1的交互,aui=1,不需要学习。对于yui=0的交互:
E[aui∣θu,βi,μui,yui=0]=p(aui=1,yui=0∣θu,βi,μui)p(aui=1,yui=0∣θu,βi,μui)+p(aui=0,yui=0∣θu,βi,μui)=p(aui=1)⋅p(yui=0∣θu,βi,aui=1)p(aui=1)⋅p(yui=0∣θu,βi,aui=1)+p(aui=0∣μui)=μui⋅N(0∣θ⊤uβi,λ−1y)μui⋅N(0∣θ⊤uβi,λ−1y)+(1−μui)
为简化表达,令pui=E[aui∣θu,βi,μui,yui=0],则:
θu←(λy∑ipuiβiβ⊤i+λθIK)−1(∑iλypuiyuiβi)βi←(λy∑upuiθuθ⊤u+λβIK)−1(∑uλypuiyuiθu)
曝光先验概率μui的优化:
-
per-item μui
由于μi服从beta分布,即μi∼Beta(α1+∑upui,α2+U−∑upui),则
μi←α1+∑upui−1α1+α2+U−2
-
基于上下文的先验概率μui
也就是用E-step生成的pui来监督μui
ψnewu←ψu+η∇ψuL
∇ψuL=1I∑i(pui−σ(ψ⊤uxi))xi
实现时,对每个user,不计算与所有item的交互,而是随机采样一些item,以降低计算复杂度。
3.4 预测模型
预测时,可以用^yui=μui⋅θ⊤uβi,也可以直接用^yui=θ⊤uβi。在本文的实验中,如果采用per-item exposure model,则后者好;如果曝光先验概率模型中加入了item的物品信息,则前者好。
可能是因为加入了item信息的曝光模型对曝光概率的预测更准确,因此在预测时加入μui效果更好。
4. 实验
4.1 数据集
TPS Mendeley Gowalla ArXiv # of users 221,83045,29357,62937,893 # of items 22,78176,23747,19844,715 # interactions 14.0M2.4M2.3M2.5M% interactions 0.29%0.07%0.09%0.15%
4.2 实验结果
TPS Mendeley Gowalla ArXiv WMF ExpoMF WMF ExpoMF WMF ExpoMF WMF ExpoMF Recall@20 0.1950.2010.1280.1390.1220.1180.1430.147 Recall@50 0.2930.2860.2100.2210.1920.1860.2370.236 NDCG@100 0.2550.2630.1490.1590.1180.1160.1540.157 MAP@100 0.0920.1090.0480.0550.0440.0430.0510.054
