
python+selenium自动化软件测试(第10章):测试驱动TDD
测试驱动开发模式,要求开发在写业务代码的时候,先写出测试代码,同时单元测试例子决定了如何来写产品的代码,并且不断的成功的执行编写的所有的单元测试例子,不断的完善单元测试例子进而完善产品代码, 这样随着功能的开发完成,测试代码也会对应的完成, 很显然,这是一个全新的开发模式, 在一定程度上,可以完全的提高软件的质量,以及开发可以对自己写的代码进行一个全面的评估和测试。
TDD 模式是一个很大的概念,在这里, 我重点介绍下测试驱动模式与自动化的融合以及精简自动化的测试代码。
下面我们来看一个登录的案例:
coding:utf-8 import unittest from selenium import webdriver class developTest(unittest.TestCase): def setUp(self): self.driver = webdriver.Firefox() self.driver.implicitly_wait(30) self.driver.maximize_window() self.driver.get('http://xxxx/login') self.addCleanup(self.driver.quit) def testLogin(self): #用户名输入 name = self.driver.find_element_by_id('xxxx') name.clean() name.send_keys('xxxx') #密码输入 passwd = self.driver.find_element_by_id('xxxx') passwd.clear() passwd.send_keys('xxxx') #点击登录 self.driver.find_element_by_id('xxxx').click() #获取到用户昵称 userName = self.driver.find_element_by_xpath("xxx") userlnfo = userName.text #退出系统 userName.click() self.driver.find_element_by_xpath("xxxx").click() self.assentTrue(userlnfo in 'linux') if __name__ =='__main__': unittest.main(verbosity=2)
如上的代码, 我们成功的实现了登录 ,获取到用户的昵称,退出系统,以及验证用户昵称这样的一个过程, 但是问题也就来了,如果我登录系统 N 次以及退出系统次,那么就意味着写登录退出就得 N次,很明显,这样很多的登录退出的代码都是一致的,增加了工作量,如下, 我通过把登录,退出,获取到用户昵称,写成一个单独的函数,然后使用到了直接调用对应的函数(调用的时候记得导入), 文件名称是 kuihua.py, 具体代码为如下:
#coding:utf-8 #登录函数 def login(driver,usenname='I59xxxxx',password='server'): driver.find_element_by_id('xxxx').send_keys(usenname) driver.find_element_by_id('xxxx').send_keys(password) driver.find_element_by_id('xxxx').click() #获取用户昵称 def getName(driver): return driver.find_element_by_xpath("xxxx").text #退出系统 def exitSystem(driver): dniver.find_element_by_xpath("xxxx").click() dniver.find_element_by_xpath("xxxx").click() 如上函数之后,测试脚本就精简很多了,测试脚本见如下: #coding:utf-8 import unittest from selenium import webdriver import kuihua class developTest(unittest.TestCase): def setUp(self): self.driver=webdriver.Firefox() self.driver.implicitly_wait(30) self.driver.maximize_window() self.driver.get('http://my.weke.com/login.html') self.addCleanup(self.driver.quit) def testLogin(self): kuihua.login(self.driver) userInfo=vke.getName(self.driver) vke.exitSystem(self.driver) self.assentTrue(usenInfo in 'linux') if __name == '__main__': unittest.main(verbosity=2)
通过这样的一个实例, 我们把测试脚本精简了很多,其实还可以把最后一步精简下,但是我一般感觉,最后一步还是在测试代码中比较好,因此我们可以总结出如下几点:
1、 对于某些公用的功能,如登录,退出,单独写成一个函数, 需要
的时候,直接调用函数;
2、 验证点一定要写在最后一步,本实例验证用户昵称部分,不可以写在退出之前验证,先获取到用户昵称,退出系统,再验证用户昵称
3、 尽量保持测试脚本与页面对象元素分离开,这样即使系统需求变更或者开发把页面元素更改了,我们只在一个地方维护,而不影响 tescase 的脚本。虽然我们实现了把测试用例的代码精简化, 实现了测试脚本与页面对象的分离,实现了后期维护页面对象只在一个地方维护,但是还是存在很多的缺点, 我们可不可以把使用到的数据,页面对象放在.csv.xml 文件中了?答案当然是可以, 下来部分我们重点介绍把使用到的数据放在.txt, .csv, . xlsx, xml 文件中, 同时介绍 ddt 模块的安装以及使用方法, 来继续重构我们的测试代码。
10.1 ddt 模块
ddt 是 python 的第三库, 全名称为: Data-Driven/Decorated Tests。ddt 模块提供了创建数据驱动的测试,关于该模块,建议到官方查看详细的说明, 安装方法分别为命令行安装或者下载文件进行安装,分别进行说明,二种安装的方式具体见如下:
1、下载ddt文件,让后解压,到解压的目录下,输入: pythonsetup.py install 安装,见如下的截图:

2、 直接使用 pip 在线安装 ddt, 命令为: pip install ddt

在实际自动化测试中的应用,代码如下:
#coding:utf-8 import unittest from selenium import webdriver from ddt import ddt,data,unpack from time import sleep @ddt class developTest(unittest.TestCase): def setUp(self): self.driver = webdriver.Firefox() self.driver.implicitly_wait(30) self.driver.maximize_window() self.driver.get('http://www.baidu.com') self.addcleanup(self.driver.quit)@data(('','',u'手机/邮箱/用户名'),('admin','',u'请您填写密码'),('admin','admin',u'您输入的帐号或密码有误,忘记密码?')) @unpack def