
(自用笔记)RNN原理,Pytorch实现和使用RNN实现IMDB英文电影评价二分类
循环神经网络
记忆单元分类
RNN,GRU,LSTM
类别
单向循环,
双向循环
多层单或双向叠加
delay:n帧输入输入网络,记忆单元先更新n步,这n步的输出先不要
使得预测第一帧输出的时候不只看到了第一帧的输入(看到的上下文更宽)
优点/缺点:
优点:每个时刻的权重共享,可以处理变长序列,模型大小与序列长度无关,计算量与序列长度呈线性增长,考虑历史信息,便于流式输出
缺点:串行计算较慢,无法获取很长的历史信息
transformer计算复杂度和序列是平方关系
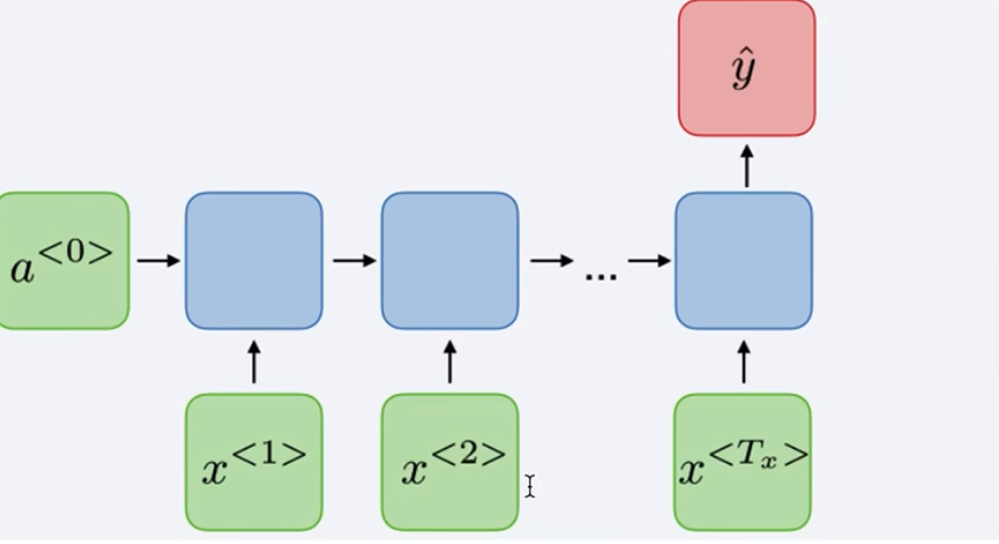
生成任务:
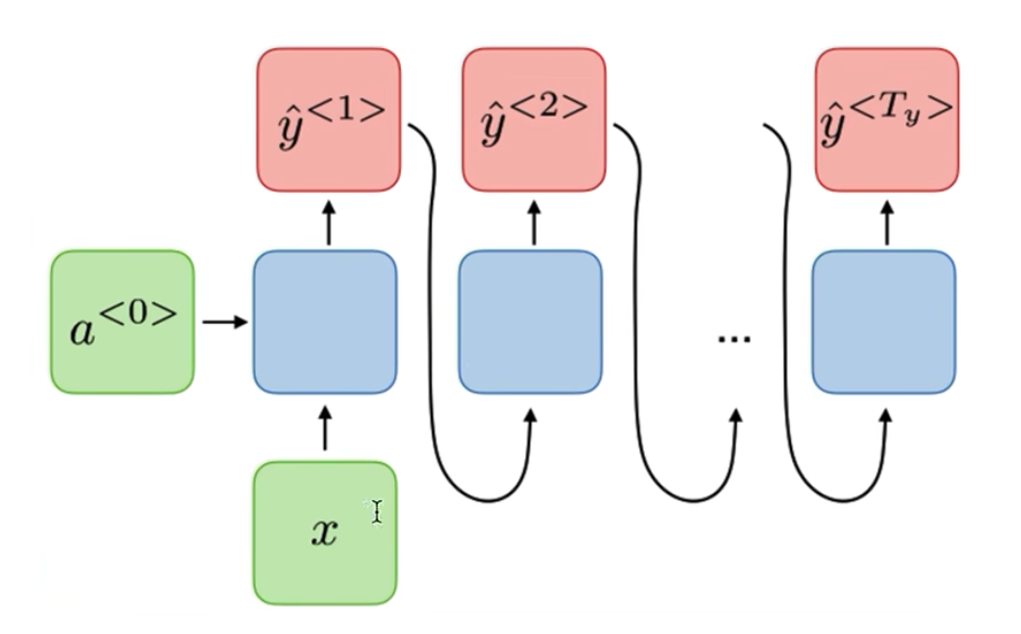
分类:
词法识别
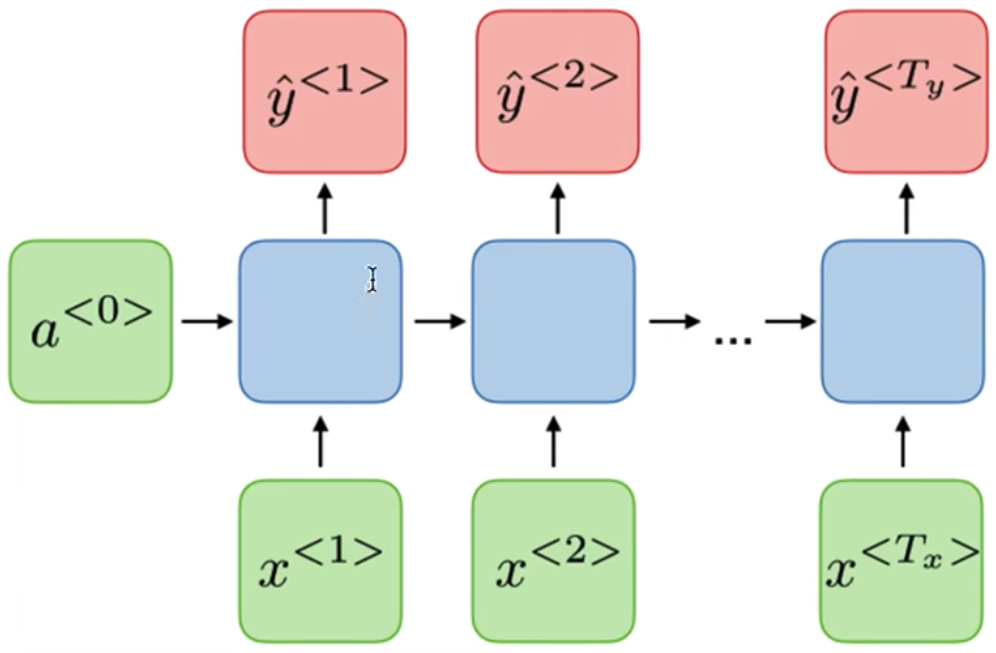
RNN(Recurrent Neural Network)
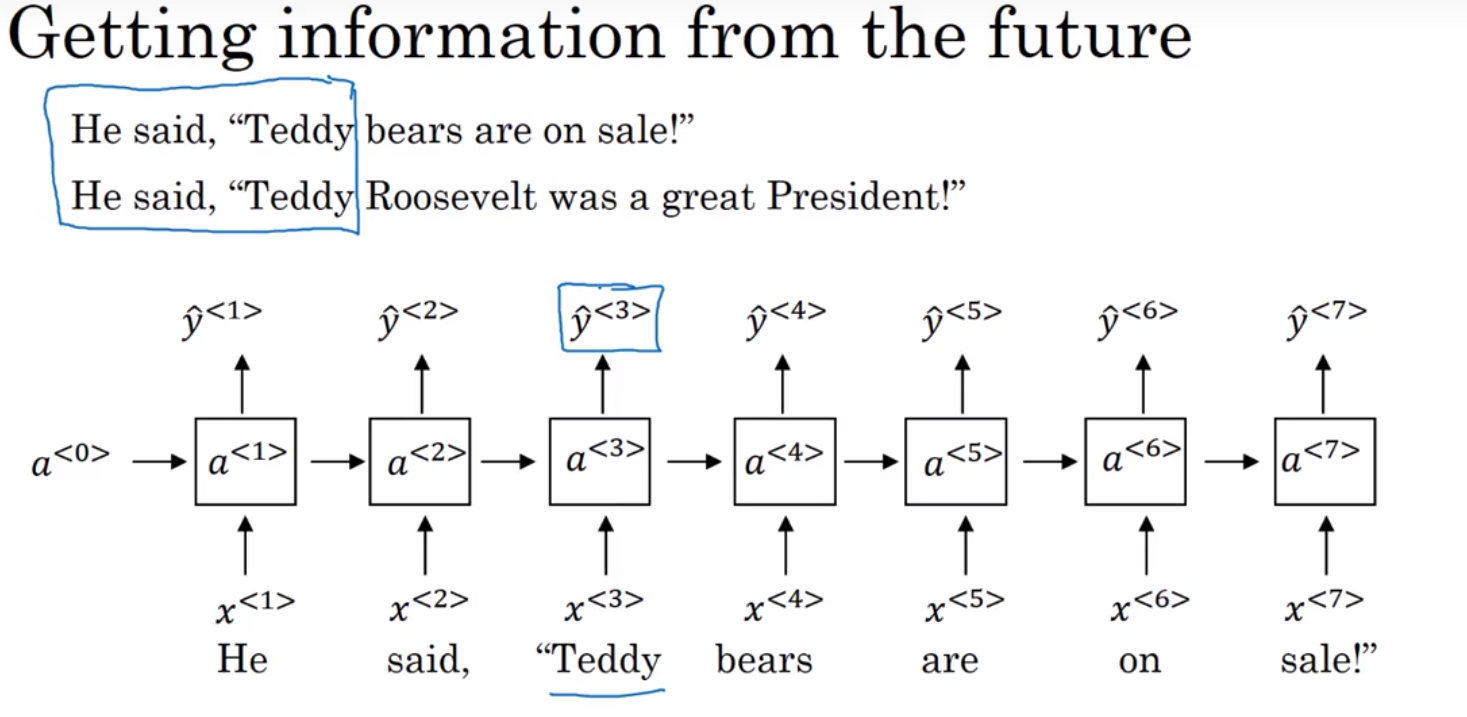
x<1>输入神经网络,输出判断这个单词是否是人名的一部分,
读到x<2>时,不仅仅使用x<2>来预测,还会使用time-step 1的信息作为输入
a<1>代表time step1的激活值
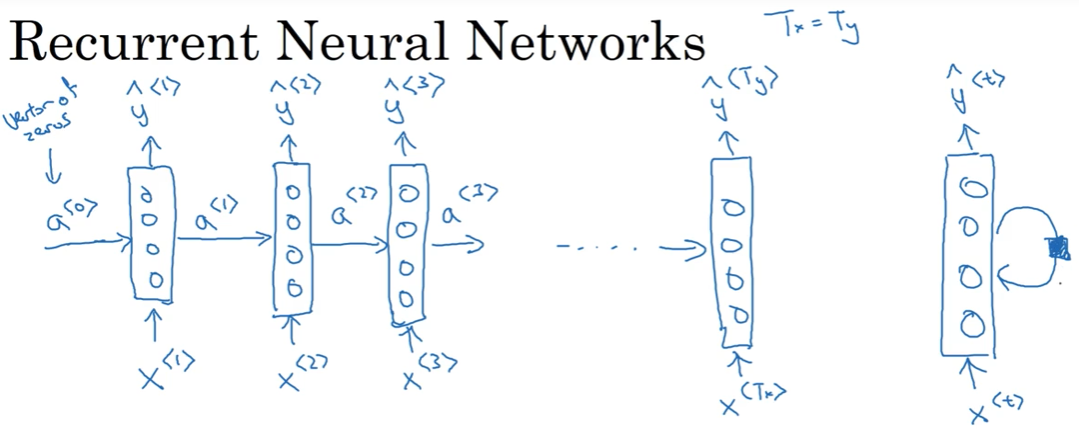
黑色块表示延迟一个time-step
RNN每个time-step的参数是共享的,数据从左到右读入
缺点:只利用了之前的信息而没有利用之后的信息
根据y hat输出选择激活函数:
比如对于ner任务,输出为0,1则可以选择sigmoid
简化符号:
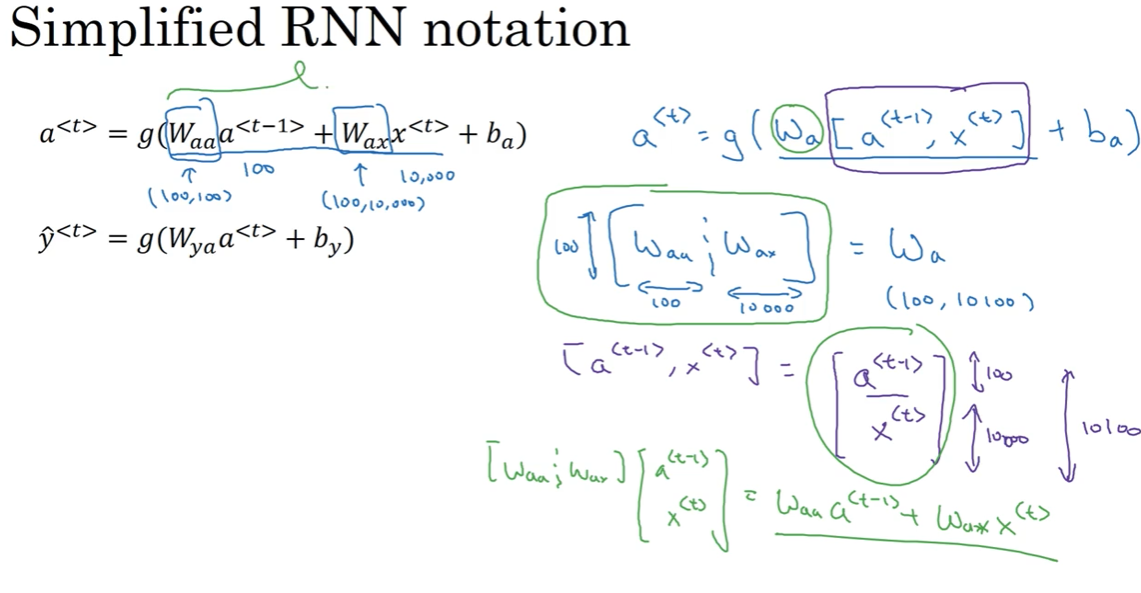
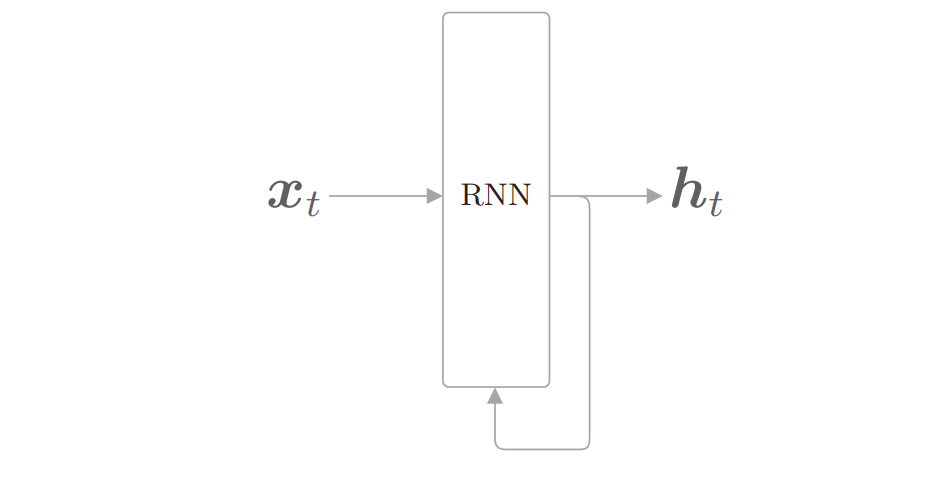
输出中的一个分叉将成为其自身的输入
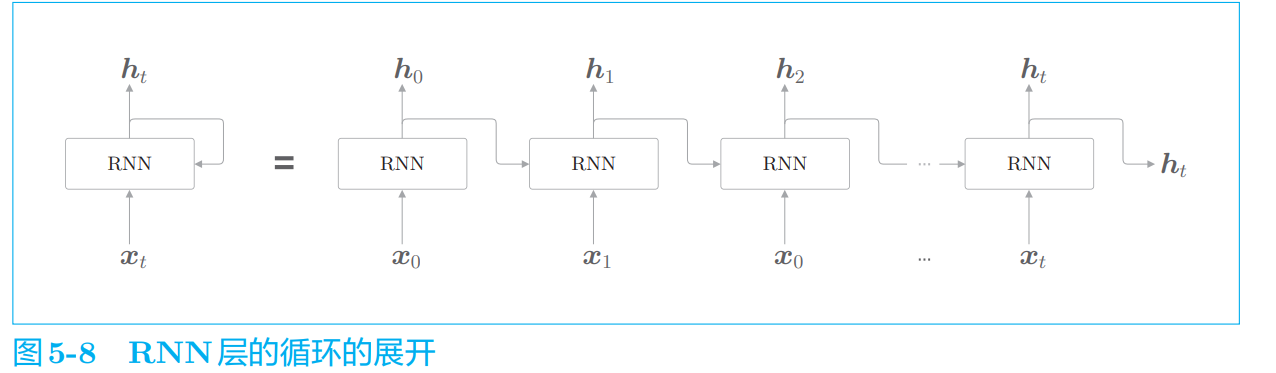
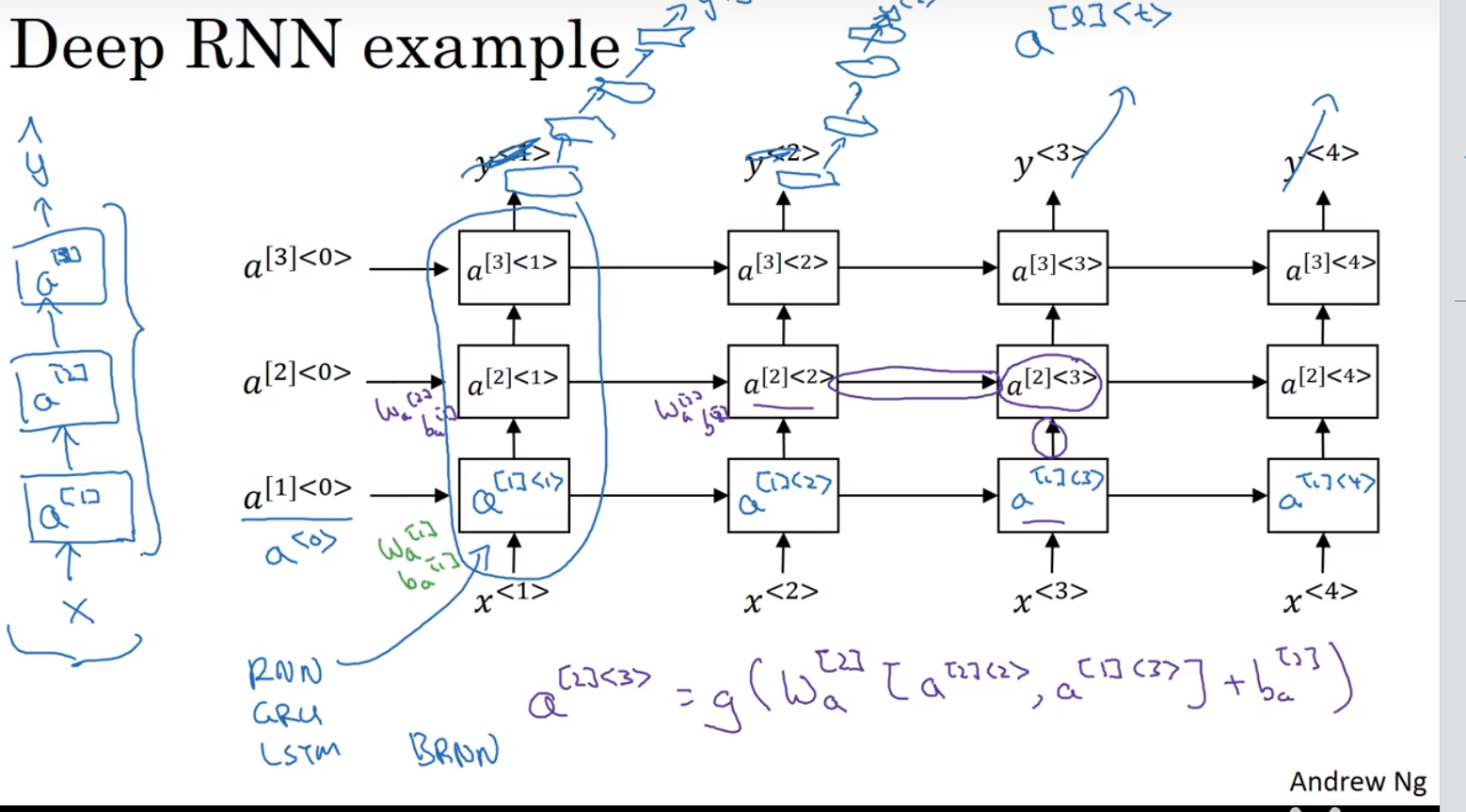
与前馈神经网络不同:多个RNN层都是同一个层
各个时刻的 RNN 层接收传给该层的输入和前一个 RNN 层的输出,然后据此计算当前时刻的输出
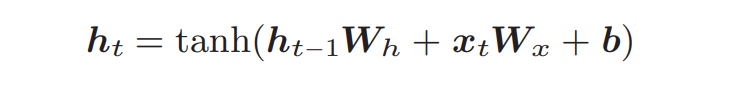
RNN的权重:
(1)输入x转化为输出h的权重Wx
(2)将前一个RNN层输出ht-1转化为当前层输出的Wh
ht−1 和 xt 都是行向量
RNN 的 h 存储“状态”,时间每前进一步(一个单位),它就以式 (5.9) 的形式被更新
Backpropagation Through Time
基于时间的反向传播
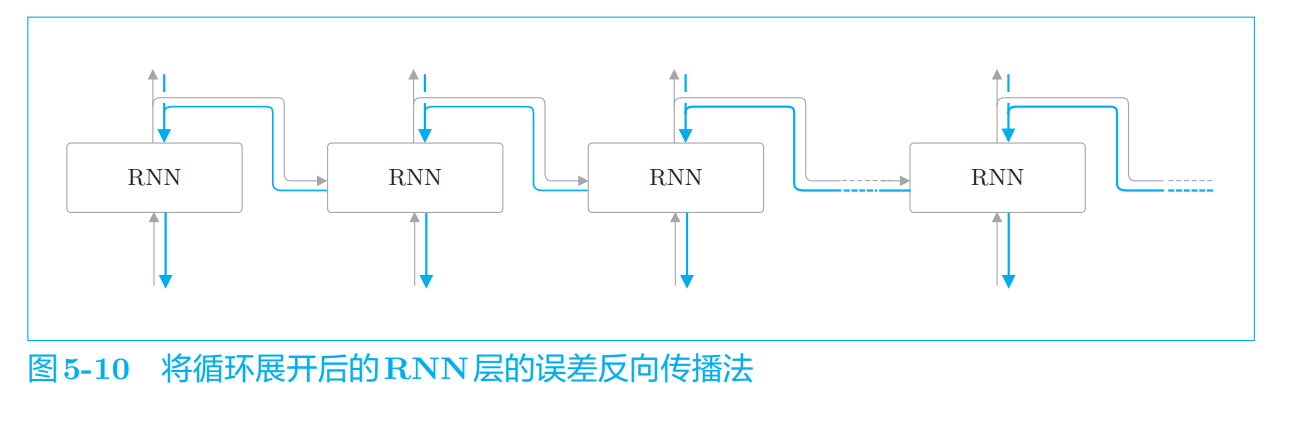
Truncated BPTT
按适当长度截断的误差反向传播法
如果序列太长,就会出现计算量或者内存使 用量方面的问题。此外,随着层变长,梯度逐渐变小,梯度将无法向前一层 传递
以各个块为单位(和其他块没有关联)完成误差反向传播法
正向传播之间是有关联的,这意味着必须按顺序输入数据
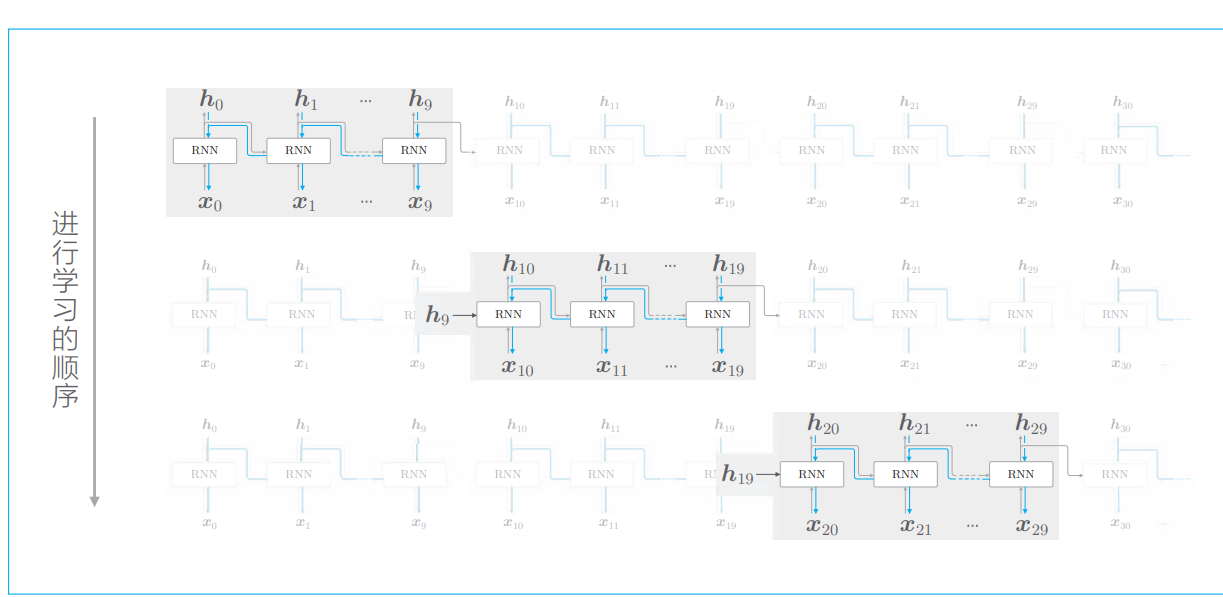
神经网络在进行 mini-batch 学习时,数据都是 随机选择的。但是,在 RNN 执行 Truncated BPTT 时,数据需 要按顺序输入
正向传播的计算需要前一个块最后的隐藏状态 h9,这样可以维 持正向传播的连接。
按顺序输入
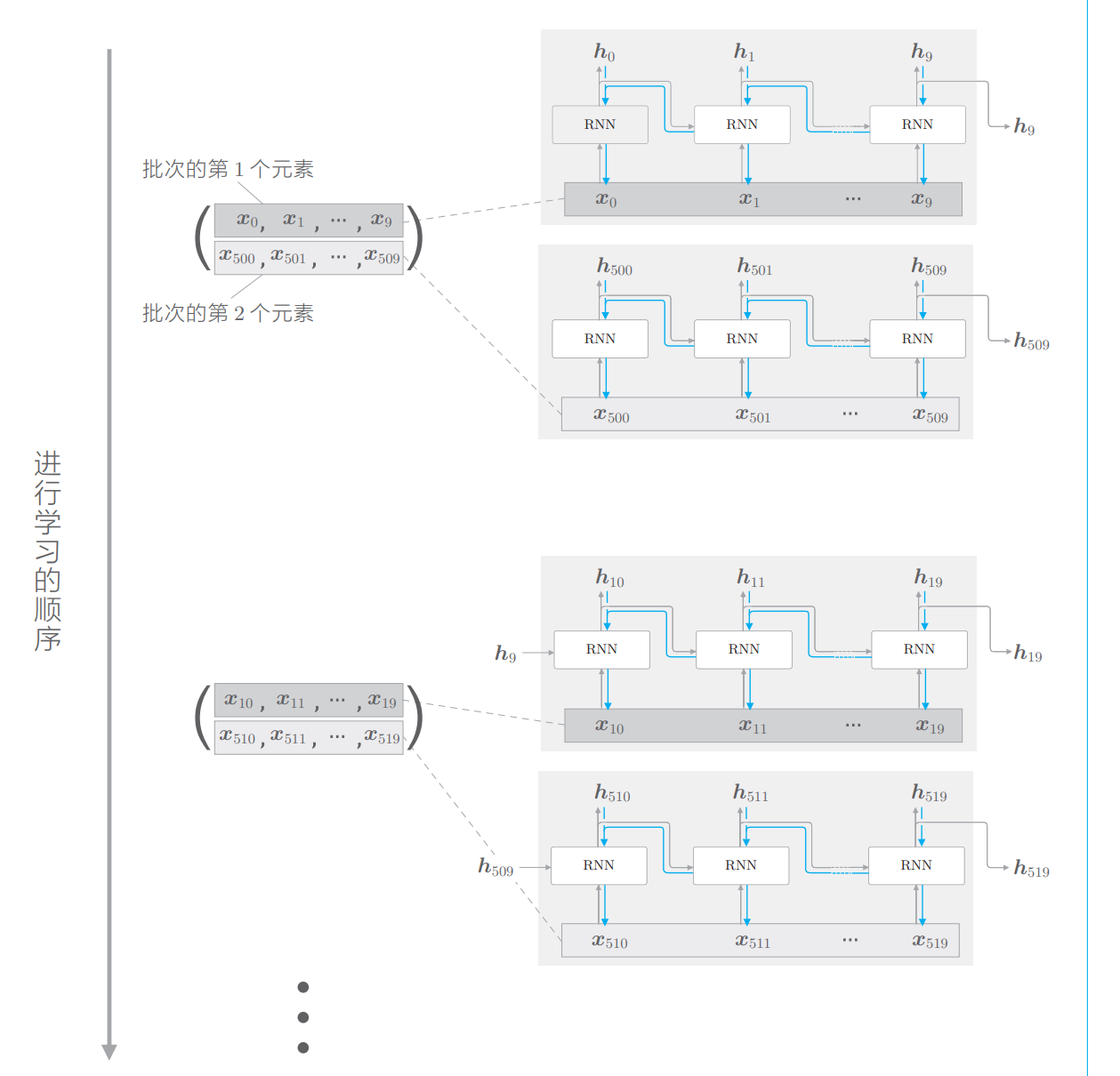
两个批次:一个批次500个时序数据,由于按长度10截断,则一个批次的元素量为50
批次的第一个元素:0-9,
