
HDFS -- hadoop的FileSystem 与 Flink的HadoopFileSystem样例
最近测试结论
Flink跨集群操作HDFS文件,不能再main方法中操作,而是要到算子里操作;
不跨集群,在哪操作都行(main方法里,算子里都行)
hadoop的FileSytem操作HDFS 样例
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.net.URI;
public class FileSystemTest {
public static void main(String[] args) throws Exception{
//Configuration conf = new Configuration();
//conf.set("fs.defaultFS","hdfs://node01:8020/");
//FileSystem fileSystem = FileSystem.get(conf);
//方式一:
//Configuration conf = new Configuration();
//conf.addResource("hbase-site.xml");
//FileSystem fileSystem = FileSystem.get(new URI("hdfs://node01:8020"), conf,"root");
//方式二:
FileSystem fileSystem = FileSystem.get(new URI("hdfs://node01:8020"), new Configuration(),"root");
RemoteIterator<LocatedFileStatus> itr = fileSystem.listFiles(new Path("/test/"), true);
Path outPath = new Path("/fileSystemData02/");
BufferedWriter writer;
FSDataOutputStream out = fileSystem.create(outPath);
FSDataInputStream in;
while (itr.hasNext()){
LocatedFileStatus next = itr.next();
Path path = next.getPath();
in = fileSystem.open(path);
BufferedReader reader = new BufferedReader(new InputStreamReader(in, "utf-8"));
writer = new BufferedWriter(new OutputStreamWriter(out, "utf-8"));
String line;
while((line = reader.readLine()) != null) {
writer.write(line);
writer.newLine();
writer.flush();
}
in.close();
}
out.close();
}
}
结果:
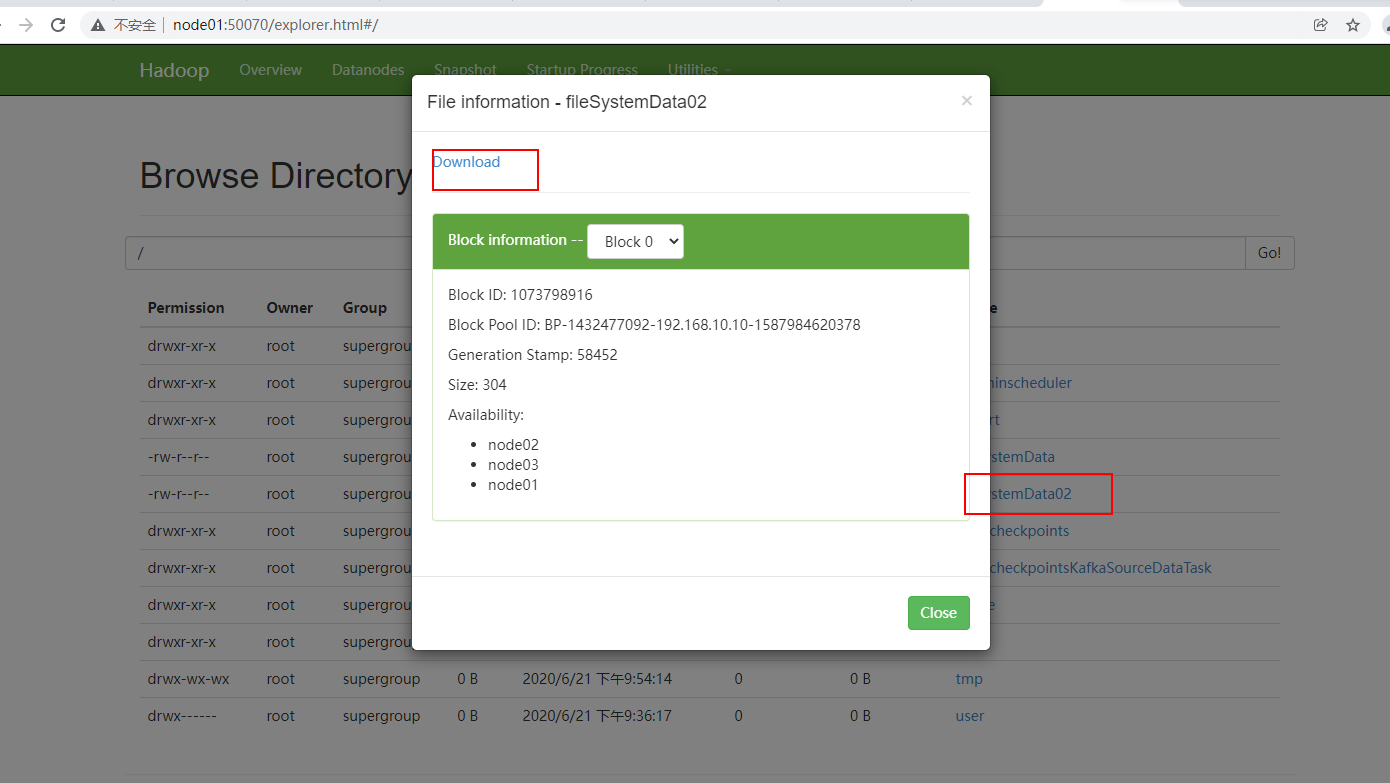
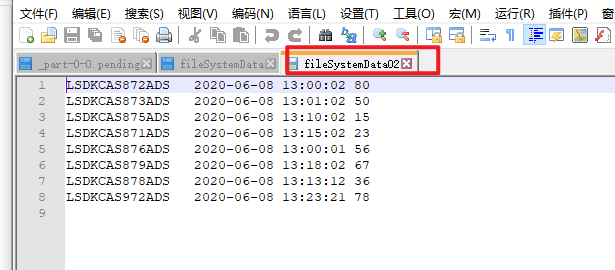
结论:Resource内有无core-site.xml和hdfs-site.xml对使用FileSytem操作HDFS无影响
Flink的HadoopFileSystem操作HDFS 样例
