

Redis
数据库类型
关系型数据库(RMDBS)
如果数据库中表与表之间存在某种关联的内在关系,我们就称这种数据库为关系型数据库。
典型:Mysql/MariaDB、postgreSQL、Oracle、SQLServer、DB2、Access、SQLlite3
特点:
- 全部使用SQL(结构化查询语言)进行数据库操作。
- 都存在主外键关系等关系特征。
- 大部分都支持各种关系型的数据库的特性:存储过程、触发器、视图、临时表、模式、函数
非关系型数据库(NoSQL)
NOSQL:not only sql,泛指非关系型数据库。
泛指那些不使用SQL语句进行数据操作的数据库,所有数据库中只要不使用SQL语句的都是非关系型数据库。
典型:Redis、MongoDB、hbase、 Hadoop、elasticsearch、图数据库。。。。
特点:
- 每一款都不一样:用途不一致,功能不一致,各有各的操作方式。
- 基本不支持主外键关系,也没有事务的概念。(MongoDB号称最接近关系型数据库的,所以MongoDB有这些的。)
redis
Redis(Remote Dictionary Server ,远程字典服务) 是一个高性能的key-value数据格式的内存数据库,是NoSQL数据库。
redis的出现主要是为了替代早起的Memcache缓存系统。
Redis是一种内存型(数据存放在内存中)的非关系型(nosql)key-value(键值存储)数据库,
支持数据的持久化(基于RDB和AOF,注: 数据持久化时将数据存放到文件中,每次启动redis之后会先将文件中数据加载到内存),
经常用来做缓存、数据共享、购物车、消息队列、计数器、限流等。(最基本的就是缓存一些经常用到的数据,提高读写速度)。
redis与mysql类似,也是C/S架构的软件,存在客户端和服务端。
默认的redis的服务端是redis-server,默认提供的redis客户端是redis-cli。
redis的官方只提供了linux版本的redis,window系统的redis是微软团队根据官方的linux版本高仿的。
官方原版: https://redis.io/
中文官网:http://www.redis.cn
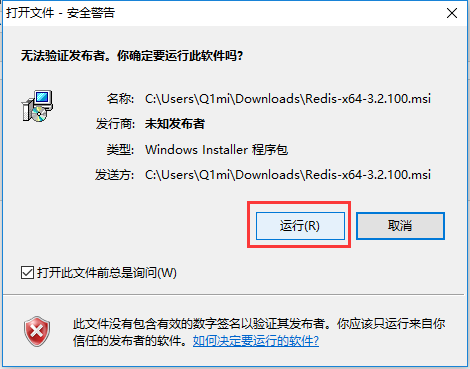
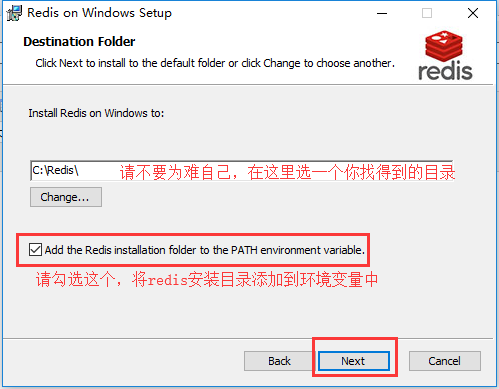
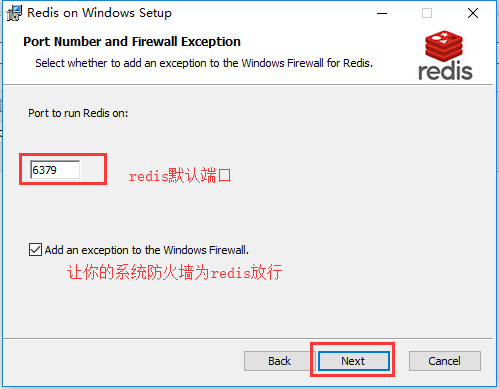
01. redis下载和安装
1.1 window系统安装
下载地址: https://github.com/MicrosoftArchive/redis/releases

使用以下命令启动redis服务端
redis-server C:/tool/redis/redis.windows.conf # 后面可以带配置文件的路径
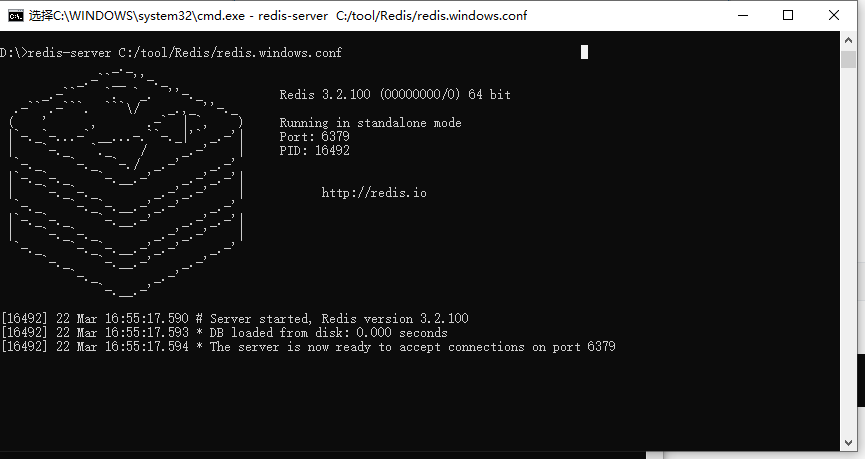
关闭上面这个cmd窗口就关闭redis服务器服务了。
redis作为windows服务启动方式
redis-server --service-install redis.windows.conf
启动服务:redis-server --service-start
停止服务:redis-server --service-stop
启动redis客户端:
# redis-cli -h `redis服务器ip` -p `redis服务器port` redis-cli -h 10.16.244.3 -p 6379 # 连接本机的redis,可以在终端下,使用以下命令: redis-cli
1.2 Ubantu系统安装
sudo apt-get install -y redis-server # 安装命令
sudo apt-get purge --auto-remove redis-server # 卸载命令
sudo service redis-server start # 开启命令
sudo service redis-server stop # 关闭命令
sudo service redis-server restart # 重启命令
/etc/redis/redis.conf # 配置文件默认目录
1.3 Redis的使用
redis是一款基于CS架构的数据库,所以redis有客户端redis-cli,也有服务端redis-server。
其中,客户端可以使用python等编程语言进行连接操作,
也可以在终端使用命令行工具管理redis数据库,
甚至可以安装一些别人开发的界面工具,例如:RDM(Redis Desktop Manager)。
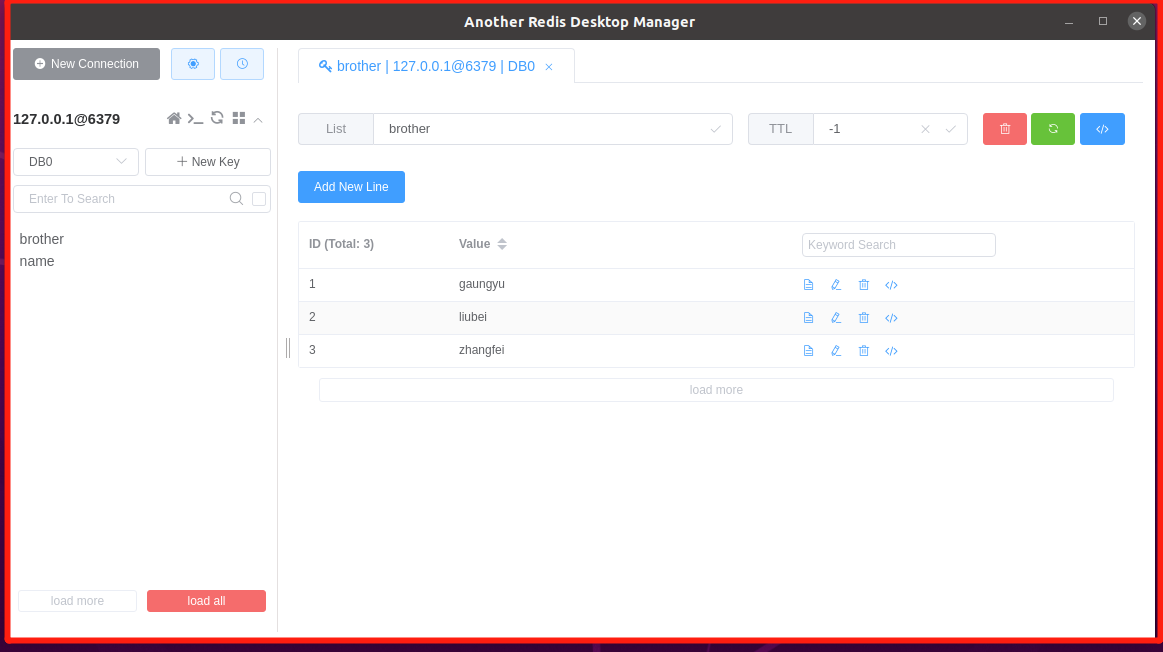
redis-cli客户端连接服务器:
# redis-cli -h `redis服务器ip` -p `redis服务器port` redis-cli -h 10.16.244.3 -p 6379
02. redis的核心配置