第 1 笔样本数据从头开始按顺序输入,第 2 笔数据从第 500 个数据开始按顺 序输入。
一是要按顺序输入数据,二是 要平移各批次(各样本)输入数据的开始位置
实现RNN
基于RNN的神经网络:在水平方向上长度固定
在水平方向创建长度固定的网络序列
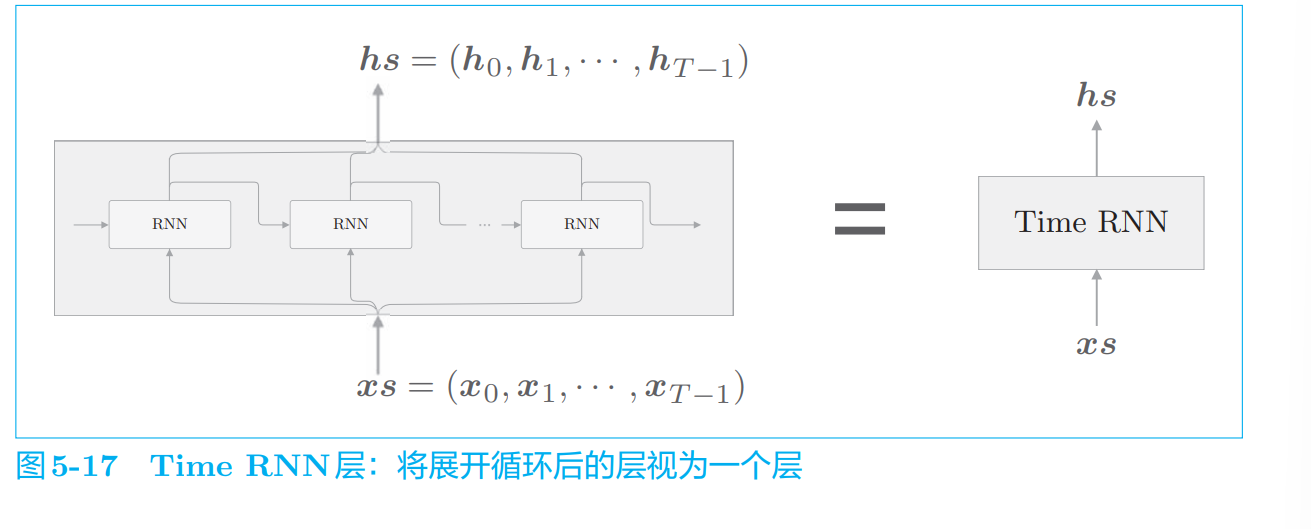
将进 行 Time RNN 层中的单步处理的层称为“RNN 层”,将一次处理 T 步的层 称为“Time RNN 层”
RNN单步 time-step处理
ht = tanh(ht−1Wh + xtWx + b) :RNN正向传播
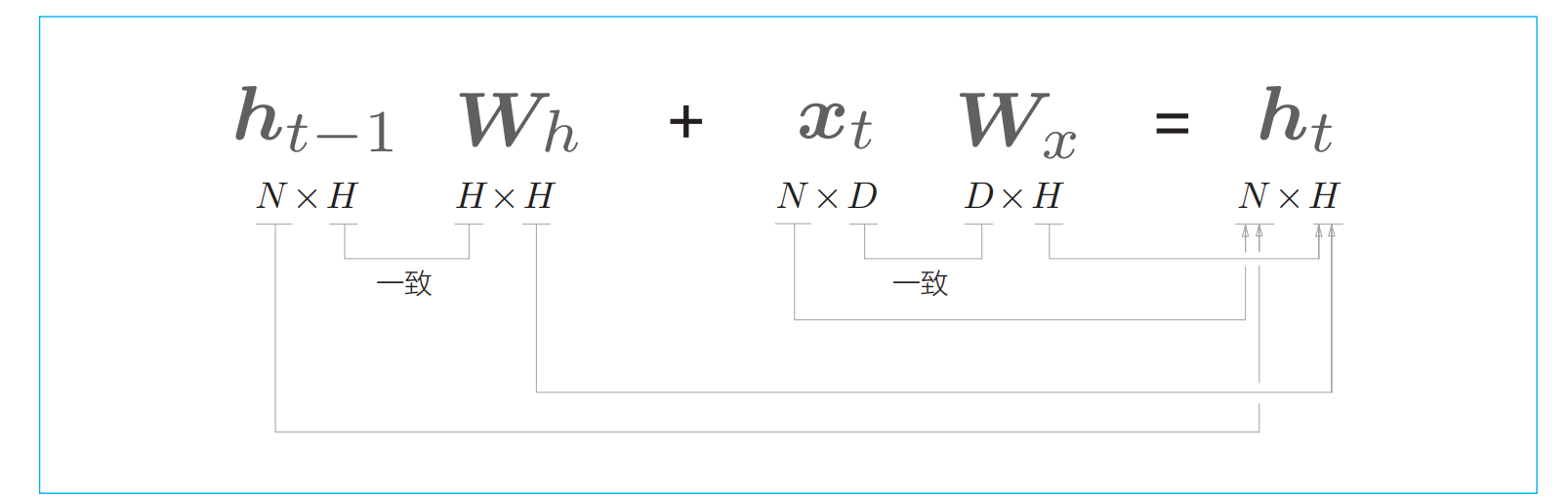
HxD * DxN + HxH*HxN = HxN
class RNN:
def __init__(self,Wx,Wh,b):
self.params = [Wx,Wh,b]#初始化参数
self.grads = [np.zeros_like(Wx), np.zeros_like(Wh),np.zeros_like(b)]#计算梯度
self.cahe = None#缓存权重,激活值等用于反向传播
#正向传播
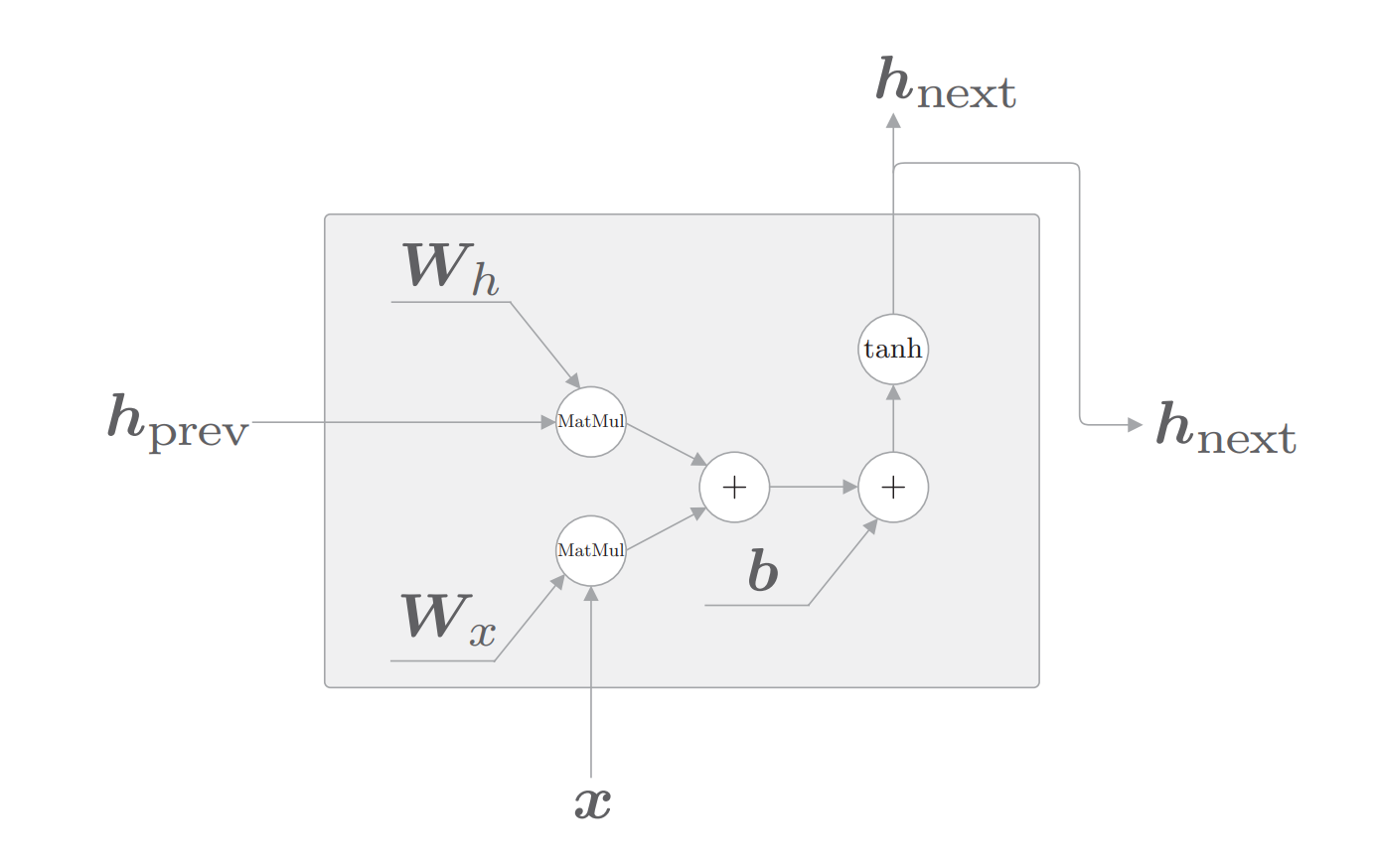
def forward(self,x,h_prev):
#用公式计算
Wx,Wh,b = self.params
t = np.dot(h_prev,Wh)+np.dot(x,Wx)+b#此处使用本书的公式,和吴恩达课程不同之处只是矩阵转置了
h_next = np.tanh(t)
self,cache = (x,h_prev,h_next)
return h_next
从前一个 RNN 层接收的输入是 h_prev,当前时刻的 RNN 层的输出(= 下 一时刻的 RNN 层的输入)是 h_next
db = ∂ h_next/∂ t x ∂ t/∂ b = dt x 1
则需要每个时间步求和:db 是偏置 b 的梯度,是 dt 沿着每个时间步的总和,计算方式如下:

这是因为偏置 b 对每个时间步的隐藏状态都有相同的梯度,因此需要将 dt 沿时间步求和以得到 db。


使用 Time RNN 层管理 RNN 层的隐藏状态
Time RNN 层是 T 个 RNN 层连接起来的网络
隐藏状态向量即为h0-ht
双向RNN
单向RNN没有完整的上下文信息
x1开始正向流动,x4开始反向流动,最后的输出由正向和反向拼接起来(可以直接使用矩阵运算一次计算)
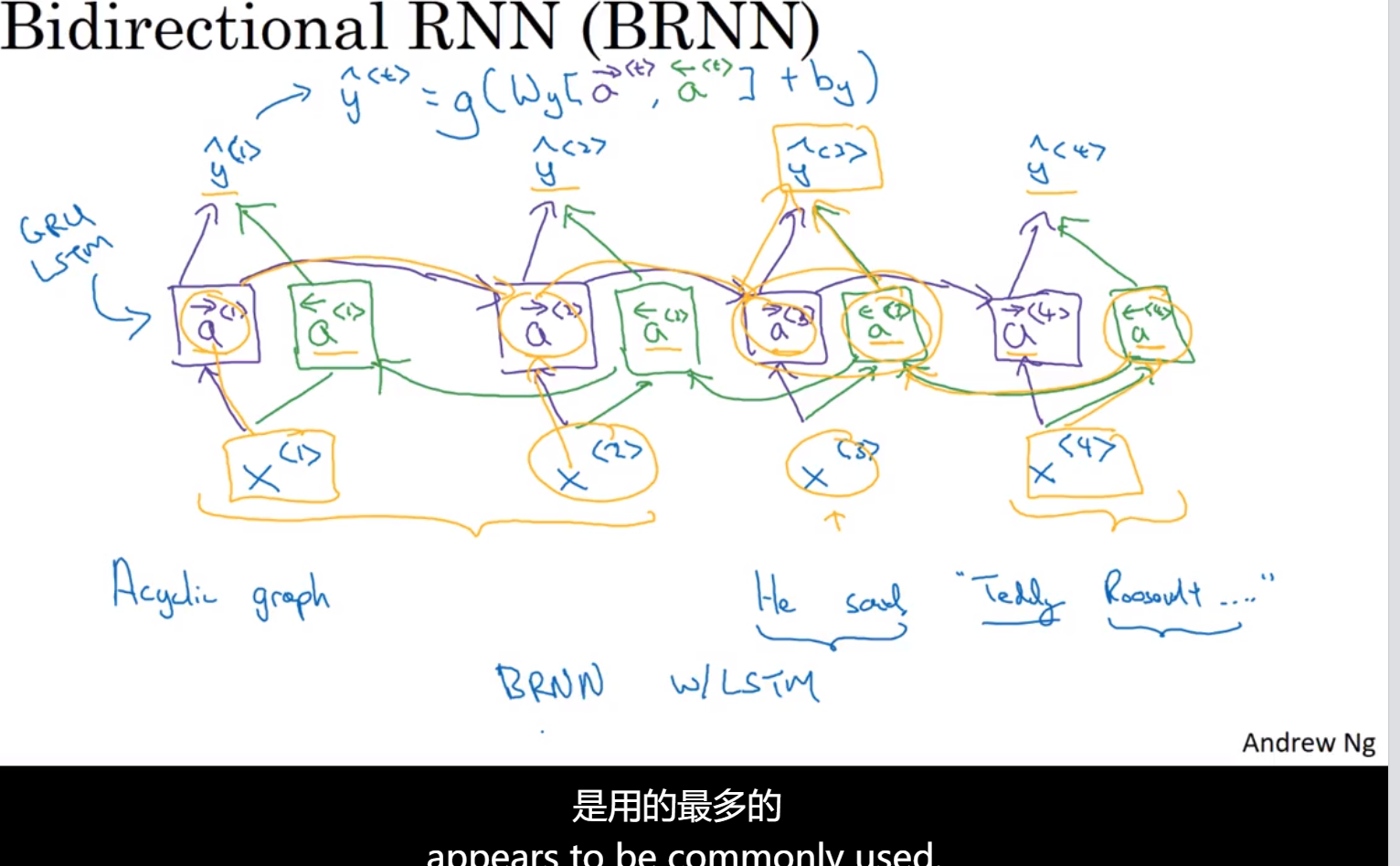
缺点:需要完整的序列(完整的句子,完整的语音等)
Deep RNN
RNN PyTorch
https://pytorch.org/docs/stable/generated/torch.nn.RNN.html

test_acc_list = []
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
pred = output.max(1, keepdim=True)[1] # 找到概率最大的下标
correct += pred.eq(target.view_as(pred)).sum().item()
# test_loss /= len(test_loader.dataset)
# test_loss_list.append(test_loss)
test_acc_list.append(100. * correct / len(test_loader.dataset))
print('Accuracy: {}/{} ({:.0f}%)\n'.format(correct, len(test_loader.dataset),100. * correct / len(test_loader.dataset)))