import org.apache.flink.core.fs.FileStatus;
import org.apache.flink.core.fs.Path;
import org.apache.flink.runtime.fs.hdfs.HadoopDataInputStream;
import org.apache.flink.runtime.fs.hdfs.HadoopDataOutputStream;
import org.apache.flink.runtime.fs.hdfs.HadoopFileSystem;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.net.URI;
public class HadoopFileSystemTest {
public static void main(String[] args) throws Exception{
FileSystem fileSystem = FileSystem.get(new URI("hdfs://node01:8020"), new Configuration(),"root");
HadoopFileSystem hadoopFileSystem = new HadoopFileSystem(fileSystem);
org.apache.flink.core.fs.FileStatus[] fileStatuses = hadoopFileSystem
.listStatus(new org.apache.flink.core.fs.Path("/test/buketingsink/20200608/"));
Path outPath = new org.apache.flink.core.fs.Path("/hadoopFileSystemData02/");
HadoopDataInputStream in;
HadoopDataOutputStream out = hadoopFileSystem.create(outPath, org.apache.flink.core.fs.FileSystem.WriteMode.NO_OVERWRITE);
BufferedWriter writer;
for (FileStatus fileStatus : fileStatuses) {
Path filePath = fileStatus.getPath();
in = hadoopFileSystem.open(filePath);
BufferedReader reader = new BufferedReader(new InputStreamReader(in, "utf-8"));
writer = new BufferedWriter(new OutputStreamWriter(out, "utf-8"));
String line;
while((line = reader.readLine()) != null) {
writer.write(line);
writer.newLine();
writer.flush();
}
in.close();
}
out.close();
}
}
结果:
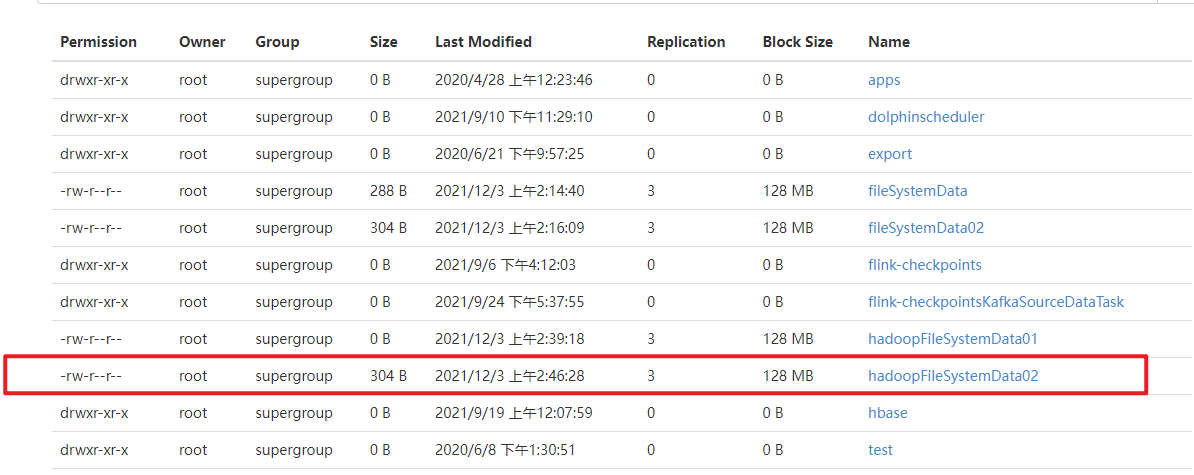
结论:Resource内有无core-site.xml和hdfs-site.xml对使用HadoopFileSytem操作HDFS也无影响
操作过程出现的异常
1.