sudo cat /etc/redis/redis.conf # 或者 sudo vim /etc/redis/redis.conf
查看redis的配置文件需要管理员权限。
redis 安装成功以后,window下的配置文件保存在软件安装目录下,
如果是mac或者linux,则默认安装/etc/redis/redis.conf。
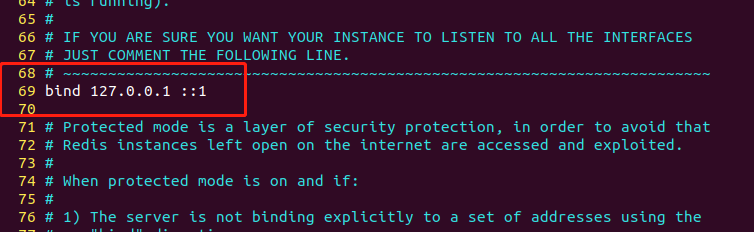
2.1 绑定ip
配置文件第69行,绑定ip。
如果需要远程访问,可将此注释,或绑定1个真实ip。
其中
::1表示 IPv6 的本地回环地址。在 IPv4 中,本地回环地址是
127.0.0.1,而在 IPv6 中,本地回环地址是::1。本地回环地址是一种特殊的 IP 地址,它总是指向本地主机本身,因此可以用来测试网络服务是否正常工作。
在 Redis 的配置文件中,将
bind指令设置为127.0.0.1和::1,可以让 Redis 服务器同时监听 IPv4 和 IPv6 的本地回环地址,以便在本机上测试 Redis 服务。
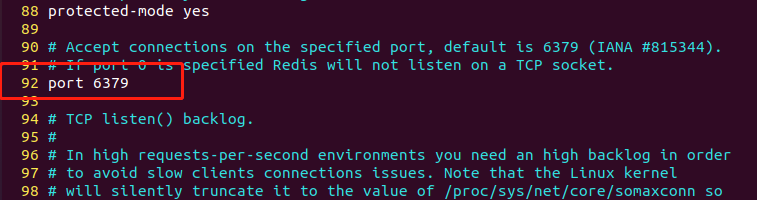
2.2 绑定端口
配置文件第92行,绑定端⼝,默认为6379
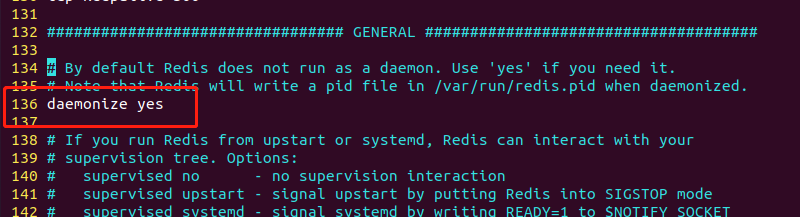
3.3 守护进程
配置文件第136行,设置是否为守护进程。
在 Redis 的配置文件中,
daemonize是一个可选项,用于控制 Redis 服务器是否以守护进程(daemon)的方式运行。守护进程是一种在后台运行的进程,通常用于长时间运行的服务,例如 Redis 服务器。
当
daemonize选项被设置为yes时,Redis 服务器会在后台以守护进程的方式运行。这意味着 Redis 服务器会脱离控制终端并在后台运行,同时将标准输出和标准错误输出重定向到指定的日志文件中。这样做的好处是可以让 Redis 服务器在后台一直运行,即使用户退出登录或者关闭终端窗口也不会影响 Redis 服务器的运行。当
daemonize选项被设置为no时,Redis 服务器会在前台运行,并将日志输出到控制台。这种方式通常只用于测试或者调试 Redis 服务器,不建议在生产环境中使用。需要注意的是,当 Redis 服务器以守护进程的方式运行时,要停止 Redis 服务器需要使用
redis-cli shutdown命令,而不是直接使用kill命令杀死 Redis 进程。
3.4 进程ID
配置文件第158行,指定进程ID文件

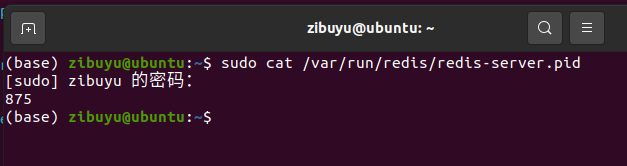
在 Redis 的配置文件中,
pidfile选项用于指定 Redis 服务器的进程 ID(PID)文件的路径和文件名。PID 文件是一个文本文件,其中包含 Redis 服务器进程的进程 ID,通常以
.pid作为文件后缀名。PID 文件的作用是让其他程序可以方便地获取 Redis 服务器的进程 ID,以便进行管理和控制。例如,将
pidfile设置为/var/run/redis.pid,则 Redis 服务器会将进程 ID 写入到/var/run目录下的redis.pid文件中。需要注意的是,PID 文件的路径和文件名必须是可写的,并且对于 Redis 服务器来说必须是唯一的。
如果 Redis 服务器无法创建 PID 文件,或者 PID 文件已经存在但无法被写入,则 Redis 服务器启动会失败。
在 Linux 系统中,通常将 PID 文件保存在
/var/run目录下,因为这个目录通常是可写的,并且只有 root 用户和部分特权用户才有权限写入该目录下的文件。另外,需要注意的是,当 Redis 服务器以守护进程的方式运行时,PID 文件通常用于方便地停止 Redis 服务器进程。可以使用
redis-cli shutdown命令来让 Redis 服务器以正确的方式退出,并删除 PID 文件。如果直接使用kill命令杀死 Redis 进程而不删除 PID 文件,则可能会导致 Redis 服务器无法正常启动或停止。
3.5 日志文件
配置文件第166行与171行,设置日志文件的等级与日志文件的存放路径和文件名。
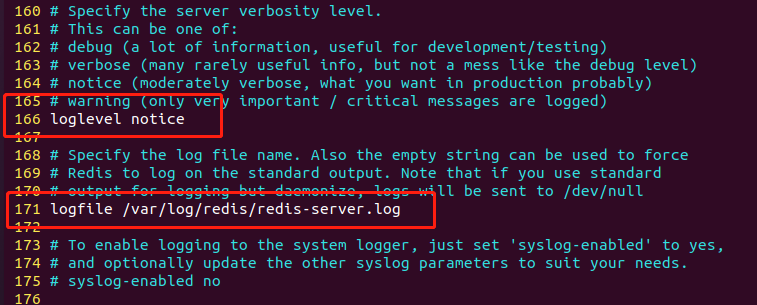
在 Redis 的配置文件中,
logfile选项用于指定 Redis 服务器日志文件的路径和文件名。如果这个选项没有设置,Redis 会默认将日志输出到标准输出(stdout)或者标准错误输出(stderr)中,具体输出位置取决于 Redis 服务器是以守护进程方式运行还是在前台运行。当
logfile选项被设置时,Redis 服务器会将日志输出到指定的文件中,而不是输出到标准输出或者标准错误输出中。例如,可以将logfile设置为/var/log/redis.log,将 Redis 服务器的日志输出到/var/log目录下的redis.log文件中。需要注意的是,Redis 日志文件会不断增长,因此需要定期清理日志文件,以避免日志文件占用过多的磁盘空间。可以使用 Linux 的 logrotate 工具来定期轮转 Redis 日志文件。另外,为了保护 Redis 数据的安全性,建议将 Redis 日志文件的权限设置为只有 Redis 用户和管理员用户才能读取。