testLogin(self, sendValue1, sendValue2, expected): self.driver.find_element_by_link_text(u'登录’).click() sleep(2) #输入百度账号 userName=self.driver.find_element_by_id('xxxx') userName.clear() userMame.send_keys(sendValuel) #输入百度密码 password=self.driver.find_element_by_id('xxxxx') password.clear() password.send_keys(sendValue2) #点击登录按钮 self.driver.find_element_by_id('xxxxx').click() #获取到返回的错误信息 errorText=self.driver.find_element_by_xpath("xxxxx").text self.assentTrue(emonText, expected) if __name__ =='__main__': unittest.main(verbosity=2)
从如上的代码以及执行结果的截图,我们可以地得到,这个测试用例
验证了三个验证点, 分别是:
1、 百度账号为空, 密码为空, 点击登录按钮, 验证返回的错误信息
2、 输入百度账号,未输入密码, 验证返回的错误信息
3、 输入错误的账号和错误的密码, 验证返回的错误信息
但是我们的核心代码只有如下的几行:
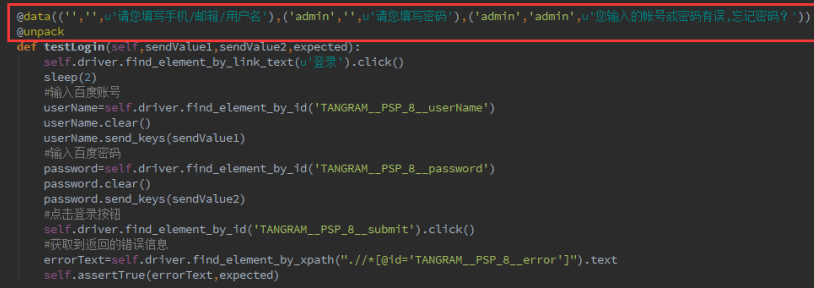
ddt 模块的优秀之处, 几行代码,实现多个测试点, 可以少写了很多代码。
10.2 csv 文件的处理
python提供了对 csv文件处理的模块,直接 import csv就可以了,那么神秘是 csv 文件了? csv 文件全名称为 Comma-SeparatedValues,csv 是通用的,相对简单的文件格式,其文件已纯文件形式存储数据。 我们把数据存储在 csv 的文件中,然后写一个函数获取到 csv文件的数据, 在自动化中引用,这样,我们自动化中使用到的数据,就可以直接在 csv 文件中维护了,见下面的一个 csv 文件的格式:

下面我们实现读写 csv 文件中的数据,具体见如下实现的代码:
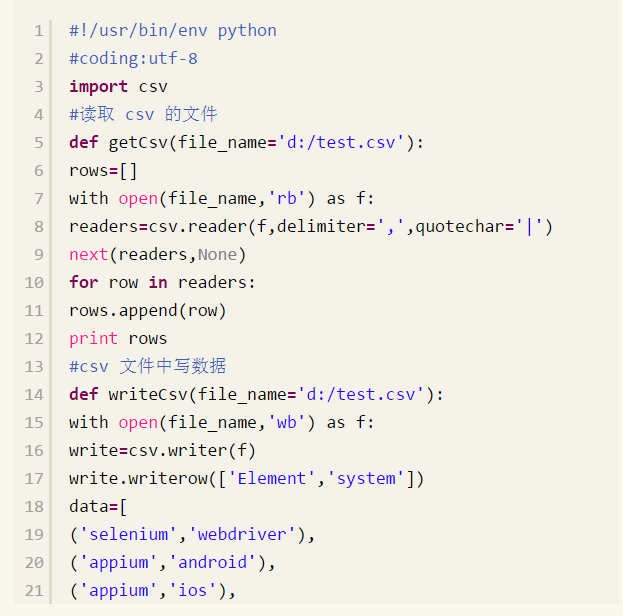
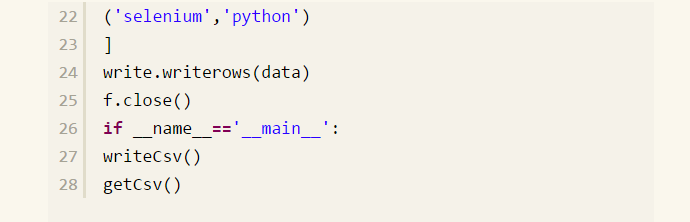
为了具体读取到 csv 文件中某一列的数据,我们可以把读取 csv 文件的方法修改如下,见代码:

如我们需要读取第一个 selenium, csv 文件内容见如上的截图,那么调用的方法代码为:
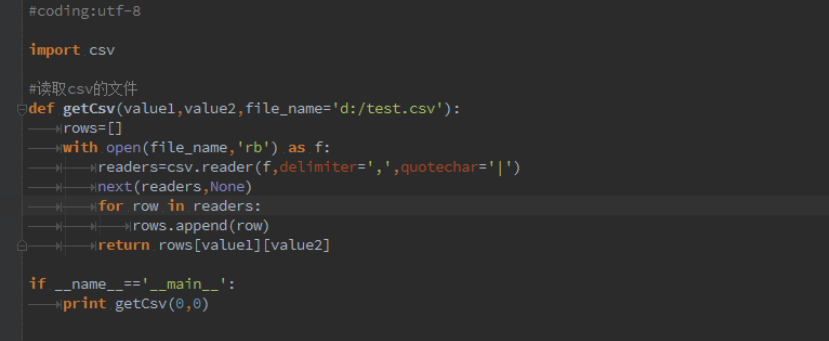
执行后如下截图:

已百度搜索输入框为实例,在搜索输入框输入 csv 文件中的字符,我们把读写 csv 文件的函数写在 location.py 的模块中,见 location.py的源码:
#coding:utf-8 import csv #读取CSV的文件 def getCsv(valuel,value2,file_name='d:/test.csv'): nows=[] with open(file_name,'nb') as f: neaders=csv.reader(f,delimiters't ',quotechar='|') next(readers^None) for row in readers: rows.append(row) return rows[valuel][value2] #csv文件中写数据 def writeCsv(file_name='d:/test.csv'): with open(file_name,'wb') as f: wnite=csv.writer(f) write.writerow(['Element','system'])data=[ ('selenium''webdriver'), ('appium','android'), ('appium','ios'), ('selenium','python')] write.writerows(data) f.close()
