


随笔分类 - 论文笔记
摘要: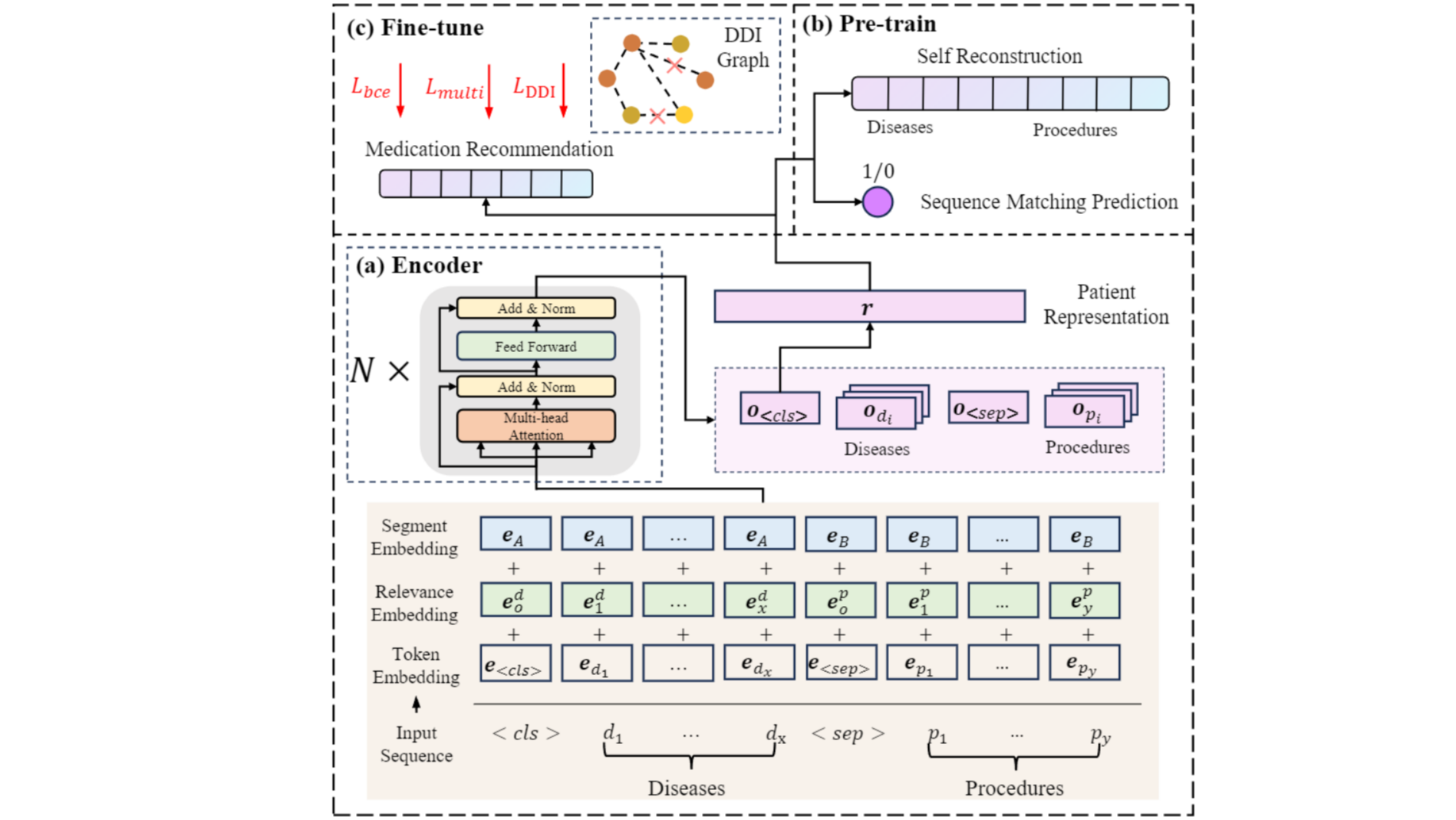 在本文中,我们针对药物推荐模型对罕见病患者推荐精度低的问题,提出了一种新的基于预训练-微调的药物推荐模型框架**RAREMed**,并提出了两个针对性的预训练任务,来提高模型对患者病情,尤其是罕见病患者病情的表示学习能力,帮助药物推荐模型提高对罕见病患者的推荐准确度,从而提升药物推荐模型的公平性。我们在两个常用的公开数据集上的实验结果显示出我们的方法在药物推荐模型的准确度和公平性方面有着显著优势。
阅读全文
在本文中,我们针对药物推荐模型对罕见病患者推荐精度低的问题,提出了一种新的基于预训练-微调的药物推荐模型框架**RAREMed**,并提出了两个针对性的预训练任务,来提高模型对患者病情,尤其是罕见病患者病情的表示学习能力,帮助药物推荐模型提高对罕见病患者的推荐准确度,从而提升药物推荐模型的公平性。我们在两个常用的公开数据集上的实验结果显示出我们的方法在药物推荐模型的准确度和公平性方面有着显著优势。
阅读全文
在本文中,我们针对药物推荐模型对罕见病患者推荐精度低的问题,提出了一种新的基于预训练-微调的药物推荐模型框架**RAREMed**,并提出了两个针对性的预训练任务,来提高模型对患者病情,尤其是罕见病患者病情的表示学习能力,帮助药物推荐模型提高对罕见病患者的推荐准确度,从而提升药物推荐模型的公平性。我们在两个常用的公开数据集上的实验结果显示出我们的方法在药物推荐模型的准确度和公平性方面有着显著优势。
阅读全文
摘要:17 KDD RNN+强化学习
阅读全文
摘要:16 KDD
阅读全文
摘要:这篇文章在不引入用户反馈信息的情况下,利用物品的外观特征(exposure feature)和内容特征(content feature),用反事实推断的方法,去除物品外观特征对推荐结果的直接影响,解决推荐系统中“标题党”的问题。
阅读全文
摘要:本文用因果推断的方法研究各个国家、新冠死亡率、年龄分布之间的关系,尤其是分析了感染者年龄作为中介变量对新冠死亡率的间接影响,为政策制定提供支撑,为后续更复杂数据上的研究打下基础。
阅读全文
摘要:Judea Pearl是图灵奖得主,因果推断的奠基人之一。由于阅读的论文中涉及到反事实推断中Total Effect(TE), Natural Direct Effect(NDE), Total Indirect Effect(TIE)等概念,涉及到反事实推断方法的核心,因此前来拜读一下Pearl老爷子二十年前发表的这篇论文。本文谷歌引用1300+。
阅读全文
摘要:这篇文章通过模拟动态推荐实验,研究了受众人数不平衡、模型偏差、位置偏差、闭环反馈四种因素对推荐系统中流行度偏差的影响,认为受众人数不平衡和模型偏差是造成流行度偏差的主要因素。并提出了两种方法来去除动态场景下的popularity bias。
模拟实验设计比较新颖,但去偏方法稍显粗糙,缺乏真实数据集的实验验证。
阅读全文
摘要:这篇文章证明了在推荐系统中,将用户点击之后没有看完的物品作为负样本的一部分参与训练是有效的。