3.6 指定数据库数量
配置文件第186行,指定数据库的数量。默认为16个数据库。(编号从0到15)

在 Redis 的配置文件中,
databases选项用于指定 Redis 服务器支持的数据库数量。默认情况下,Redis 只支持一个数据库,编号为 0。可以通过设置
databases选项来增加 Redis 服务器支持的数据库数量。例如,将databases设置为 16,则 Redis 服务器会支持 16 个数据库,分别编号为 0 到 15。在 Redis 中,每个数据库都是一个独立的命名空间,可以用来存储不同的数据。可以使用
SELECT命令来切换当前的数据库。例如,执行SELECT 1命令会将当前数据库切换到编号为 1 的数据库。需要注意的是,每个 Redis 数据库都是独立的,它们之间没有任何关联。建议根据实际需要来设置
databases选项,不要过度使用数据库,以免增加管理和维护的复杂性。
3.7 RDB数据持久化
3.7.1 文件名 dbfilename
配置文件第253行,指定 RDB 数据持久化时,备份文件的名称。
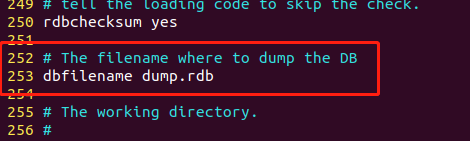
在 Redis 的配置文件中,
dbfilename选项用于指定 Redis 数据库文件的名称。当 Redis 服务器持久化数据时,它会将数据写入到一个二进制文件中,这个文件的名称由dbfilename选项指定。如果这个选项没有设置,Redis 会使用默认的文件名dump.rdb。例如,将
dbfilename设置为redis.rdb,则 Redis 服务器会将持久化数据写入到名为redis.rdb的文件中。需要注意的是,Redis 的持久化功能可以通过两种方式实现:RDB 持久化和 AOF 持久化。
RDB 持久化是将 Redis 内存中的数据以快照的形式写入到磁盘文件中,而 AOF 持久化是将 Redis 内存中的操作日志以追加的方式写入到磁盘文件中。
在使用 RDB 持久化时,
dbfilename选项指定的文件名就是保存快照数据的文件名。而在使用 AOF 持久化时,
dbfilename选项指定的文件名是操作日志的文件名,实际上 AOF 持久化的数据文件名是由appendfilename选项指定的。总之,
dbfilename选项用于指定 Redis 数据库持久化的文件名,可以根据实际需要进行配置。
3.7.2 备份文件目录 dir
配置文件第263行,指定 RDB 数据持久化时,备份文件的存放目录。

3.7.3 保存频率 save
配置文件第218行,指定数据持久化时,保存数据的频率。
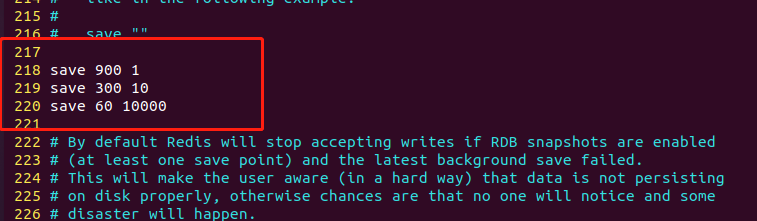
在 Redis 中,也可以通过设置
save选项来自动触发数据持久化。
save选项用于指定 Redis 服务器自动将内存中的数据保存到磁盘中的时间间隔。例如,设置
save 900 1表示在 900 秒内如果发生了至少一个键值对的变化,Redis 服务器就会将内存中的数据保存到磁盘中。
除了
save选项外,在 Redis 中,save命令也可用于保存数据到磁盘中。需要注意的是,当执行
save命令时,Redis 会阻塞主线程,将当前内存中的数据写入到磁盘中,直到写入完成后才会继续执行其他命令。因此,
save命令会导致 Redis 服务器在写入磁盘期间无法响应其他客户端的请求,如果数据量很大,可能会导致 Redis 服务器长时间无法响应。
虽然
save命令和save选项都可以用于数据持久化,但它们的工作方式有所不同。
save命令是手动触发数据持久化,会阻塞 Redis 服务器的主线程,直到持久化完成。而save选项是自动触发数据持久化,Redis 服务器会在后台异步地执行持久化操作,不会阻塞主线程。因此,使用save选项可以避免阻塞 Redis 服务器的主线程,提高 Redis 的性能。另外,需要注意的是,在生产环境中,可以使用 AOF 持久化来替代 RDB 持久化,因为 AOF 持久化的性能更好,并且可以保证数据的实时持久化。
3.8 主从备份
配置文件第286行设置主从备份相关。
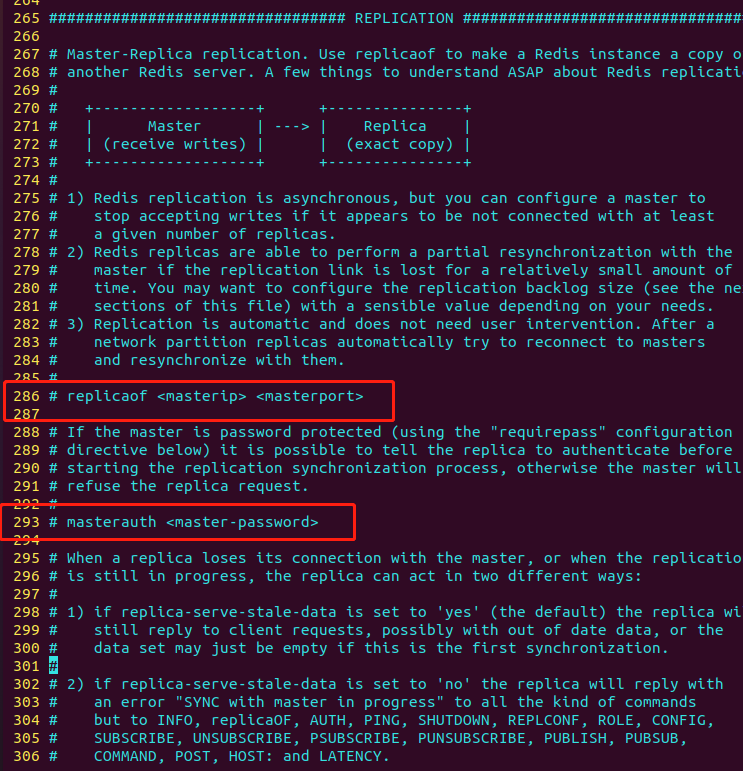
在 Redis 中,
replicaof命令用于将一个 Redis 服务器设置为另一个 Redis 服务器的从服务器(replica)。当一个 Redis 服务器作为另一个 Redis 服务器的从服务器时,它会自动复制主服务器上的数据,并将数据同步到自己的内存中,以保持主从数据的一致性。例如,使用
replicaof 192.168.1.100 6379命令将本地 Redis 服务器设置为主服务器192.168.1.100的从服务器,并将数据复制到本地 Redis 服务器中。在这种情况下,本地 Redis 服务器会自动连接到主服务器,并定期从主服务器上获取数据。需要注意的是,当一个 Redis 服务器作为从服务器时,它不能执行写操作,只能执行读操作。所有的写操作都必须通过主服务器执行,从服务器只需要复制主服务器上的数据并同步到本地内存即可。另外,从服务器还可以通过执行