import torch
import torch.nn as nn
single_rnn = nn.RNN(4,3,1,batch_first=True)#特征数量,hidden size,RNN层数
input = torch.randn(1,2,4)#bs*sl*fs(x feature size),这里RNN的时间步为sl
output,h_n = single_rnn(input)
output #输出
#维度见上面图片
#双向、双层RNN
bi_rnn = nn.RNN(4,3,1,batch_first=True,bidirectional = True)#特征数量,hidden size,RNN层数
bi_output,bi_h_n = bi_rnn(input)
bi_output
#双向将b,f拼接所以3变成6
隐藏大小(hidden size)指的是RNN单元中隐藏层的神经元数量。在RNN中,隐藏状态是通过隐藏层中的神经元来表示的,隐藏层的大小决定了模型可以学习和存储的信息的容量。因此,隐藏大小直接影响了模型的表示能力和学习能力。
在PyTorch中,隐藏大小通常是在创建RNN模型时指定的一个参数。例如,对于PyTorch的nn.RNN模块,你可以通过指定参数hidden_size来设置隐藏大小。
RNN实现文本分类
多对一模型
import torch
from torch import nn
from torch.nn import functional as F
rnn = nn.RNN(input_size=10, hidden_size=20, num_layers=2)
# 可理解为一个字串长度为5(RNN训练时每个字符一个个传进去,一个字符代表一个时刻t), batch size为3, 字符维度为10的输入
input_tensor = torch.randn(5, 3, 10)
# 两层RNN的初始H参数,维度[layers, batch, hidden_len]
h0 = torch.randn(2, 3, 20)
# output_tensor最后一层所有状态!!!!!的输出(看上面那个多层的RNN图最后一层会输出h1,h2....hn)
#hn(也即Cn)表示两层最后一个时序的状态输出
output_tensor, hn =rnn(input_tensor, h0)
print(output_tensor.shape, hn.shape)
使用imdb英文电影影评数据集(二分类:消极,积极)
#查看数据集
import pandas as pd
df = pd.read_csv('IMDB Dataset.csv')
df.head(5)

from nltk.corpus import stopwords
import nltk
nltk.download('punkt')#分词模块
nltk.download('stopwords')#停用词
nltk.download('averaged_perceptron_tagger')#词性分析
#首先对数据集进行处理,对每条文本进行英文分词,使用NLTK去除数据集中的停用词,去除动词,助词等
def process_sentence(sentence):
disease_List = nltk.word_tokenize(sentence)
# print(disease_List)
# 停用词通常是一些常见的、在句子中频繁出现但并不携带实际语义信息的词语,例如“the”、“is”、“and”等
filtered = [w for w in disease_List if(w not in stopwords.words('english'))]
