JS逆向实战23——某市wss URL加密+请求头+ws收发
声明
本文章中所有内容仅供学习交流,抓包内容、敏感网址、数据接口均已做脱敏处理,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关,若有侵权,请联系我立即删除!
本文首发链接为: https://mp.weixin.qq.com/s/o5UCJFhBg-4JFdS0aEwDuw
前言
在此前。我们先来了解下什么是webscoket?什么是wss?什么是ws?
WebSocket协议是html5的一种通信协议,该协议兼容我们常用的浏览器。例如Chrome、 Firefox、IE等。
它可以使客户端和服务端双向数据传输更加简单快捷,并且在TCP连接进行一次握手后,就可以持久性连接,同时允许服务端对客户端推送数据。
外加传统模式的协议一般HTTP请求可能会包含较长的头部,但真正有效的可能只有小部分,从而就占用了很多资源和带宽。因此WebSocket协议不仅可以实时通讯,支持扩展;也可以压缩节省服务器资源和带宽。
WS协议和WSS协议两个均是WebSocket协议的SCHEM,两者一个是非安全的,一个是安全的。也是统一的资源标志符。就好比HTTP协议和HTTPS协议的差别。非安全的没有证书,安全的需要SSL证书。
(SSL是Netscape所研发,用来保障网络中数据传输的安全性,主要是运用数据加密的技术,能够避免数据在传输过程被不被窃取或者监听。)
其中WSS表示在TLS之上的WebSocket。WS一般默认是80端口,而WSS默认是443端口,大多数网站用的就是80和433端口。
(在高防防护过程中,80和433端口的网站是需要备案才可以接入国内的。)当然网站也会有别的端口,这种如果做高防是方案是可以用海外高防的。
WS和WSS的体现形式分别是TCP+WS AS WS ,TCP+TLS+WS AS WS。服务器网址就是 URL。
目标网站
aHR0cDovL3d3dy5sdXhpLmdvdi5jbi9jb2wvY29sNDQ0NC9pbmRleC5odG1s
抓包分析
我们掏出我们的抓包工具看看。我们这里选择charles去抓包。
这里吐出了两个数据包,一个是https协议的,一个是wss协议的。
https协议:
每个都看了 其他的请求都没用。只有这个v1 这个请求不确定。