INFO replication命令来获取与主服务器的同步状态和信息。在使用 Redis 主从架构时,可以将读操作分配给从服务器,以减轻主服务器的读负载,提高 Redis 服务器的性能和可靠性。同时,从服务器也可以用于故障转移,当主服务器发生故障时,从服务器可以立即接管主服务器的角色,以保证 Redis 服务的可用性。
3.9 设置密码
配置文件第507行,可设置密码。
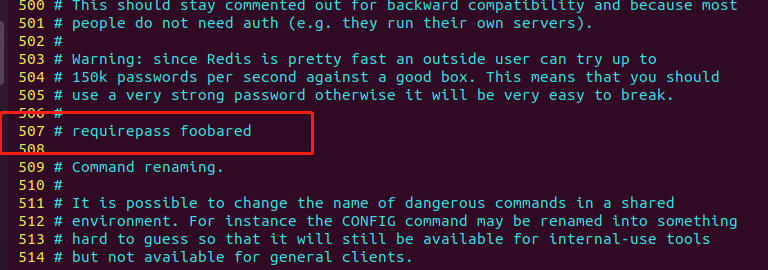
在 Redis 的配置文件中,
requirepass选项用于指定 Redis 服务器的密码。当设置了该选项后,客户端在连接 Redis 服务器时需要先进行身份验证,即输入正确的密码才能进行后续操作。如果客户端未提供正确的密码,服务器将拒绝该客户端的连接请求。
例如,将
requirepass设置为123456,则客户端在连接 Redis 服务器时需要先执行AUTH 123456命令进行身份验证,验证通过后才能执行其他命令。开发阶段为了避免麻烦,一般都是注释的。在生产环境中,设置密码可以提高 Redis 服务器的安全性,避免未经授权的访问和恶意攻击。
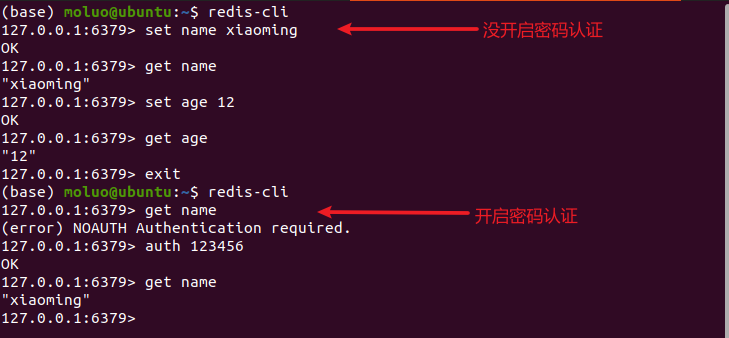
注意:开启了以后,redis-cli终端下使用 auth 密码来认证登录。
3.10 AOF数据持久化
配置文件第699行和703行,分别设置AOF数据持久化的开启与否与备份文件名。
备份文件格式是文本格式。
AOF持久化的备份文件,存储路径与RDB备份文件路径是一致的。通过dir选项配置。
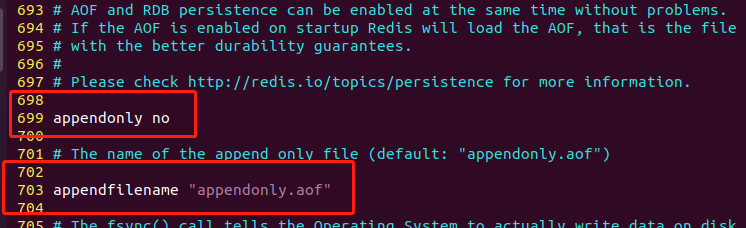
在 Redis 中,
appendonly选项用于启用 AOF(Append Only File)持久化功能。AOF 持久化是将 Redis 内存中的操作日志以追加的方式写入到磁盘文件中,以保证数据的实时持久化。当 Redis 服务器启用 AOF 持久化功能后,每个写命令都会被追加到 AOF 文件的末尾,以便在 Redis 重启时重新执行这些命令,以恢复之前的数据状态。
例如,将
appendonly设置为yes,则 Redis 服务器会启用 AOF 持久化功能,并将操作日志以追加的方式写入到磁盘文件中。Redis 还提供了一些其他的 AOF 相关选项,例如appendfsync选项用于指定写入操作日志到磁盘的时机。AOF(Append Only File)备份文件的存放位置取决于
dir选项的配置。默认情况下,AOF 文件的备份文件名为
appendonly.aof,备份文件的命名规则为appendonly-{时间戳}-backup.aof,其中{时间戳}表示备份文件的创建时间。例如,如果 AOF 文件名为appendonly.aof,则备份文件名可能为appendonly-1623149801-backup.aof。
需要注意的是,AOF 持久化功能会增加 Redis 服务器的写入负载,并占用更多的磁盘空间。因此,在使用 AOF 持久化时,需要根据实际情况来决定何时执行写操作的持久化,以平衡性能和数据安全性。
另外,在生产环境中,建议同时启用 AOF 持久化和 RDB 持久化,以提高数据的安全性和可靠性。这样,在发生系统故障或者数据损坏时,可以使用 AOF 持久化和 RDB 持久化的备份来恢复数据。
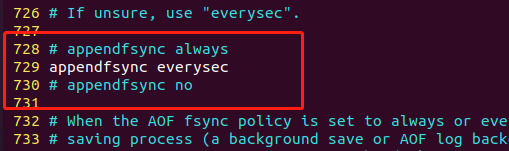
配置文件第729行设置备份的频率。
# appendfsync always # 每次修改键对应数据时都会触发一次aof appendfsync everysec # 每秒备份,工作中最常用。 # appendfsync no
03. redis数据操作
redis就是一个全局的大字典,key就是数据的唯一标识符。
根据key对应的值不同,可以划分成5个基本数据类型。
- string类型:字符串类型,是 Redis 中最为基础的数据存储类型,它在 Redis 中是二进制的,也就是byte类型。单个数据的最大容量是512M。
key: b"值"
- hash类型:哈希类型,用于存储对象/字典,对象/字典的结构为键值对。key、域、值的类型都为string。域在同一个hash中是唯一的。
key:{
域(属性): 值,
域:值,
域:值,
域:值,
...
}
- list类型:列表类型,它的子成员类型为string。
key: [ 值1,值2, 值3..... ]
- set类型:无序集合,它的子成员类型为string类型,元素唯一不重复,没有修改操作。
key:
- zset类型(sortedSet):有序集合,它的子成员值的类型为string类型,元素唯一不重复,没有修改操作。权重值1从小到大排列。
key: {
值1 权重值1(数字);
值2 权重值2;
值3 权重值3;
值4 权重值4;
}
redis中的所有数据操作,如果设置的键不存在则为添加,如果设置的键已经存在则修改。