把测试代码写在 baiduTest.py 的模块中,见该模块的源码:
#coding:utf-8 from selenium import webdriver import location import unittest import time time.sleep(5) class BaiduTest(unittest.TestCase): def setUp(self): self.driver=webdriver.Firefox() self.driver.maximize_window() self.driver.implicitly一wait(30) self.driver.get(location.getCsv(4,0)) def testCase_01(self): '''获取CSV文件中第二列第_位的数据进行搜索''' self.driver.find_element_by_id('kw').send_keys(location.getCsv(l,0)) def tearDown(self): self.driver.quit() if __name__=='__main__': suite = unittest.TestLoader().loadTestsFnomTestCase(BaiduTest) unittest.TextTestRunner(verbosity=2).run(suite)
在如上的测试代码中,我把 url,以及搜索的字符都放在了 csv 的文件中,在测试脚本中,只需要调用读取 csv 文件的函数,这样,我们就可以实现了把测试使用到的数据存储在 csv 的文件中,来进行处理。
在前面我这边介绍到了 ddt 的模块,那么现在我这边 ddt 模块和csv 文件结合,来进行自动化的测试,编辑后的 csv 文件后:
我重新写 location.py 的模块,具体见该模块的源码:
#coding:utf-8 import csv def getCsv(file_name): rows=[] with open(file_name, 'rb') as f: readers = csv.reader(f, delimiter=',', quotechar='|') next(readers, None) for row in readers: rows.append(row) return rows
实现在百度搜索输入框输入搜索关键字分别是 selenium,appium,那么实现的测试模块 baiduTest.py 的源码为:
#coding:utf-8 from selenium import webdriver from ddt import ddt,data,unpack import location import time import unittest, sys neload(sys) sys.setdefaultencoding('utf-8') @ddt class BaiduTest(unittest.TestCase): def setUp(self): self.driver=webdriver.Firefox()self.driver.maximize_window() self.driver.implicitly_wait(30) self.driver.get('http://www.baidu.com/') @data(*location.getCsv("d:\\xxx.csv")) @unpack def testCase_01(self,actual,expect): '''ddt模块与csv文件结合的使用''' self.driver.find_element_by_id('kw').send_keys(actual) time.sleep(5) def tearDown(self): self.driver.quit() if '__name__' == '__main__': suite=unittest.TestLoader().loadTestsFromTestCase(BaiduTest) unittest.TextTestRunner(verbosity=2).run(suite)