# print(len(filtered))
# 使用nltk.pos_tag()对剩余的词语进行词性标注,得到每个词和它的词性的元组
Rfiltered =nltk.pos_tag(filtered)
# print(Rfiltered)#返回元组('One', 'CD')的列表
# nouns = [word for word, pos in Rfiltered if pos.startswith('NN')]
filter_word = [i[0] for i in Rfiltered if i[1].startswith('NN')]
# print(filter_word)
return " ".join(filter_word)
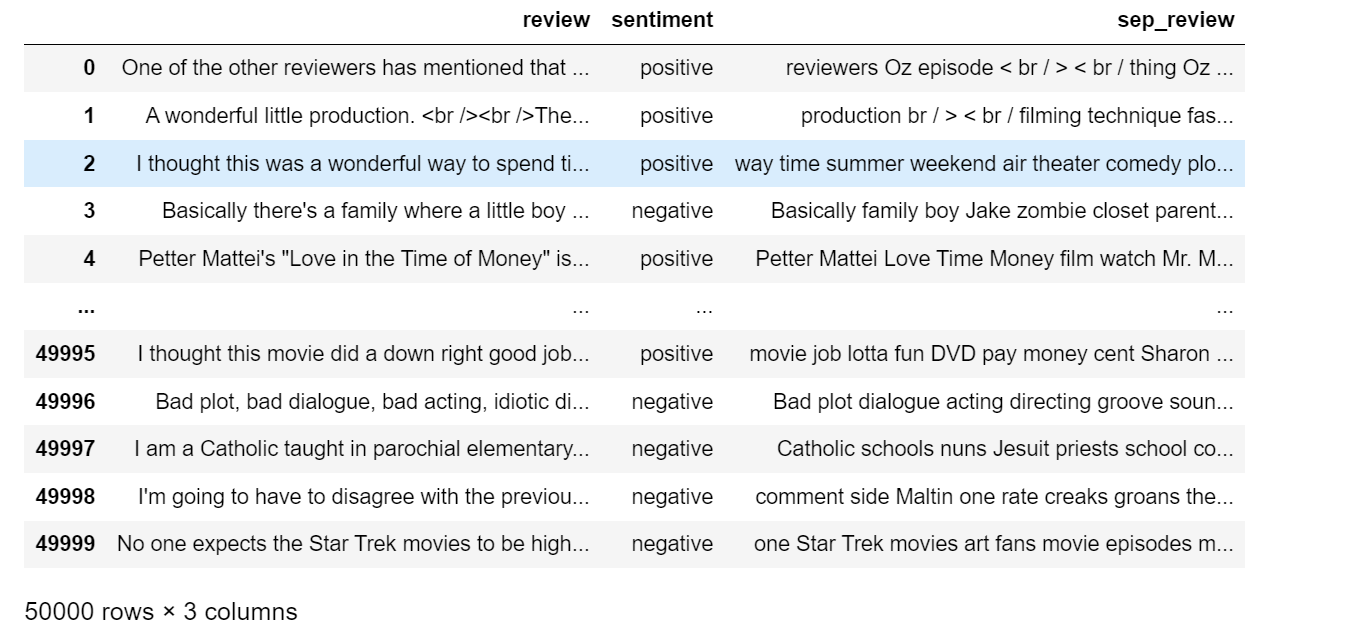
df['sep_review'] = df['review'].apply(lambda x:process_sentence(x))
df.to_csv('imdb_processed.csv')
df
use_df = df[:1000]
use_df.head(10)
sentences = list(use_df['sep_review'])
labels = list(use_df['sentiment'])
max_seq_len = max(use_df['sep_review'].apply(lambda x: len(x.split())))
PAD = ' <PAD>' # 未知字,padding符号用来填充长短不一的句子(用啥符号都行,到时在nn.embedding的参数设为padding_idx=word_to_id['<PAD>'])即可
#小于最大长度的补齐
for i in range(len(sentences)):
sen2list = sentences[i].split()
sentence_len = len(sen2list)
if sentence_len<max_seq_len:
sentences[i] += PAD*(max_seq_len-sentence_len)
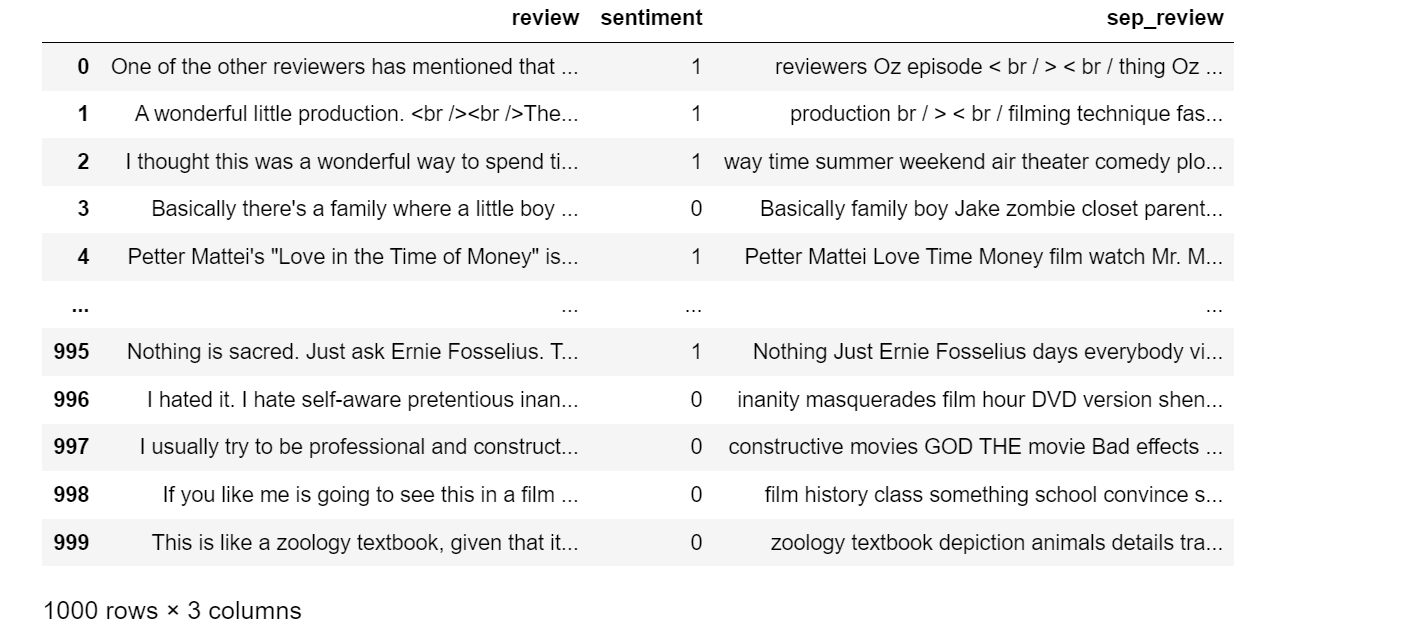
use_df['sentiment'] = use_df['sentiment'].apply(lambda x: 1 if x == 'positive' else 0)
labels = list(use_df['sentiment'])
use_df
import torch
num_classes = len(set(labels)) # num_classes=2
# 所有句子连接成一个长字符串,然后使用空格分割成单词列表,目的是收集数据集中的所有单词
word_list = " ".join(sentences).split()
#词汇表
vocab = list(set(word_list))
# 构建单词到索引的映射字典,遍历词汇表中的每个单词,将其与对应的索引建立映射关系
word2idx = {w: i for i, w in enumerate(vocab)}
vocab_size = len(vocab)
#label转换为标签0,1
# inputs,用于存储句子的索引表示。然后,它遍历每个句子 sen,将句子拆分成单词,并使用预先创建的 word2idx 字典将每个单词转换为其在词汇表中的索引。这样就得到了一个句子的索引表示,然后将其添加到 inputs 列表中
def make_data(sentences, labels):
inputs = []
for sen in sentences:
inputs.append([word2idx[n] for n in sen.split()])
targets = []