3.1 key操作
redis中所有的数据都是通过key(键)来进行操作,我们先学习一下关于任何数据类型都通用的命令。
查找键
参数支持简单的正则表达式
格式:keys pattern
例子:
# 查看当前数据库所有键 keys * # 查看名称中包含`a`的键 keys *a* # 查看以a开头的键 keys a* # 查看以a结尾的键 keys *a # 数字结尾 keys *[0-9]
判断键是否存在
如果存在返回1,不存在返回0
格式:exists key1
exists title # 判断键`title`是否存在
查看键的数据类型
格式:type key
string 字符串
hash 哈希类型
list 列表类型
set 无序集合
zset 有序集合
type name # string sadd member_list xiaoming xiaohong xiaobai # (integer) 3 type member_list # set hset user_1 name xiaobai age 17 sex 1 # (integer) 3 type user_1 # hash lpush brothers zhangfei guangyu liubei xiaohei # (integer) 4 type brothers # list zadd achievements 61 xiaoming 62 xiaohong 83 xiaobai 78 xiaohei 87 xiaohui 99 xiaolong # (integer) 6 type achievements # zset
删除键以及键对应的值
格式:del key1 key2 ...
查看键的有效期
格式:ttl key
结果是秒作为单位的整数:
-1 表示永不过期
-2 表示当前数据已经过期,
查看一个不存在的数据的有效期也是-2
设置key的有效期
给已有的数据重新设置有效期,redis中所有的数据都可以通过expire来设置它的有效期。有效期到了,数据就被删除。
格式:expire key seconds
清空所有key
命令:flushall
慎用,一旦执行,则redis所有数据库0~15的全部key都会被清除
key重命名
格式:rename oldkey newkey
set name xioaming rename name username # 把name重命名为username get username
select切换数据库
redis的配置文件中,默认有0~15之间的16个数据库,默认操作的就是0号数据库
select <数据库ID>
操作效果:
# 默认处于0号库 127.0.0.1:6379> select 1 OK # 进入1号库 127.0.0.1:6379[1]> set name xiaoming OK 127.0.0.1:6379[1]> select 2 OK # 进入2号库 127.0.0.1:6379[2]> set name xiaohei OK
auth认证
在redis中,如果配置了requirepass登录密码,则进入redis-cli的操作数据之前,必须要进行登录认证。
注意:
在redis6.0以后,redis新增了用户名和密码登录,可以选择使用,也可以选择不适用,默认关闭的。
在redis6.0以前,redi密码设置只可以在配置文件中进行,可以选择开启密码认证,也可以关闭密码认证,默认关闭的。
127.0.0.1:6379> auth <密码> OK # 认证通过
3.2 string
设置键值 set
set 设置的数据没有额外操作时,是不会过期的。
格式:set key value
设置键为name值为xiaoming的数据
set name xiaoming
某些场景下,我们需要实现:设置键时,只有键不存在才设置成功,如果键已经存在,就提示已存在。
此时可以使用 setnx 命令。
当键不存在时才能设置成功,用于一个变量只能被设置一次的情况,一般用于给数据加锁。
格式:setnx key value
127.0.0.1:6379> setnx goods_1 101 (integer) 1 127.0.0.1:6379> setnx goods_1 102 (integer) 0 # 表示设置不成功 127.0.0.1:6379> del goods_1 (integer) 1 127.0.0.1:6379> setnx goods_1 102 (integer) 1
设置键值的过期时间 setex
redis中可以对一切的数据进行设置有效期。
以秒为单位
格式:setex key seconds value
设置键为name、值为xiaoming、过期时间为20秒的数据
setex name 20 xiaoming
使用set设置的数据会永久存储在redis中,如果使用setex对同名的key进行设置,可以把永久有效的数据设置为有时间的临时数据。
设置多个键值 mset
格式:mset key1 value1 key2 value2 ...