4.3模型分析
从结果上,对于未点击的物品,如果用户感兴趣的概率较高,则该物品被曝光的概率应该比较低。
从训练过程上看,模型中的曝光变量使得MF模型能够专注于曝光概率高的user-item pairs。
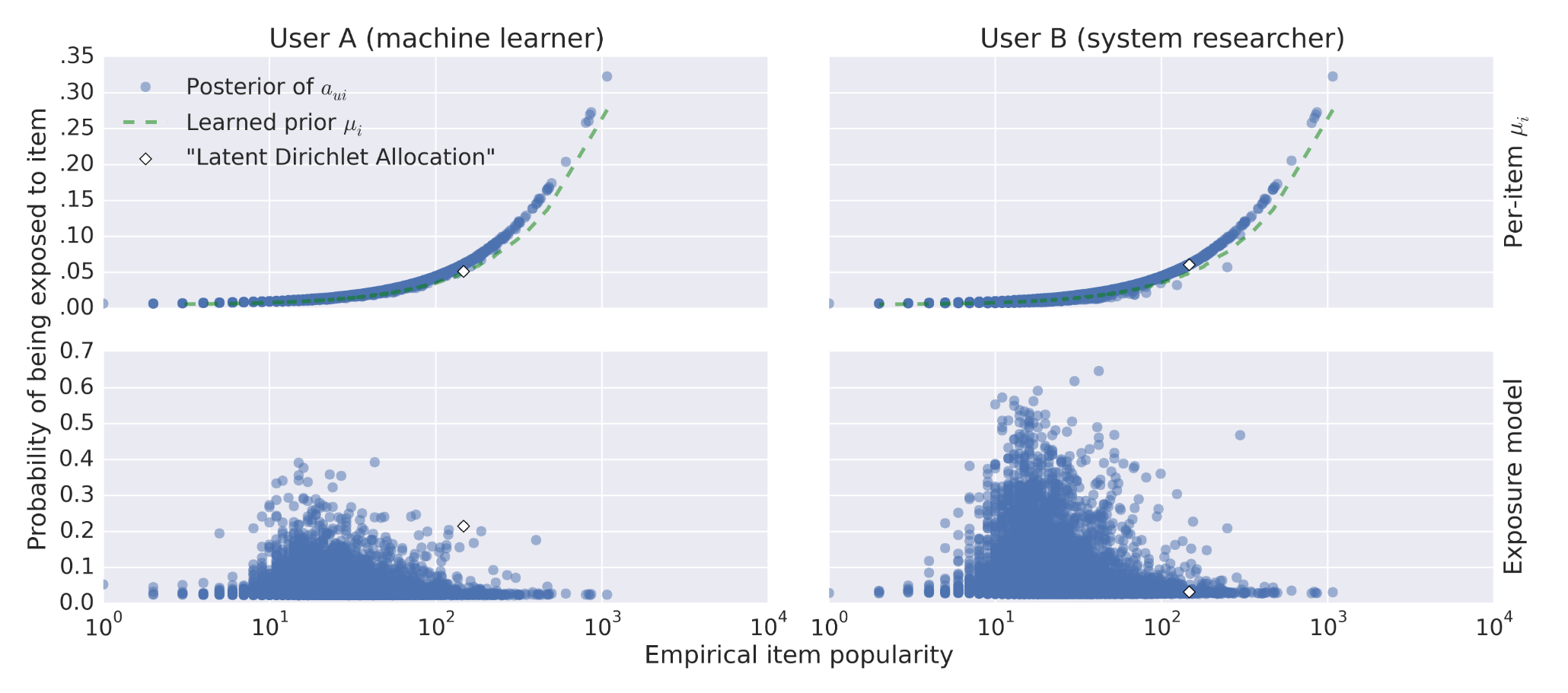
图中,横坐标表示物品流行度,红色虚线表示学到的per-item先验曝光概率,蓝色点表示后验曝光概率。画出的点都是没有发生过交互的。
在User A的图中,方框框出的点表示跟用户兴趣比较相符的物品,但是没有发生交互,模型可以将对应的曝光概率降低。也就是说,用户更可能是因为没有看到这个物品而没有发生交互,而不是因为不感兴趣。
在User B的图中,方框框出了流行度最高的两个物品(流行度非常接近),但是其中一个物品更接近用户兴趣,模型得出的响应曝光概率明显低于另一个物品。
4.4 加入内容信息的曝光模型
曝光参数模型:
μui=σ(ψ⊤uxi+γu)
物品特征提取方式:
- Mendeley:共K个文章类别,使用LDA模型,通过内容信息,得到文章属于每个类别的概率,从而为每个item生成一个特征向量。
- Gowalla:使用K-means得到K个聚类中心,计算每个位置与K个中心的距离,得到一个特征向量。
训练结果(第二行的两个图):
加入内容信息之后,曝光概率与流行度的相关性大大降低,模型性能也得到了较大提升。
WMF ExpoMF Location ExpoMF Recall@20 0.1220.1180.129 Recall@50 0.1920.1860.199 NDCG@100 0.1180.1160.125 MAP@100 0.0440.0430.048
疑问
3.3 M-step不理解






【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· winform 绘制太阳,地球,月球 运作规律
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 上周热点回顾(3.3-3.9)
· AI 智能体引爆开源社区「GitHub 热点速览」
· 写一个简单的SQL生成工具