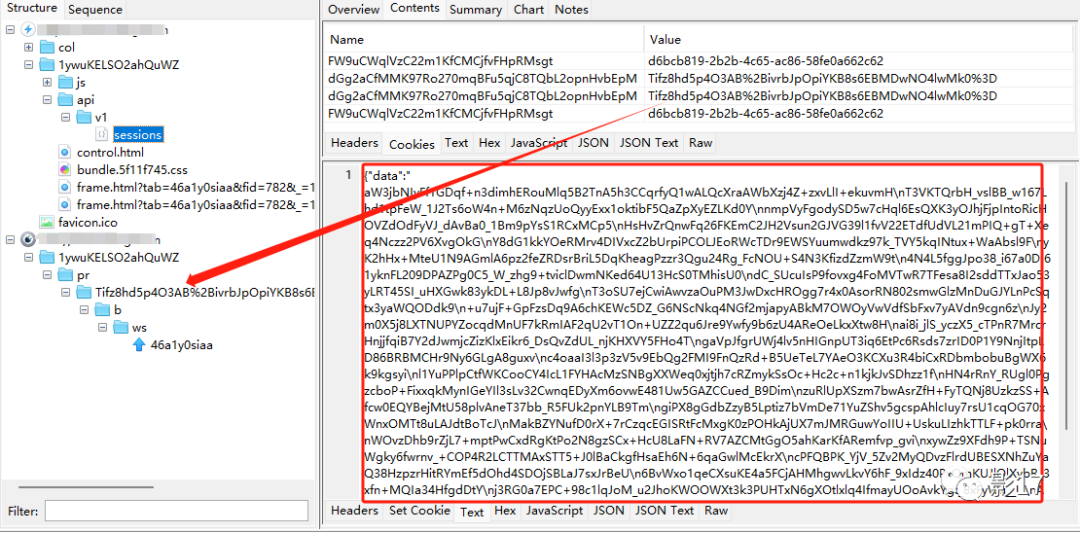
这里我们简单分析一下:
- 返回给我们的cookie的
dGg2aCfMMK97Ro270mqBFu5qjC8TQbL2opnHvbEpM这个的value的值 对应的就是wssURLpr的后缀 - v1/sessions这个请求返回给我们的值是一段加密的值。
- 其他的页面均无数据来源。
这里我们大胆猜测一下:这个v1session这个请求返回给我们的值。
我们需要解密,解密出来的值,大概率就是这个 dGg2aCfMMK97Ro270mqBFu5qjC8TQbL2opnHvbEpM cookie的值。
然后我们提取出来。完成对wss这个URL的拼接。从而请求。当然这些都是猜测。我们再来看看wss请求。
wss协议:
这里只有一个请求。就不搞那些弯弯绕绕了。话不多说 直接看contents里的内容。
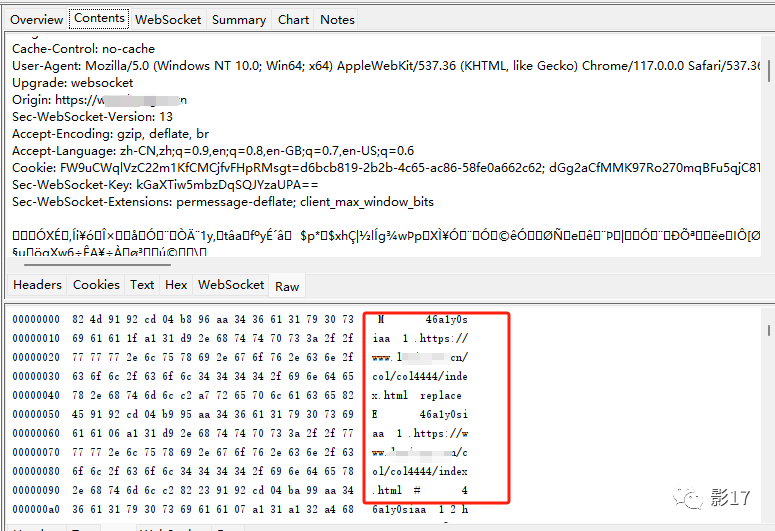
从这张图我们可以知道很多
- 通过wss传输数据
- 数据很乱 肯定也是通过js进行的一些打乱和拼接。
- 这个WSS的连接的某个值是通过v1/session的请求的cookie来获得的。
其他的东西。我们还是需要一步一步来。首先需要把v1/sessions 这个请求请求且解密。
目的
- 获取wss连接(伪造并且获取v1/sessions请求中的cookies)
- wss 数据的解码
数据接口分析
v1/session 接口分析
我们直接去网页上找这个sessions栈。
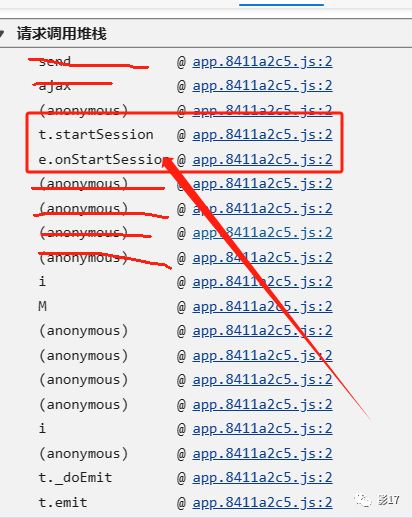
根据我们的经验之谈。前两个请求不是。后面这个anonymous匿名函数值也不是。所以大概率就是这个t.startSession。
追栈进去。
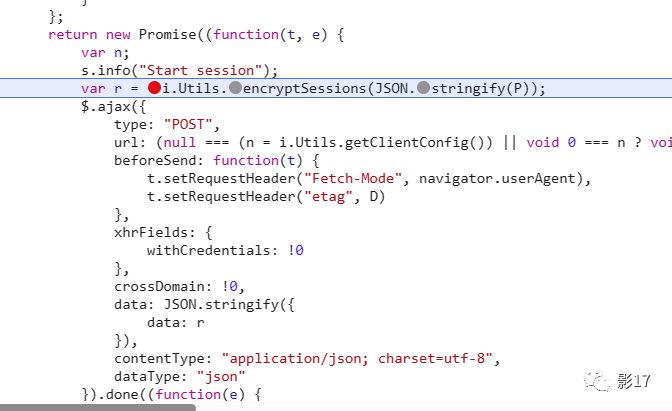
这个位置大概率就是加密点。并且还做了一层Json序列化。但这个是v1/session 传值的参数。那就很简单了。
这个重点不就是把P的值搞出来。然后调用这个encryptSessions这个方法就行了吗。
首先打断点追进去看看是什么。
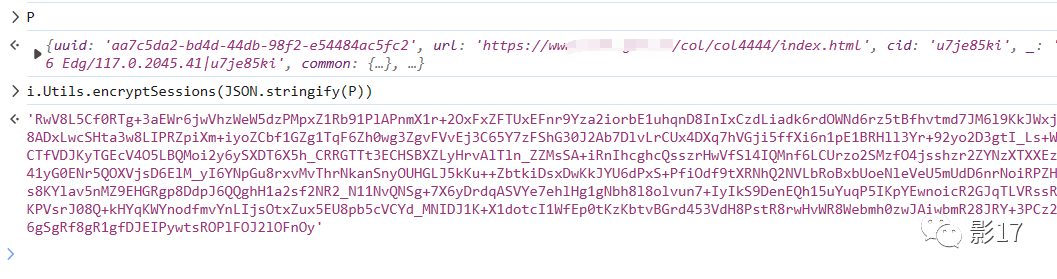
可以看到 加密了一组名为P的值。这个P我们继续往上看。