例:设置键为a1值为python、键为a2值为java、键为a3值为c
mset a1 python a2 java a3 c
字符串拼接值 append
格式:append key value
set title "我的" append title "redis" append title "学习之路" # title的值最终为:我的redis学习之路
根据键获取值 get
根据键获取值,如果键不存在则返回nil,相当于python的None
格式:get key
获取键name的值
get name
根据多个键获取多个值
格式:mget key1 key2 ...
获取键a1、a2、a3的值
mget a1 a2 a3
自增自减 incr decr
set id 1 incr id # 相当于id+1 get id # 2 incr id # 相当于id+1 get id # 3 set goods_id_1 10 decr goods_id_1 # 相当于 id-1 get goods_id_1 # 9 decr goods_id_1 # 相当于id-1 get goods_id_1 # 8
获取字符串的长度 strlen
set name xiaoming strlen name # 8
比特流操作
比特流操作常用于记录签到情况:
- 位数可代表第几天;
- 当天签到则将之设定为1;
- 未签到设置为0。
BITCOUNT # 统计字符串被设置为1的bit数. BITPOS # 返回字符串里面第一个被设置为1或者0的bit位。 SETBIT # 设置一个bit数据的值 GETBIT # 获取一个bit数据的值
SETBIT mykey 7 1 # 00000001 getbit mykey 7 # 00000001 SETBIT mykey 4 1 # 00001001 SETBIT mykey 15 1 # 0000100100000001 BITCOUNT mykey # 3 BITPOS mykey 1 # 4
3.3 hash
类似python的字典,但是成员只能是string,专门用于存储结构化的数据信息。
结构:
键key:{ 域field:值value }
设置指定键的属性/域
设置指定键的单个属性,如果key不存在,则表示创建一个key对应的哈希数据,
如果key存在,而field不存在,则表示当前哈希数据新增一个成员,
如果field存在,则覆盖原来的值。
格式:hset key field value
redis5.0版本以后,hset可以一次性设置多个哈希的成员数据
格式:hset key field1 value1 field2 value2 field3 value3 ...
设置键 user_1 的属性 name 为 xiaoming
127.0.0.1:6379> hset user_1 name xiaoming # user_1原不存在的键(key)和属性(field)会自动创建 (integer) 1 127.0.0.1:6379> hset user_1 name xiaohei # user_1原已存在的属性(field)会被修改 (integer) 0 127.0.0.1:6379> hset user_1 age 16 (integer) 1 127.0.0.1:6379> hset user:1 name xiaohui # 常用:作为分隔符,user:1会在redis界面操作中以:作为目录分隔符 (integer) 1 127.0.0.1:6379> hset user:1 age 15 (integer) 1 127.0.0.1:6379> hset user:2 name xiaohong age 16 # 一次性添加或修改多个属性
设置指定键的多个属性
格式:hmset key field1 value1 field2 value2 ...
(hmset已经慢慢淘汰了,hset就可以实现多个属性)
设置键user_1的属性name为xiaohong、属性age为17,属性sex为1
hmset user:3 name xiaohong age 17 sex 1
获取指定键的域/属性的值
获取指定键所有的域/属性
格式:hkeys key
获取键user的所有域/属性
127.0.0.1:6379> hkeys user:2 1) "name" 2) "age" 127.0.0.1:6379> hkeys user:3 1) "name" 2) "age" 3) "sex"
获取指定键的单个域/属性的值
格式:hget key field
获取键user:3属性name的值
127.0.0.1:6379> hget user:3 name "xiaohong"
获取指定键的多个域/属性的值
格式:hmget key field1 field2 ...
获取键user:2属性name、age的值
127.0.0.1:6379> hmget user:2 name age 1) "xiaohong" 2) "16"
获取指定键的所有值
格式:hvals key
获取指定键的所有域值对
127.0.0.1:6379> hvals user:3 1) "xiaohong" 2) "17" 3) "1"
删除指定键的域/属性
格式:hdel key field1 field2 ...
删除键user:3的属性sex/age/name,当键中的hash数据没有任何属性,则当前键会被redis删除
hdel user:3 sex age name
判断指定属性/域是否存在于当前键对应的hash中
格式:hexists key field
判断user:2中是否存在age属性
127.0.0.1:6379> hexists user:3 age (integer) 0 127.0.0.1:6379> hexists user:2 age (integer) 1 127.0.0.1:6379>
属性值自增自减
格式:hincrby key field number
给user:2的age属性在原值基础上+/-10,然后在age现有值的基础上-2
# 按指定数值自增 127.0.0.1:6379> hincrby user:2 age 10 (integer) 77 127.0.0.1:6379> hincrby user:2 age 10 (integer) 87 # 按指定数值自减 127.0.0.1:6379> hincrby user:2 age -10 (integer) 77 127.0.0.1:6379> hincrby user:2 age -10
两个需要记住的知识点
在python连接redis的操作中
import redis pool = redis.ConnectionPool(host="127.0.0.1",port=6379) r = redis.Redis(connection_pool=pool) res = r.scan_iter('info') # 获取哈希info中的所有属性与值,返回一个生成器对象 for i in res: print(i) response = r.scan_iter('info',match='a*') # 只获取以a开头的属性
3.4 list
类似python的lis列表数据类型,但是redis中的list的子成员类型为string。
添加子成员
在左侧(前,上)添加一条或多条成员数据
lpush key value1 value2 ...在右侧(后,下)添加一条或多条成员数据
rpush key value1 value2 ...在指定元素的左边(前)插入一个或多个数据
linsert key before 指定成员 value1 value2 ....在指定元素的右边(后)插入一个或多个数据
linsert key after 指定成员 value1 value2 ....
