
HTTP压缩
HTTP的压缩过程如下:
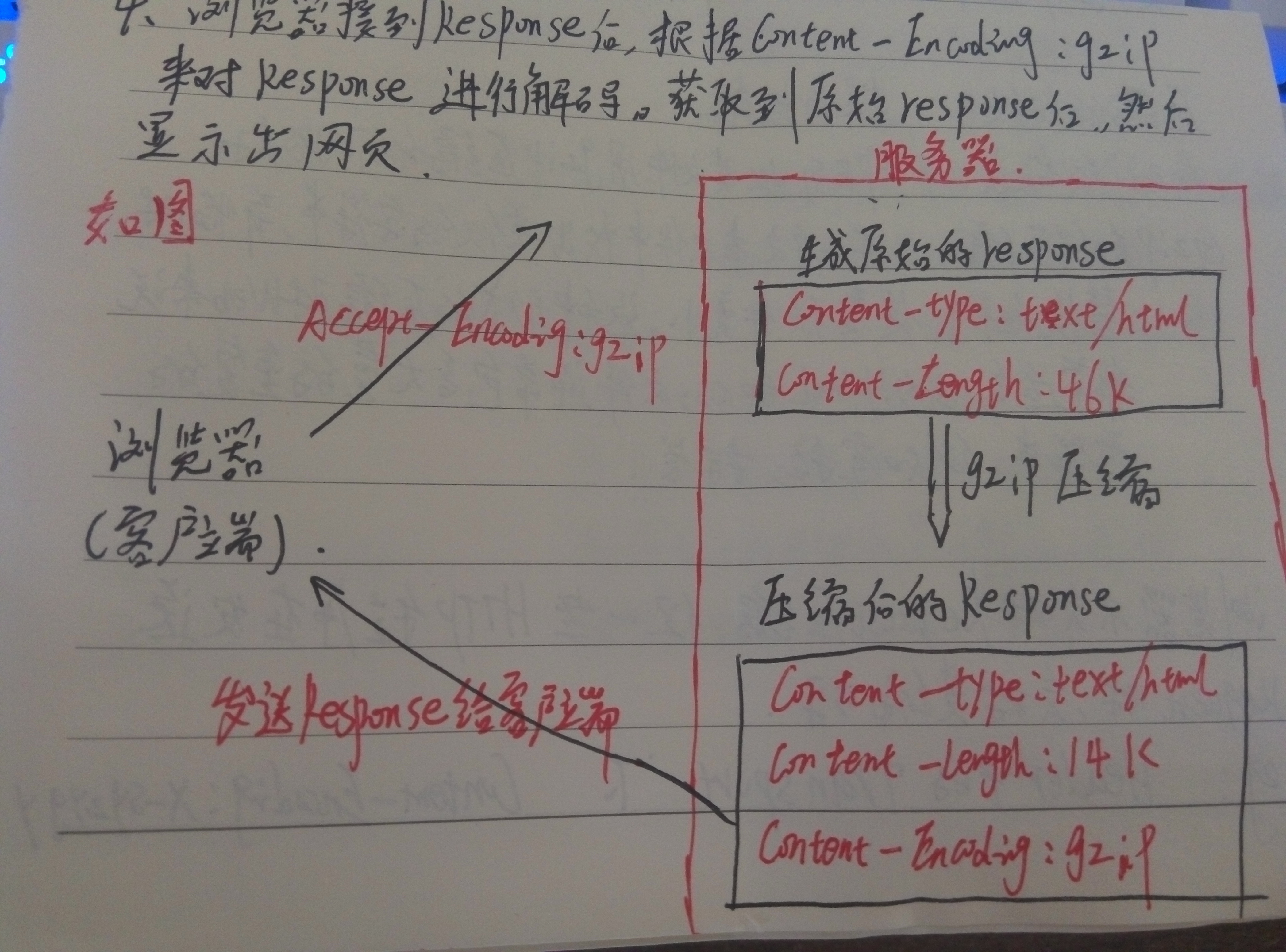
1、浏览器发送HTTP Request给Web服务器,Request中含有Accept—Encoding:gzip,deflate(告诉服务器支持的压缩格式);
2、Web服务器接到Request后,生成原始的Response,其中有原始的Content—Type和Content—Length;
3、服务器通过Gzip对Response进行编码,编码后header中含有Content—Type和Content—Length(压缩后的大小),并且增加了Content—Encoding:gzip,然后把Response发送给浏览器;
4、浏览器接到Response后,根据Content—Encoding:gzip来对Response进行解码,获取到原始的Response后显示在网页上。
如图:(唉,鼠绘的技能没点,电脑也没装画图软件,将就点看这个图吧):
补充一点关于压缩的东西:
1、Content—Encoding值:
a)、gzip 表明实体采用GNU Zip编码
b)、compress 表明实体采用Unix的文件压缩程序
c)、deflate 表明实体是用zlib的格式压缩的
d)、identity 表明没有对实体进行编码,当没有Content—Encoding Header时,默认为这种情况
2、gzip,compress以及deflate编码均为无损压缩算法,其中gzip通常效率最高,使用最为广泛
3、压缩的好处:提高性能
Gzip的缺点:JPEG此类文件用gzip压缩的不够好
Gzip如何压缩:在一个文本文件中找出类似的字符串,并临时替换它们,使整个文件变小,这种形式的压缩对Web来说非常适合。因为HTML和CSS文件通常包含大量的重复的字符串,例如空格、标签等。
4、浏览器不会自动对Request进行压缩,但一些HTTP程序在发送Request时间,会对其编码。
eg:Header中的Transport下Content—Encoding:X—Syzygy