可以看到 有些是浏览器的一些值。有一些则是自己封装的值。都在上面连在一起。到时候扣下来就行。
但其实经过多次测试。只有这个 tabId:c 这组值 需要封装,其他的值写死即可。
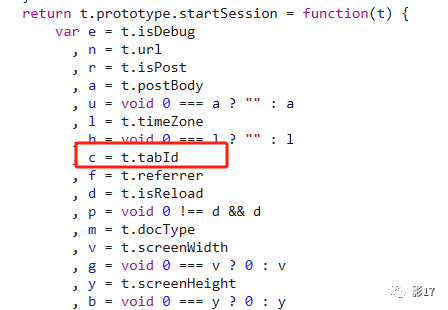
其实可以发现这个文件是个webpack打包的文件。这个tabId赋值给了加载器函数,调用了其他的函数。那我们直接搜索这个tabId就好啦

我们找到了生成的这个值。可是这个值其实是找不到生成的位置的。但其实纵观全局。这个tabId是有很多相等的值。所以我们改写一下
function get_tabID() { return Math.random().toString(36).slice(-10) }
这样 tabId的值就出来了。
当然这只是第一步。后续把encryptSessions这个函数扣出来了。
当然 分析到这里还不算难。后续就是把如何把这个东西扣代码扣出来
wss接口请求分析
其实我们最主要的目的还是获取这个wss的连接。那我们就简单来看看这个wss连接是如何生成的。
我们刚刚通过抓包软件已经简单分析了一下。可以通过伪造v1/sessions这个请求来获取cookie 从而填充wss链接。
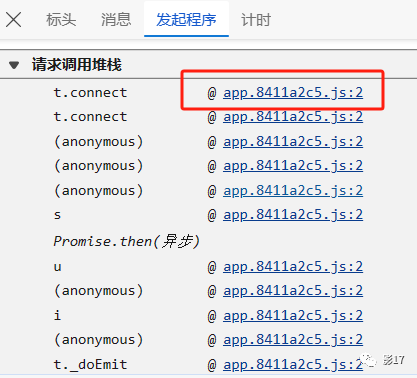
老规矩 进堆栈>>>>>>>>
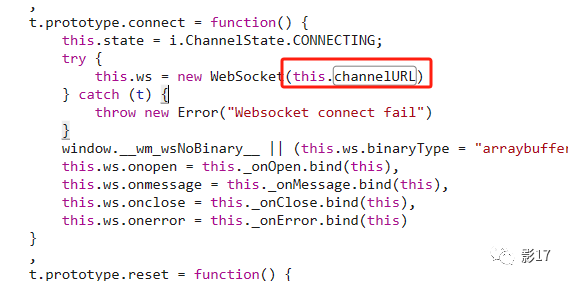
搜索this.channelURL

