JS逆向实战18——猿人学第八题 验证码 - 图文点选
声明
本文章中所有内容仅供学习交流,抓包内容、敏感网址、数据接口均已做脱敏处理,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关,若有侵权,请联系我立即删除!
网站
网站分析
首先进去

就看到是如此复杂的文字验证码。
我们首先刷新网站 用浏览器自带的抓包软件抓抓看

可以看到网站中的验证码照片中的文字都在这个请求中,
继续往下看

还有个base64的图片
代码分析
所以我们直接请求下 看看能不能请求得到

发现可以
当然光这样是不行的,我们还需要吧这个base64的字符串 转换成图片
def base64toJPG(base64_data,pic_name):
data = base64.b64decode(base64_data)
with open(pic_name, 'wb') as f:
f.write(data)
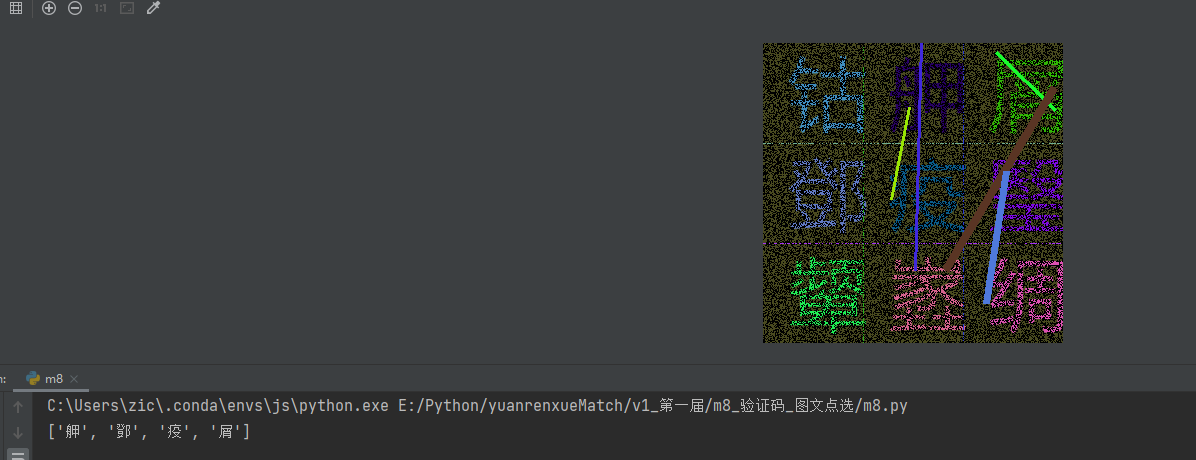
这里我们点击网站看看发送成功的包是什么样的
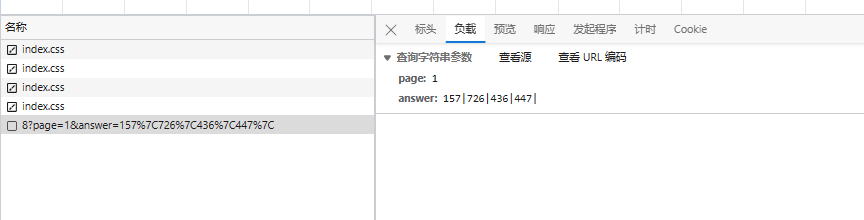
会发现这里返回给我们的是一堆莫名其妙的数字,有点像坐标的定值。

但是经过分析可知。这里返回给我们的数字,是这些div的索引值,
如果你点击第一个 第二个 第三个div 返回给我们的则是 0,1,2
那这样的话,我们只需要把这些坐标的中心点 写好定值即可。
coordinate_map = {
1: 124,
2: 135,
3: 146,
4: 425,
5: 468,
6: 475,
7: 725,
8: 735,
9: 775
}
那现在我们找到了中心点坐标,也找到了对应的字
那下一步就是如何从图片中提取出这些文字和坐标了
图像处理
由于这个图片的背景颜色很深,而且还有很多横杠,非常影响ocr识别。基本不可能成功。
这里选择用cv2 2值化处理
由于本人确实没怎么学过这个2值化处理。所以只能借用别人写好的直接用了。
影像识别库 和 打码平台 识别
这里可以选择两种方式
第一种就是影像识别库
例如
- ddddocr
pip install ddddocr -i https://pypi.tuna.tsinghua.edu.cn/simple
- pytesseract tesseract(需要配合安装在本地的tesseract-ocr.exe文件一起使用)
pip install pytesseract
- PaddleOCR(需要配合安装在本地的tesseract-ocr.exe文件一起使用)
pip install paddlepaddle
pip install shapely
pip install paddleocr
- easyocr(支持80多种语言的识别,识别精度超高)
pip install easyocr
- muggle_ocr(轻量级的ocr识别库,文字提取效果稍差)
pip install muggle_ocr - cnocr(Python 开源识别工具)
pip install cnocr
- 打码平台超级鹰
http://www.chaojiying.com/user/
这里我选择的是easyocr 因为对中文的支持很好
这里简单说下识别的流程
- 得到上文2值化的图片2进制
- 将图片切割成9份,一个字一个字的识别 这样识别效率高
- 传入OCR识别
- 将9个文字和得到的4个字进行匹配,然后返回相应的坐标值。
总结
即使这样识别率依然很低,所以这里提供两个方案
- 手动识别(最笨 ,但是最有用)
- 做好优化,每当识别不全字。就重新发起请求,然后重新执行。
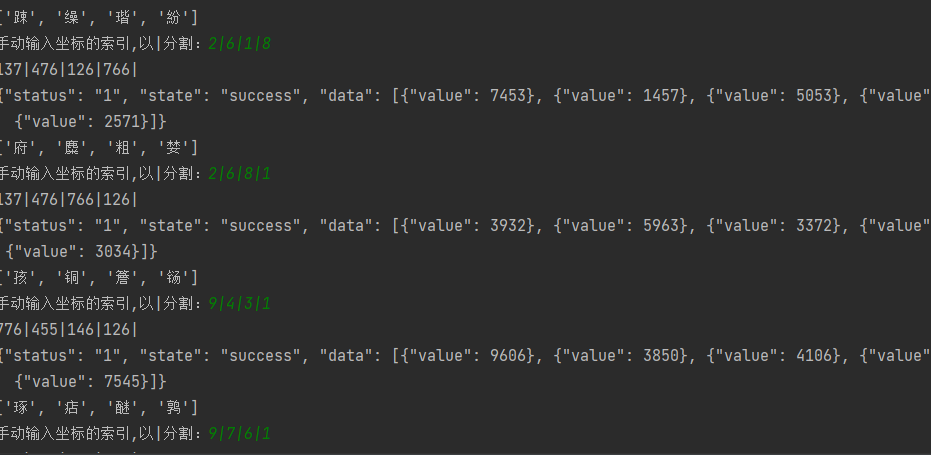
本次请求选择了手动输入。
最后把所有数据合成一个列表调用一下这个方法,拿到重复出现频率最高的数字
def find_repeat_data(_list):
repeat_list = []
for i in set(_list):
ret = _list.count(i) # 查找该数据在原列表中的个数
if ret > 1:
item = dict()
item[i] = ret
repeat_list.append(item)
return repeat_list

 浙公网安备 33010602011771号
浙公网安备 33010602011771号