for out in labels:
targets.append(out) # To using Torch Softmax Loss function
return inputs, targets
input_batch, target_batch = make_data(sentences, labels)
# input_batch
# 返回两个列表 inputs 和 targets,它们分别包含了句子的索引表示和相应的标签。这些列表被转换为 PyTorch 的张量类型 torch.LongTensor
input_batch = torch.LongTensor(input_batch)
input_batch.shape
#每个样本有 390 个特征
# input_batch 的形状中的 390 表示词汇表的大小,即样本中的每个文本被表示为一个长度为 390 的向量
target_batch = torch.LongTensor(target_batch)
target_batch.shape
TensorDataset 是 PyTorch 中的一个数据集类,用于将张量数据和对应的目标数据打包在一起。它通常用于创建数据加载器(DataLoader),方便地加载训练数据和目标数据,从而进行模型训练和评估。
TensorDataset 的主要作用是将输入数据和对应的目标数据封装成一个数据集对象,方便后续的处理。它接受一系列的张量作为参数,每个张量对应一个特征(输入数据)或一个目标(标签)。在训练过程中,可以通过数据加载器迭代访问 TensorDataset 中的数据,每次迭代返回一个批次的输入数据和对应的目标数据。
import numpy as np
import torch.nn as nn
import torch.optim as optim
import torch.utils.data as Data
import torch.nn.functional as F
from sklearn.model_selection import train_test_split
# 划分训练集,测试集
x_train,x_test,y_train,y_test = train_test_split(input_batch,target_batch,test_size=0.2,random_state = 0)
train_dataset = Data.TensorDataset(torch.tensor(x_train), torch.tensor(y_train))
test_dataset = Data.TensorDataset(torch.tensor(x_test), torch.tensor(y_test))
# dataset = Data.TensorDataset(input_batch, target_batch)
batch_size = 16
train_loader = Data.DataLoader(
dataset=train_dataset, # 数据,封装进Data.TensorDataset()类的数据
batch_size=batch_size, # 每块的大小
shuffle=True, # 要不要打乱数据 (打乱比较好)
num_workers=2, # 多进程(multiprocess)来读数据
)
test_loader = Data.DataLoader(
dataset=test_dataset, # 数据,封装进Data.TensorDataset()类的数据
batch_size=batch_size, # 每块的大小
shuffle=True, # 要不要打乱数据 (打乱比较好)
num_workers=2, # 多进程(multiprocess)来读数据