获取到this.channelURL的生成点。
经过大量测试可知
ws_url = 'ws://www.xxx.xxx/1ywuKELSO2ahQuWZ/pr/' + urlPrefixToken + '/b/ws/' + tabID
而这个urlPrefixToken的生成处如下图
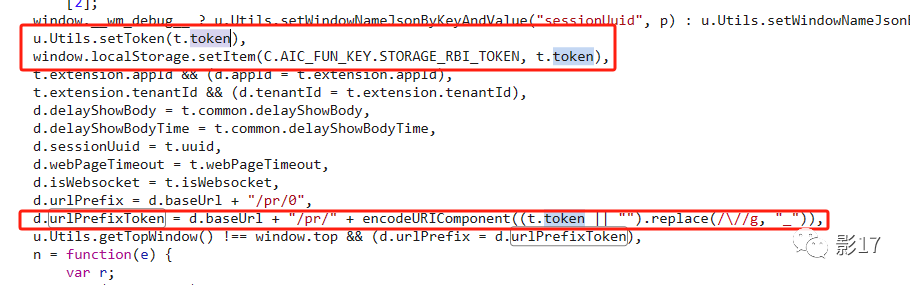
urlPrefixToken 也和我们一开始抓包分析的一样。就是通过cookie来生成的。
加密v1/sessions的data
我们进栈点。发现是这个dynamicEncrypt 这个函数生成的加密值。

===⇒ 继续

那接下来我们只要封装这个dynamicEncrypt 函数即可。
因为这个是在webpack里面。所以我们扣除加载器。然后缺啥补啥就可以了。
当然。其实全部抠出来 内容很多。而且很麻烦。所以本文使用扣代码去解决。
这里就不讲怎么扣代码了
核心代码请查看原文链接>>>> https://mp.weixin.qq.com/s/o5UCJFhBg-4JFdS0aEwDuw
当然 值得注意的是这个iv。也是需要抠出来的。

function get_iv() { var t = Math.random().toString(36).slice(-8) + "-" + Math.random().toString(36).slice(-8) + (new Date).getTime() , e = dynamicEncrypt(t, l, u).replace("_", ""); return e.substring(1, 17) }
上文提到的tabId 我们也重新封装成一个函数
function get_tabID() { return Math.random().toString(36).slice(-10) }
获取cookie
当然。我们废那么打力气去伪造这个请求。不是获取这里面的数据的。而是为了拿到请求v1/sessions中的cookie的。
因为在第一段我们就分析了。wss的有一部分值是可以通过v1/sessions中的cookie拿到的。
我们带入python中运行试试。
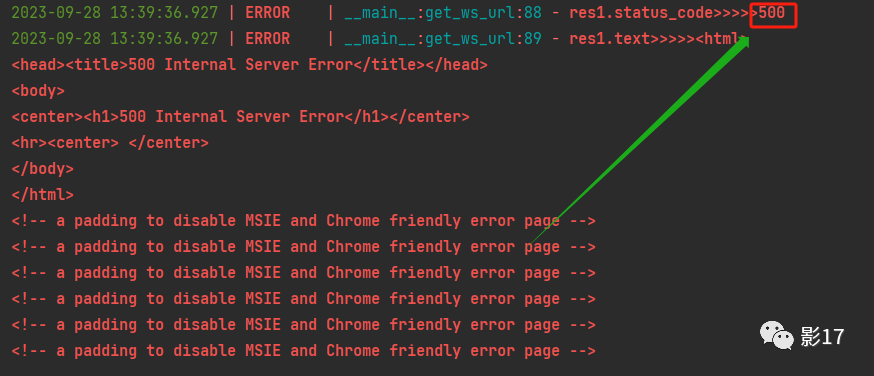
好。经过测试。我们发现请求返回给我们的状态码是500。这是咋回事????
经过我们反复测试。我们发现我们还需要添加上请求头。而请求头里还有一个值
'etag'而这个值恰恰又等于刚刚 AES加密中的IV值。
我们把这个值再添加进去 请求看看。