我们就实现了单独读取 csv 文件中的内容,或者 csv 文件和 ddt模块结合来在自动化中使用。
10.3 xlsx 文件的处理
一般性的,数据存储在 excel 中,也是一种选择,但是必须安装对应的库,要不 python 是无法操作 excel 文件的,安装的第三方库为为 xlrd, 安装命令为:
pip install xlrd
安装过程:
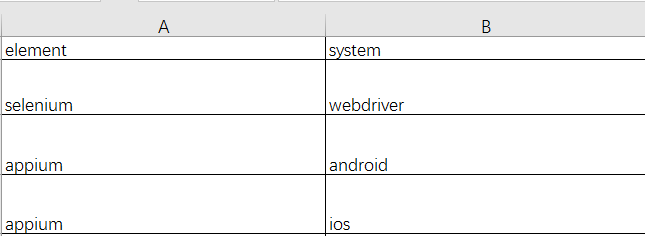
Excel 文件的后缀格式为.xlsx,实例中 excel 的数据为:

所以,我们需要读取 excel 中的数据,首先需要 import xlrd,然后才可以读取 excel 文件中的数据。 在 excel 文件中, cell 是单元格,sheet 是工作表,一个工作表由 N 个单元格来组成。下面来实现读取
excel 文件中的数据,见如下的代码:
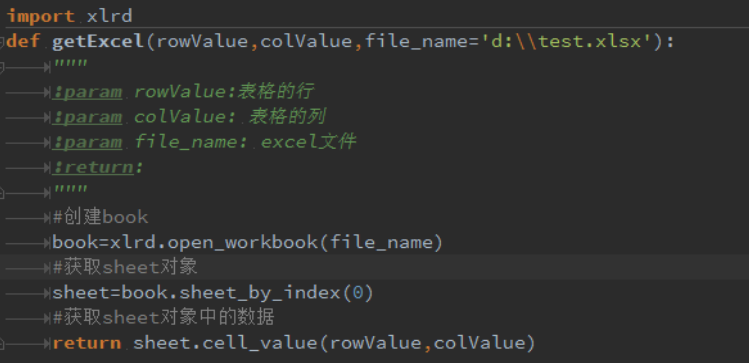
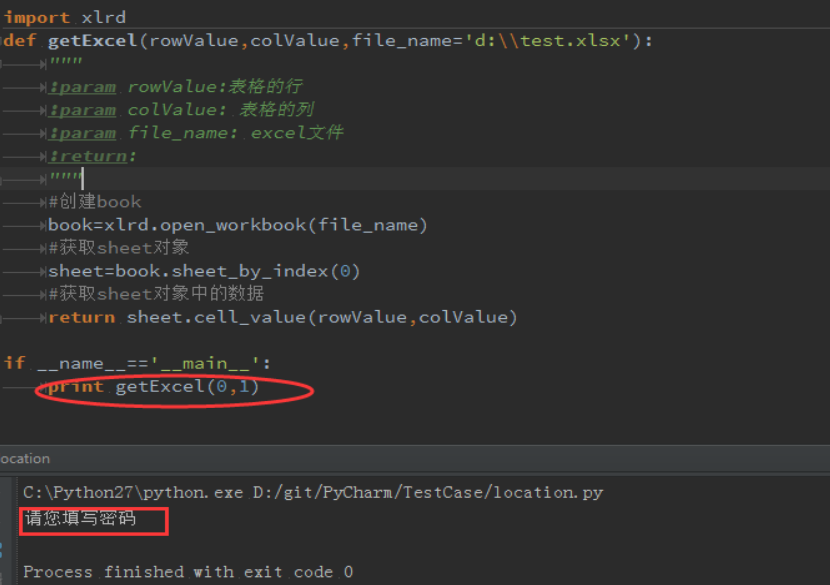
我把读取 excel 中的数据写成一个函数, 先导入 xlrd 的库,然后创建book,以及获取 sheet 对象,依次获取 sheet 对象中的数据,在如上的excel 数据中,如果我想获取“请你填写密码”,那么直接调用该函数,并且传对应的参数分别为(0,1),见执行的代码截图:
如果读取 excel 一个 sheet 对象的所有数据,修改后的代码为:

我们已百度登录为实例,来说明 excel 文件在自动化中的引用,
测试点分别为:
1、输入百度账号,未输入百度密码,点击登陆,验证返回的错误信息;
2、输入错误的百度账号密码,点击登录,验证返回的错误信息;
我们读 excel文件的函数,登录百度的函数写在 location.py的模块中,见 location.py 模块的代码:
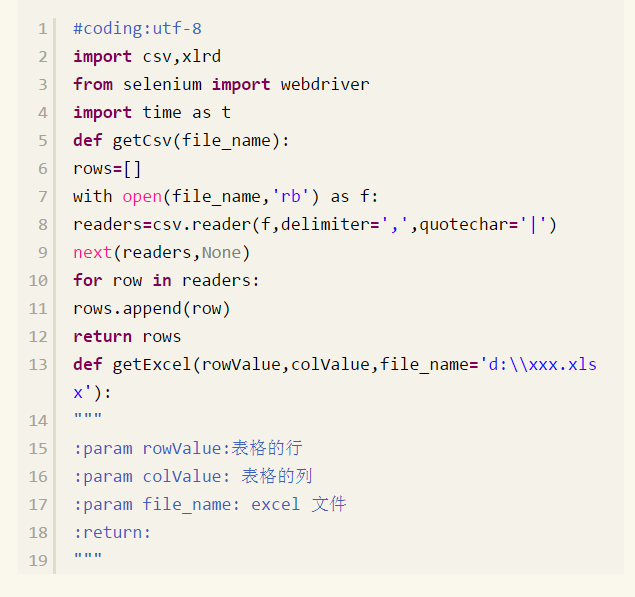
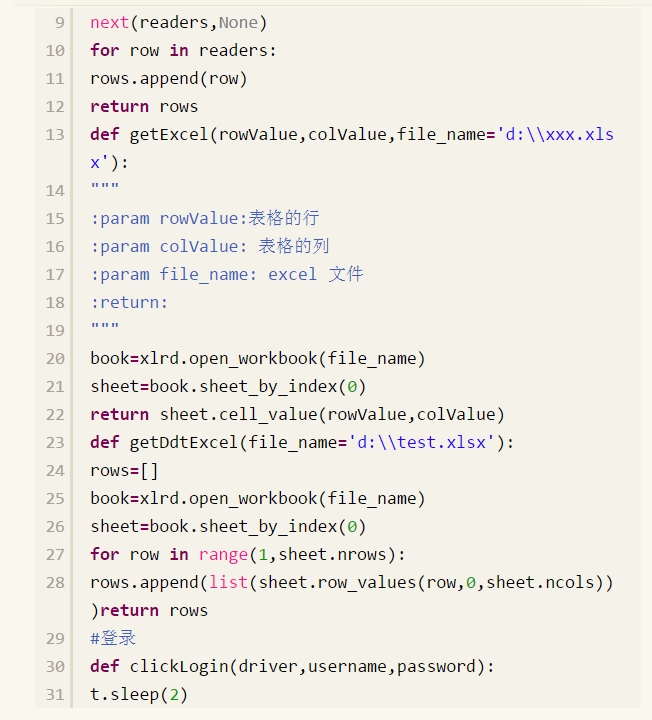
#coding:utf-8 import csv, xlrd from selenium import Webdriver import time as t def getCsv(file_name): nows = [] with open(file_name,’rb') as f: readers = csv.reader(f,delimiters = ',',quotechar = '|') next(readers,None) for row in readers: rows.append(row) return rows def getExcel(nowValue, colValue, file_name = 'd:\\xxx.xlsx'): ''' :param rowValue:表格的行 :param colValue:表格的列 :panam file_name: excel 文件 :return: ''' book = xlrd.open_workbook(file_name) sheet = book.sheet_by_index(0)return sheet.cell_value(rowValue,colValue) def clickButton(driver): driver.find_element_by_xpath("xxx").click() t.sleep(2) def clickLogin(driver, username, password): name = driver.find_element_by_id('xxx') name.clear() name.send_keys(usenname) t.sleep(2) passwd=driver.find_element_by_id('xxxx') passwd.clear() passwd.send_keys(password) t.sleep(2) driver.find_element_by_id('xxx').click() t.sleep(2) #获取返回的错误信息 def getText(driver): return driver.find_element_by_xpath("xxx").text
把测试代码写在 baiduTest.py 的模块中,见该模块的测试代码:
#coding:utf-8 from selenium import webdriver import time as t import location import unittest, sys reload(sys) sys.setdefaultencoding('utf-8') class BaiduTest(unittest.TestCase): def setUp(self): self.driver = webdriver.Firefox() self.driver.maximize_window() self.driver.implicitly一wait(30) self.driver.get('http://www.xxx.com/') def testCase_01(self): ''' 验证只输入百度账号密码,点击登录返回的错误信息 :return: ''' driver = self.driver location.clickButton(driver) location.clickLogin(driver, location.getExcel(0,0), location.getExcel(l,0)) self.assentEqual(location.getText(driver, location.getExcel(l,l)) def testCase_02(self): ''' 验证只输入百度账号,未输入密码,点击登录返回的错误信息 :return: ''' driver = self.driver location.clickButton(driver) location.clickLogin(driver, location.getExcel(0,0),location.getExcel(2,0)) self.assentEqual(location.getText(driver, location.getExcel(0,l)) def tearDown(self): self.driver.quit() if __name__ == '__main__': suite = unittest.TestLoader().loadTestsFromTestCase(BaiduTest) unittest.TextTestRunner(verbosity=2).run(suite)
这样,我们就实现了把测试中使用到的数据,存储在 excel 中,然后利用 xlrd 模块来读取 excel 中的数据,达到测试代码与数据的分离。
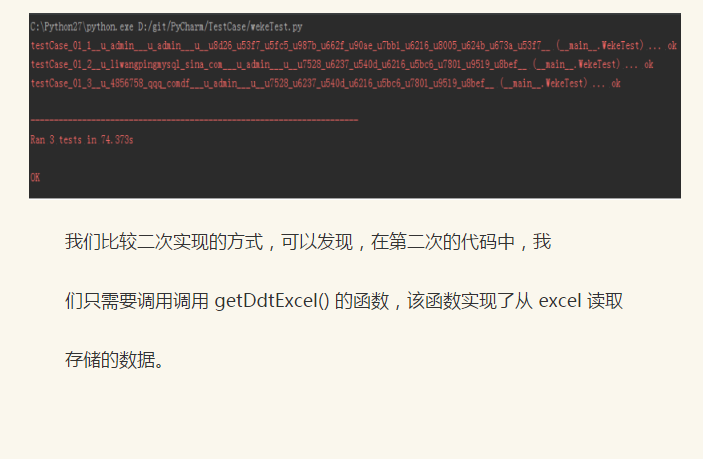
详细的介绍了 ddt 模块的安装以及在自动化项目中的使用,我们再已验证 V 客网登录界面为实例,来说明 ddt 模块在自动化中的实战,验证点分别为如下几点:
验证点一:输入无效的用户名和密码,验证返回的错误信息
验证点二:输入有效的用户名和无效的密码,验证返回的错误信息
验证点三:输入无效的邮箱和无效的密码,验证返回的错误信息
我们把读取数据的方法,登录以及获取错误信息,编写的 location.py的模块中,见 location.py 的源码:






 浙公网安备 33010602011771号
浙公网安备 33010602011771号