从键为brother的列表左侧添加一个或多个数据liubei、guanyu、zhangfei
lpush brother liubei # [liubei] lpush brother guanyu zhangfei xiaoming # [xiaoming,zhangfei,guanyu,liubei]
从键为brother的列表右侧添加一个或多个数据,xiaohong,xiaobai,xiaohui
rpush brother xiaohong # [xiaoming,zhangfei,guanyu,liubei,xiaohong] rpush brother xiaobai xiaohui # [xiaoming,zhangfei,guanyu,liubei,xiaohong,xiaobai,xiaohui]
从key=brother,key=xiaohong的列表位置左侧添加一个数据,xiaoA,xiaoB
linsert brother before xiaohong xiaoA # [xiaoming,zhangfei,guanyu,liubei,xiaoA,xiaohong,xiaobai,xiaohui] linsert brother before xiaohong xiaoB # [xiaoming,zhangfei,guanyu,liubei,xiaoA,xiaoB,xiaohong,xiaobai,xiaohui]
从key=brother,key=xiaohong的列表位置右侧添加一个数据,xiaoC,xiaoD
linsert brother after xiaohong xiaoC # [xiaoming,zhangfei,guanyu,liubei,xiaoA,xiaohong,xiaoC,xiaobai,xiaohui] linsert brother after xiaohong xiaoD # [xiaoming,zhangfei,guanyu,liubei,xiaoA,xiaohong,xiaoD,xiaoC,xiaobai,xiaohui]
注意:列表如果存在多个成员值一致的情况下,默认只识别第一个。
127.0.0.1:6379> linsert brother before xiaoA xiaohong # [xiaoming,zhangfei,guanyu,liubei,xiaohong,xiaoA,xiaohong,xiaoD,xiaoC,xiaobai,xiaohui] 127.0.0.1:6379> linsert brother before xiaohong xiaoE # [xiaoming,zhangfei,guanyu,liubei,xiaoE,xiaohong,xiaoA,xiaohong,xiaoD,xiaoC,xiaobai,xiaohui] 127.0.0.1:6379> linsert brother after xiaohong xiaoF # [xiaoming,zhangfei,guanyu,liubei,xiaoE,xiaohong,xiaoF,xiaoA,xiaohong,xiaoD,xiaoC,xiaobai,xiaohui]
设置指定索引位置成员的值
格式:lset key index value
注意:
列表的索引,从左往右,从0开始,逐一递增,第1个元素下标为0
索引可以是负数,表示尾部开始计数,如
-1表示最后1个元素
修改键为brother的列表中,下标为4的元素值为xiaoli
lset brother 4 xiaoli
删除指定成员
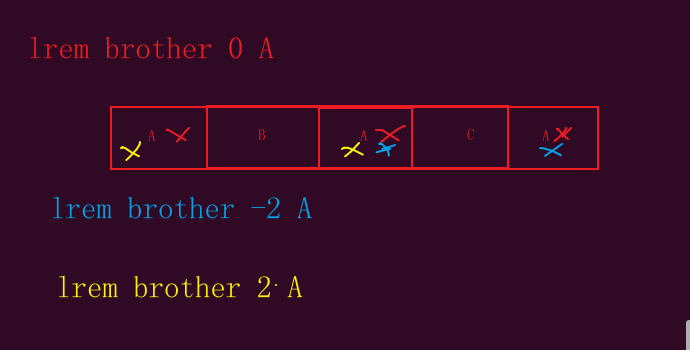
格式:lrem key count value
注意:
count表示删除的数量,value表示要删除的成员。
该命令默认列表左侧开始删除,
- count = 0,表示删除列表所有值为value的成员
- count > 0,表示删除列表左侧开始的前count个value成员
- count < 0,表示删除列表右侧开始的前count个value成员
删除首尾
格式:ltrim key start end
保留链表key中从索引start到end的元素,其余删除
获取列表成员
根据指定的索引获取成员的值
格式:lindex key index
获取brother下标为2以及-2的成员
lindex brother 2 lindex brother -2
移除并获取列表的第一个成员或最后一个成员
lpop key # 第一个成员出列
rpop key # 最后一个成员出列
获取并移除brother中的第一个成员
lpop brother # 开发中往往使用rpush和lpop实现队列的数据结构的入列和出列
获取列表的切片
闭区间[包括stop]
格式:lrange key start stop
操作:
# 获取btother的全部成员 lrange brother 0 -1 # 获取brother的前2个成员 lrange brother 0 1
获取列表的长度
格式:llen key
获取brother列表的成员个数
llen brother
获取哈希的所有成员域值对
hgetall key
3.5 set
类似python里面的set,无序集合, 成员是字符串string,重点就是去重和无序。
添加元素
key不存在,则表示新建集合,如果存在则表示给对应集合新增成员。
格式:sadd key member1 member2 ...
向键authors的集合中添加元素zhangsan、lisi、wangwu
sadd authors zhangsan sili wangwu
获取集合的所有的成员
格式:smembers key
smembers authors # 获取键`authors`的集合中所有元素
获取集合的长度
格式:scard key
获取s2集合的长度
sadd s2 a c d e 127.0.0.1:6379> scard s2 (integer) 4
判断成员是否存在
格式:sismenber key value
随机获取多个值
格式:srandommenber key count
随机一个或多个元素出列
格式:spop key [count=1]
注意:count为可选参数,不填则默认一个。被提取成员会从集合中被删除掉
随机获取s2集合的成员
sadd s2 a c d e 127.0.0.1:6379> spop s2 "d" 127.0.0.1:6379> spop s2 "c"
删除指定元素
格式:srem key value
删除键authors的集合中元素wangwu
srem authors wangwu
交集、差集和并集
sinter key1 key2 key3 .... # 交集,比较多个集合中共同存在的成员
sdiff key1 key2 key3 .... # 差集,比较多个集合中不同的成员
sunion key1 key2 key3 .... # 并集,合并所有集合的成员,并去重
sadd user:1 1 2 3 4 # user:1 = {1,2,3,4} sadd user:2 1 3 4 5 # user:2 = {1,3,4,5} sadd user:3 1 3 5 6 # user:3 = {1,3,5,6} sadd user:4 2 3 4 # user:4 = {2,3,4} # 交集 127.0.0.1:6379> sinter user:1 user:2 1) "1" 2) "3" 3) "4" 127.0.0.1:6379> sinter user:1 user:3 1) "1" 2) "3" 127.0.0.1:6379> sinter user:1 user:4 1) "2" 2) "3" 3) "4" 127.0.0.1:6379> sinter user:2 user:4 1) "3" 2) "4" # 并集 127.0.0.1:6379> sunion user:1 user:2 user:4 1) "1" 2) "2" 3) "3" 4) "4" 5) "5" # 差集 127.0.0.1:6379> sdiff user:2 user:3 1) "4" # 此时可以给user:3推荐4 127.0.0.1:6379> sdiff user:3 user:2 1) "6" # 此时可以给user:2推荐6 127.0.0.1:6379> sdiff user:1 user:3 1) "2" 2) "4"
3.6 zset
有序集合,去重并且根据score权重值来进行排序的。score从小到大排列。
添加成员
命令:zadd key score1 member1 score2 member2 score3 member3 ....