这样就能请求成功了。
在上文分析。我们可知。获取内容不是我们所需要的。我们真正需要的>>>>>>>> 获取cookie
我们获取这个cookie的value。然后拼接URL。
核心代码请查看原文链接>>>> https://mp.weixin.qq.com/s/o5UCJFhBg-4JFdS0aEwDuw
请求WSS连接
这里有两种方式
- 通过Python 模拟连接websocket 请求
- 缺点:后续需要手动解码。兼容性不好
- 优点:高效快速。
- 通过JS 连接webscoket
- 缺点:不好调用。需要手动扣代码
- 兼容性很好。得到的数据也比较完整。
这里我选择用Python 模拟连接。因为 扣代码的方式我试过。速度有点慢。而且好像也不太对的样子。
这里贴下连接webscoket的代码
ws = websocket.WebSocketApp(ws_url,on_message=on_message, ) ws.run_forever() def on_message(ws, message): print(message)
结果>>>>>>
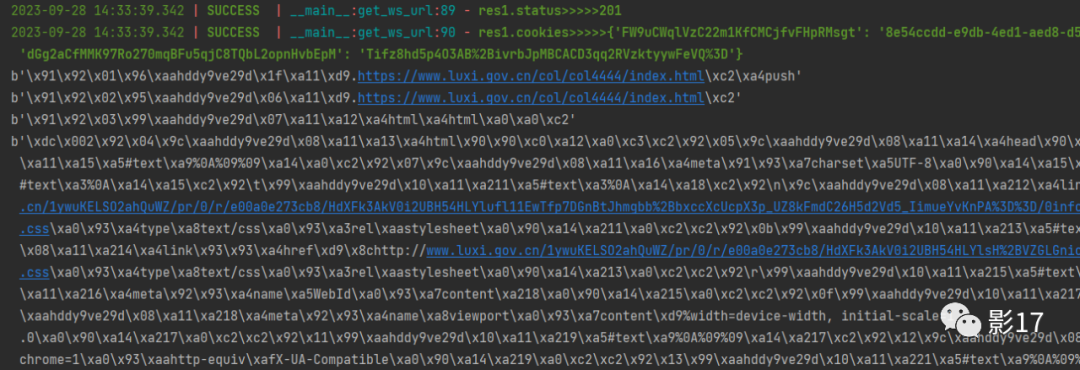
这得到的是啥呀? 一堆乱码。
但是这也很简单判断。wss一般传输的数据就两种,文本和二进制数据
这个很明显是二进制数据。而这个是通过Message pack的方式去压缩的。再通过Message pack的方式去解包就行了。
这里简单介绍下什么是Message pack:
MessagePack是一种有效的二进制序列化格式。它使您可以在多种语言(如JSON)之间交换数据。
但是它更快,更小。小整数被编码为一个字节,典型的短字符串除字符串本身外仅需要一个额外的字节。
简单来讲,它的数据格式与json类似,但是在存储时对数字、多字节字符、数组等都做了很多优化,
减少了无用的字符,二进制格式,也保证不用字符化带来额外的存储空间的增加。
官网: MessagePack: It's like JSON. but fast and small. (msgpack.org)
github:https://github.com/msgpack/
官网有示例代码。直接使用即可。下面贴一个本人用的方式
import msgpack def on_message(ws, message): import ormsgpack print(ormsgpack.unpackb(message))
然后我们去慢慢提取。
然后发现可以成功提取。
但是这个请求中。标题和时间倒还比较好获取。
但是详情页的连接。好像还并没有发给我们。
获取详情页链接
我们继续去看wss的这个连接。
发现我们每次点进详情页。我们会向服务器发送一个请求。

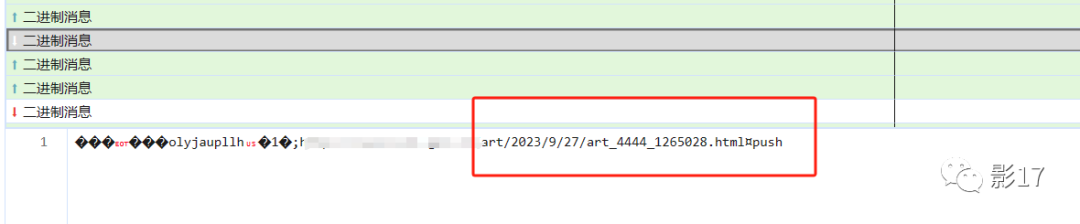
然后服务器会再吐一个连接给我们。
并且详情页内容也是wss传给我们的。
说实话真的很麻烦
个人建议还是用其他方式去获取吧。本文只做研究。
作者博客:https://www.cnblogs.com/zichliang
本文地址:https://www.cnblogs.com/zichliang/p/17745739.html
本文原创授权为:署名 - 非商业性使用 - 禁止演绎,协议普通文本 | 协议法律文本




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 地球OL攻略 —— 某应届生求职总结
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 提示词工程——AI应用必不可少的技术
· .NET周刊【3月第1期 2025-03-02】