)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device,' available')
class RNN(nn.Module):
def __init__(self,vocab_size, embedding_dim, hidden_size, num_classes, num_layers,bidirectional):
super(RNN, self).__init__()
self.vocab_size = vocab_size
self.embedding_dim = embedding_dim
self.hidden_size = hidden_size
self.num_classes = num_classes
self.num_layers = num_layers
self.bidirectional = bidirectional
# self.vocab_size:词汇表的大小,即词汇表中不同单词的数量。
# embedding_dim:词嵌入的维度,即嵌入层的输出维度。
# padding_idx:指定用于填充的特殊单词的索引,这里指定为 <PAD> 单词的索引。在训练过程中,如果输入的序列长度不足,会用 <PAD> 进行填充,以保证输入序列的长度一致。
self.embedding = nn.Embedding(self.vocab_size, embedding_dim, padding_idx=word2idx['<PAD>'])
self.rnn = nn.RNN(input_size=self.embedding_dim, hidden_size=self.hidden_size,batch_first=True,num_layers=self.num_layers,bidirectional=self.bidirectional)
if self.bidirectional:
self.fc = nn.Linear(hidden_size*2, num_classes)
else:
self.fc = nn.Linear(hidden_size, num_classes)
def forward(self, x):
batch_size, seq_len = x.shape
#初始化一个h0,也即c0,在RNN中一个Cell输出的ht和Ct是相同的,而LSTM的一个cell输出的ht和Ct是不同的
#维度[layers, batch, hidden_len]
if self.bidirectional:
h0 = torch.randn(self.num_layers*2, batch_size, self.hidden_size).to(device)
else:
h0 = torch.randn(self.num_layers, batch_size, self.hidden_size).to(device)
x = self.embedding(x)
out,_ = self.rnn(x, h0)
output = self.fc(out[:,-1,:]).squeeze(0) #因为有max_seq_len个时态,所以取最后一个时态即-1层
return output