阅读全文
摘要: 本文主要研究并解决推荐系统的隐式反馈数据中**正样本**存在噪声,会损害推荐系统性能的问题。
**“伪正样本”**在推荐系统训练的初始阶段Loss普遍较高,利用这个规律,可以对“伪正样本”和真正的正样本进行区分。
本文提出了**适应性去噪训练(Adaptive Denoising Training,ADT)**策略来解决上述问题,提出了截断损失函数和加权损失函数两种Loss函数,并基于交叉熵损失,在三个数据集上,基于三种推荐模型进行了实验,实验结果表明,ADT可以有效去除“伪正样本”对模型性能的干扰。
阅读全文
本文主要研究并解决推荐系统的隐式反馈数据中**正样本**存在噪声,会损害推荐系统性能的问题。
**“伪正样本”**在推荐系统训练的初始阶段Loss普遍较高,利用这个规律,可以对“伪正样本”和真正的正样本进行区分。
本文提出了**适应性去噪训练(Adaptive Denoising Training,ADT)**策略来解决上述问题,提出了截断损失函数和加权损失函数两种Loss函数,并基于交叉熵损失,在三个数据集上,基于三种推荐模型进行了实验,实验结果表明,ADT可以有效去除“伪正样本”对模型性能的干扰。
阅读全文
本文主要研究并解决推荐系统的隐式反馈数据中**正样本**存在噪声,会损害推荐系统性能的问题。
**“伪正样本”**在推荐系统训练的初始阶段Loss普遍较高,利用这个规律,可以对“伪正样本”和真正的正样本进行区分。
本文提出了**适应性去噪训练(Adaptive Denoising Training,ADT)**策略来解决上述问题,提出了截断损失函数和加权损失函数两种Loss函数,并基于交叉熵损失,在三个数据集上,基于三种推荐模型进行了实验,实验结果表明,ADT可以有效去除“伪正样本”对模型性能的干扰。
阅读全文
摘要:这篇文章提出了一个利用社交网络信息的推荐模型SamWalker。SamWalker可以建模用户和物品之间的曝光概率,并提出用社交网络随机游走进行负采样的方式来替代曝光概率的计算,降低模型计算复杂度。此外,模型还可以利用等效的卷积神经网络来优化社交连接强度。在三个数据集上,SamWalker都取得了超过所有baseline的性能,并结合Ablation study等实验证明了模型的性能。
阅读全文
摘要:Modeling User Exposure in Recommendation 【论文作者】Dawen Liang, David M. Blei, etc. WWW’16 Columbia University 0. 总结 这篇文章构建了曝光概率这个隐变量,用EM算法进行参数优化,并提出了基于流行
阅读全文
摘要:Recommendations as Treatments: Debiasing Learning and Evaluation Authors: Tobias Schnabel, Adith Swaminathan, Ashudeep Singh, Navin Chandak, Thorsten
阅读全文