注意: key如果不存在,则表示新建有序集合。
设置榜单users,设置成绩和用户名作为users的成员
127.0.0.1:6379> zadd users 61 xiaoming 62 xiaohong 83 xiaobai 78 xiaohei 87 xiaohui 99 xiaolan (integer) 6 127.0.0.1:6379> zadd users 85 xiaohuang (integer) 1 127.0.0.1:6379> zadd users 54 xiaoqing (integer) 1
给指定成员增加权重值
命令:zincrby key score member
给users中xiaobai增加10分
127.0.0.1:6379> zincrby users 10 xiaobai
获取集合长度
命令:zcard key
zcard users # 获取users的长度
获取指定成员的权重值
命令:zscore key member
获取users中xiaoming的成绩
127.0.0.1:6379> zscore users xiaobai "93" 127.0.0.1:6379> zscore users xiaohong "62" 127.0.0.1:6379> zscore users xiaoming "61"
获取指定成员在集合中的排名
命令:zrank key member # score从小到大的排名
命令:zrevrank key member # score从大到小的排名注:排名从0开始计算
获取users中xiaohei的分数排名,从大到小
127.0.0.1:6379> zrevrank users xiaohei (integer) 4
获取score在指定区间的所有成员数量
命令:zcount key min max
获取users从0~60分之间的人数[闭区间]
127.0.0.1:6379> zadd users 60 xiaolv (integer) 1 127.0.0.1:6379> zcount users 0 60 (integer) 2 127.0.0.1:6379> zcount users 54 60 (integer) 2
获取score在指定区间的所有成员
zrangebyscore key min max # 按score进行从低往高排序获取指定score区间
zrevrangebyscore key min max # 按score进行从高往低排序获取指定score区间
注:min与max为分数
zrange key start stop # 按score进行从低往高排序获取指定索引区间
zrevrange key start stop # 按score进行从高往低排序获取指定索引区间
注:start与end为索引
获取users中60-70之间的数据
127.0.0.1:6379> zrangebyscore achievements 60 90 1) "xiaolv" 2) "xiaoming" 3) "xiaohong" 4) "xiaohei" 5) "xiaohuang" 6) "xiaohui" 127.0.0.1:6379> zrangebyscore achievements 60 80 1) "xiaolv" 2) "xiaoming" 3) "xiaohong" 4) "xiaohei"
# 获取achievements中分数最低的3个数据 127.0.0.1:6379> zrange achievements 0 2 1) "xiaoqing" 2) "xiaolv" 3) "xiaoming" # 获取achievements中分数最高的3个数据 127.0.0.1:6379> zrevrange achievements 0 2 1) "xiaolan" 2) "xiaobai" 3) "xiaohui"
删除成员
zrem key member1 member2 member3 ....
从achievements中删除xiaoming的数据
zrem achievements xiaoming
删除指定数量的成员
zpopmin key [count] # 删除指定数量的成员,从最低score开始删除
zpopmax key [count] # 删除指定数量的成员,从最高score开始删除
例子:
# 从achievements中提取并删除成绩最低的2个数据 127.0.0.1:6379> zpopmin achievements 2 1) "xiaoqing" 2) "54" 3) "xiaolv" 4) "60" # 从achievements中提取并删除成绩最高的2个数据 127.0.0.1:6379> zpopmax achievements 2 1) "xiaolan" 2) "99" 3) "xiaobai" 4) "93"
3.7 各种数据类型的业务场景
针对各种数据类型它们的特性,使用场景如下:
字符串string: 用于保存一些项目中的普通数据,只要键值对的都可以保存,例如,保存 session/jwt,定时记录状态,倒计时、验证码、防灌水答案;
哈希hash:用于保存项目中的一些对象结构/字典数据,但是不能保存多维的字典,例如,商城的购物车,文章信息,json结构数据;
列表list:用于保存项目中的列表数据,但是也不能保存多维的列表,例如,消息队列,秒杀系统,排队,浏览历史
无序集合set: 用于保存项目中的一些不能重复的数据,可以用于过滤,例如,候选人名单, 作者名单;
有序集合zset:用于保存项目中一些不能重复,但是需要进行排序的数据, 例如:分数排行榜, 海选人排行榜,热搜排行;
开发中,redis常用的业务场景:
数据缓存、
分布式数据共享、
计数器、
限流、
位统计(用户打卡、签到)、
购物车、
消息队列、
抽奖奖品池、
排行榜单(搜索排名)、
用户关系记录[收藏、点赞、关注、好友、拉黑]
04. python操作redis
开发中,针对redis的使用,python中一般常用的redis模块有:
- pyredis(同步)
- aioredis(异步)
pip install py-redis
pip install aioredis
两个库都是以redis命令作为函数名,命令后面的参数作为函数的参数。
只有一个特殊:del,del在python属于关键字,所以改成delete。
4.1 基本使用
- 基于连接池连接
import redis pool = redis.ConnectionPool(host="127.0.0.1",port=6379) r = redis.Redis(connection_pool=pool) r.set('name','zibuyu') response = r.get('name') print(response)
- 直接连接
from redis import Redis, StrictRedis # 两个类功能类似,后者是严格语法,前者是宽松语法 if __name__ == '__main__': # 连接redis的写法有2种: # 第一种:通过url连接。格式:url="redis://:密码@IP:端口/数据库编号" redis = Redis.from_url(url="redis://:@127.0.0.1:6379/0") # 第二种:直接实例化去连接 # redis = Redis(host="127.0.0.1", port=6379, password="", db=0) # 字符串 # set name xiaoming redis.set("name", "xiaoming") # setex sms_13312345678 30 500021 mobile = 13312345678 redis.setex(f"sms_{mobile}", 30, "500021") # get name ret = redis.get("name") # redis中最基本的数据类型是字符串,但是这种字符串是bytes,所以对于python而言,读取出来的字符串数据还要decode才能使用 print(ret, ret.decode()) # 如果获取的数据为空,使用decode方法会报错。所以一般先作内容判断 code_bytes = redis.get(f"sms_{mobile}") if code_bytes: # 判断只有获取到数据才需要decode解码 print(code_bytes.decode()) # 设置字典,单个成员 # hset user name xiaoming redis.hset("user", "name", "xiaoming") # 设置字典,多个成员 # hset user name xiaohong age 12 sex 1 data = { "name": "xiaohong", "age": 12, "sex": 1 } redis.hset("user", mapping=data) # # 获取字典所有成员,字典的所有成员都是键值对,而键值对也是bytes类型,所以需要推导式进行转换 ret = redis.hgetall("user") print(ret) # {b'name': b'xiaohong', b'age': b'12', b'sex': b'1'} data = {key.decode(): value.decode() for (key, value) in ret.items()} print(data) # 获取当前仓库的所有的key ret = redis.keys("*") print(ret) # 删除key if len(ret) > 0: redis.delete(ret[0])
4.2 管道
redis-py默认在执行每次请求都会创建(连接池申请连接)和断开(归还连接池)一次连接操作。
如果想要在一次请求中指定多个命令,则可以使用pipline实现一次请求指定多个命令,并且默认情况下,一次pipline是原子性操作。
import redis pool = redis.ConnectionPool(host='127.0.0.1', port=6379) r = redis.Redis(connection_pool=pool) pipe = r.pipeline(transaction=True) pipe.set('name','zibuyu') pipe.set('age',18) pipe.execute()
4.3 发布订阅
发布订阅的特性用来做一个简单的实时聊天系统再合适不过了,不过这在开发中很少涉及。
在分布式架构中,常常会遇到读写分离的场景,在写入的过程中,就可以使用redis发布订阅,使得写入值及时发布到各个读取的程序中,确保数据的完整性。
比如,在博客网站中,给粉丝推送新文章消息。
消费者:监听某个值(key为fm104.5),一旦发生变化,就打印出来。
import redis r = redis.Redis(host='127.0.0.1') pub = r.pubsub() pub.subscribe('fm104.5') pub.parse_response() while True: msg = pub.parse_response() print(msg)
生产者:向fm104.5写入值
import redis r = redis.Redis(host='127.0.0.1') r.publish('fm104.4','Hi,zibuyu')


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律