# out[:, -1, :]:表示取 out 张量的最后一个时间步的输出。在 PyTorch 中,张量的第一个维度是 batch size,第二个维度是序列长度,第三个维度是隐藏状态的维度。因此,out[:, -1, :] 表示取所有样本的最后一个时间步的隐藏状态。
# self.fc(out[:, -1, :]):将最后一个时间步的隐藏状态通过全连接层 self.fc 进行分类预测。这一步将隐藏状态映射到分类空间,得到模型的输出。
# .squeeze(0):由于 out[:, -1, :] 的结果是形状为 (batch_size, hidden_size) 的张量,而全连接层需要的输入是形状为 (batch_size, ..., ...) 的张量,因此需要对第一个维度进行压缩,即去掉大小为 1 的维度,使得输出形状为 (batch_size, ...)。
model = RNN(vocab_size=vocab_size,embedding_dim=300,hidden_size=20,num_classes=2,num_layers=2,bidirectional=True).to(device)
criterion = nn.CrossEntropyLoss().to(device)
optimizer = optim.Adam(model.parameters(), lr=1e-3)
# PyTorch 中,可以直接使用 torch.nn.CrossEntropyLoss() 来计算交叉熵损失。此函数内部会自动进行 softmax 计算,并且可以处理多分类问题,无需手动进行 softmax 转换
model.train()
for epoch in range(10):
total_loss = 0.0 # 初始化总损失
for batch_x, batch_y in train_loader:
batch_x, batch_y = batch_x.to(device), batch_y.to(device)
pred = model(batch_x)
loss = criterion(pred, batch_y) # batch_y 类标签就好,不用 one-hot 形式
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item() # 累加每个 batch 的损失
# 打印平均损失
avg_loss = total_loss / len(train_loader)
print('Epoch:', '%04d' % (epoch + 1), 'Avg Loss =', '{:.6f}'.format(avg_loss))

test_acc_list = []
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
pred = output.max(1, keepdim=True)[1] # 找到概率最大的下标
correct += pred.eq(target.view_as(pred)).sum().item()
# test_loss /= len(test_loader.dataset)
# test_loss_list.append(test_loss)
test_acc_list.append(100. * correct / len(test_loader.dataset))
print('Accuracy: {}/{} ({:.0f}%)\n'.format(correct, len(test_loader.dataset),100. * correct / len(test_loader.dataset)))
RNN的缺陷
Consider trying to predict the last word in the text “I grew up in France… I speak fluent French.” Recent information suggests that the next word is probably the name of a language, but if we want to narrow down which language, we need the context of France, from further back. It’s entirely possible for the gap between the relevant information and the point where it is needed to become very large.