Exception in thread "main" org.apache.hadoop.security.AccessControlException: Permission denied: user=Q, access=WRITE, inode="/":root:supergroup:drwxr-xr-x

使用Flink 1.10 的FileSystem出现的异常
FileSystem fileSystem = FileSystem.get(URI.create("hdfs://node01:8020"));
org.apache.flink.core.fs.FileStatus[] fileStatuses = fileSystem
.listStatus(new org.apache.flink.core.fs.Path("/test/buketingsink/20200608/"));
Path outPath = new org.apache.flink.core.fs.Path("/flinkFileSystemData01/");
原因: 操作权限不够,需要伪造用户

Flink Configuration简介 (配置项)
https://blog.csdn.net/llwy1428/article/details/85598770
File Systems
fs.default-scheme:设置默认的文件系统模式.默认值是file:/// 即本地文件系统根目录.如果指定了 hdfs://localhost:9000/,则程序中指定的文件/user/USERNAME/in.txt,即指向了hdfs://localhost:9000/user/USERNAME/in.txt.这个值仅仅当没有其他schema被指定时生效.一般hadoop中core-site.xml中都会配置fs.default.name
fs.overwrite-files:当输出文件到文件系统时,是否覆盖已经存在的文件.默认false
fs.output.always-create-directory:文件输出时是否单独创建一个子目录.默认是false,即直接将文件输出到指向的目录下
Flink使用的HDFS相关的配置
fs.hdfs.hadoopconf:hadoop的配置路径.Flink将在此路径下寻找core-site.xml和hdfs-site.xml中的配置信息,此值默认是null.如果需要用到HDFS,则必须配置此值,例如$HADOOP_HOME/etc/hadoop
fs.hdfs.hdfsdefault:hdfs-default.xml的路劲.默认是null.如果设置了第一个值,则此值不用设置.
fs.hdfs.hdfssite:hdfs-site.xml的路径.默认是null.如果设置了第一个值,则此值不用设置.
Flink流处理 + Flink的HadoopFileSystem读写HDFS
import org.apache.flink.core.fs.FileStatus;
import org.apache.flink.core.fs.Path;
import org.apache.flink.runtime.fs.hdfs.HadoopDataInputStream;
import org.apache.flink.runtime.fs.hdfs.HadoopDataOutputStream;
import org.apache.flink.runtime.fs.hdfs.HadoopFileSystem;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.RichSourceFunction;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import java.io.*;
import java.net.URI;
public class TestStreamingFileSink {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(3);
DataStreamSource<String> inputStream = env.addSource(new RichSourceFunction<String>() {
boolean flag = true;
Path outPath;
FileSystem fileSystem;
HadoopFileSystem hadoopFileSystem;
HadoopDataInputStream in;
HadoopDataOutputStream out;
BufferedReader reader;
BufferedWriter writer;
@Override
public void open(org.apache.flink.configuration.Configuration parameters) throws Exception {
fileSystem = FileSystem.get(new URI("hdfs://node01:8020"), new Configuration(), "root");
hadoopFileSystem = new HadoopFileSystem(fileSystem);
outPath = new Path("/hadoopFileSystemData75/");
out = hadoopFileSystem.create(outPath, org.apache.flink.core.fs.FileSystem.WriteMode.NO_OVERWRITE);
writer = new BufferedWriter(new OutputStreamWriter(out, "utf-8"));
}
@Override
public void run(SourceContext<String> ctx) throws Exception {
while (flag) {
FileStatus[] fileStatuses = hadoopFileSystem.listStatus(new Path("/test/buketingsink/20200608/"));
for (FileStatus fileStatus : fileStatuses) {
Path filePath = fileStatus.getPath();
in = hadoopFileSystem.open(filePath);
reader = new BufferedReader(new InputStreamReader(in, "utf-8"));
String line;
while ((line = reader.readLine()) != null) {
ctx.collect(line);
writer.write(line);
writer.newLine();
}
reader.close();
}
writer.flush();
}
}
@Override
public void cancel() {
flag = false;
try {
writer.close();
} catch (IOException e) {
e.printStackTrace();
}
}
});
inputStream.printToErr();
//inputStream.addSink(BaseTask.getSink("test", ".txt","/streamFileSink66", "yyyy-MM-dd"));
env.execute();
}
}
结果: OK

但是注意:当设置hadoopFileSystem写入HDFS不重写(NO_OVERWRITE)时,注意输出文件夹不能存在

遗留问题: StreamingFileSink 写入HDFS时需要伪装用户,不知道怎么操作