Unfortunately, as that gap grows, RNNs become unable to learn to connect the information.
RNN梯度消失
例:
如果句子后期的单词对前期的单词有依赖(long-term),RNN不擅长捕获这种依赖(由于深度网络的梯度消失问题,反向传播困难,后期误差难以影响前期计算)
如果出现梯度爆炸则使用梯度修剪

RNNLM,BPTT:梯度将从正确解标签 Tom 出现的地方向过去的方向传播
通过将这些信息向过去传 递,RNN 层学习长期的依赖关系。但是,如果这个梯度在中途变弱(甚至 没有包含任何信息),则权重参数将不会被更新
原因
RNNLM的计算图中“+”的反向传播将上游传来的梯度原样传给下游
x是神经网络中的某一层的输入,它是由上一层的输出和权重矩阵相乘得到的。也就是说,x = Wf,其中 W 是权重矩阵,f 是上一层的激活函数。如果上一层也是 tanh 函数,那么 f 的值的范围是 (-1, 1)。如果 W 的元素的绝对值都大于 1,那么 x 的值就会越来越大,远离 0。这种情况下,tanh 函数的导数的值就会越来越小,接近于 0。
那么,为什么 W 的元素的绝对值会大于 1 呢?这就涉及到神经网络的初始化和更新的问题。如果我们随机初始化 W 的元素,那么有可能出现一些很大或很小的值。如果我们使用梯度下降法来更新 W 的元素,那么有可能出现梯度爆炸或梯度消失的问题。梯度爆炸是指梯度的值变得非常大,导致 W 的元素的更新幅度过大,使得 W 的元素的绝对值越来越大。梯度消失是指梯度的值变得非常小,导致 W 的元素的更新幅度过小,使得 W 的元素的绝对值越来越小。这两种问题都会影响神经网络的收敛和性能。
改进:使用ReLU函数
当 x 大于 0 时,反向 传播将上游的梯度原样传递到下游,梯度不会“退化”
论文:Improving performance of recurrent neural network with relu nonlinearity
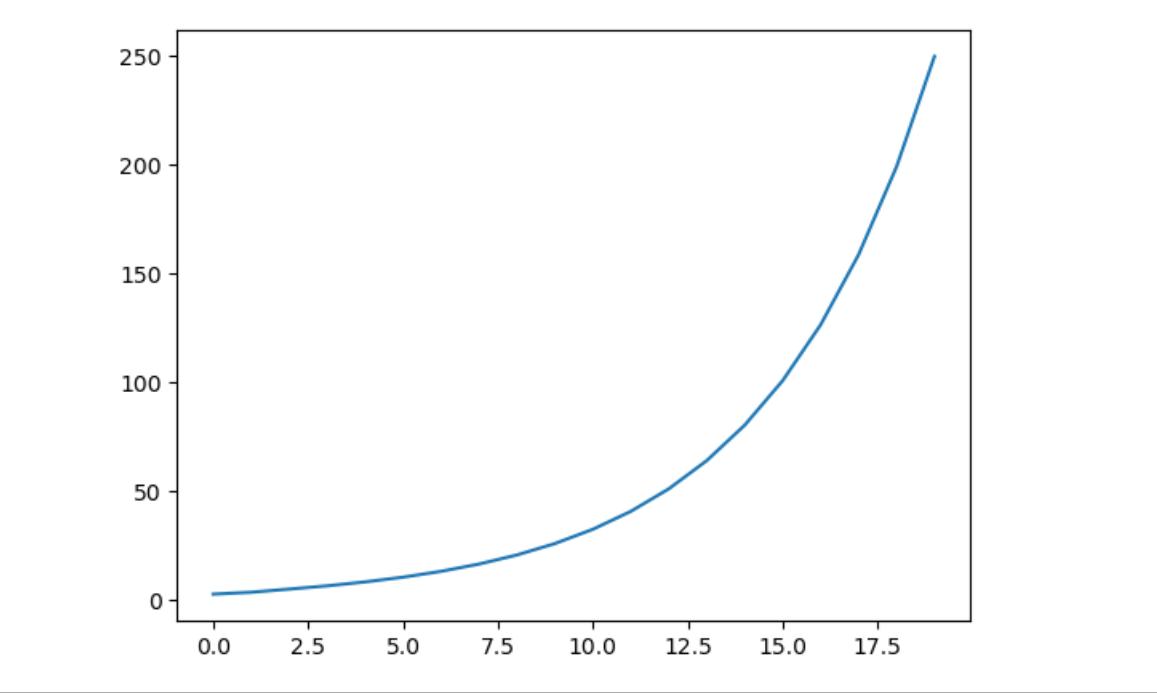
如果奇异值的最大值大于 1,则可以预测梯度很有可能会呈指数 级增加;而如果奇异值的最大值小于 1,则可以判断梯度会呈指 数级减小。但是,并不是说奇异值比 1 大就一定会出现梯度爆炸。 也就是说,这是必要条件,并非充分条件

#测试梯度爆炸/消失
import numpy as np
import matplotlib.pyplot as plt
N = 2 # mini-batch的大小
H = 3 # 隐藏状态向量的维数
T = 20 # 时序数据的长度
dh = np.ones((N, H))
np.random.seed(3) # 为了复现,固定随机数种子
Wh = np.random.randn(H, H)
norm_list = []
for t in range(T):
dh = np.dot(dh, Wh.T)
norm = np.sqrt(np.sum(dh**2)) / N
norm_list.append(norm)
print(norm_list)
plt.plot(norm_list)
本文作者:ziggystardust
本文链接:https://www.cnblogs.com/ziggystardust-pop/p/18029309
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律