python学习笔记7-函数
python如何定义一个函数?
用户自定义哈桉树需要遵循以下规则:
- 函数代码块以def关键词开头,后接函数标识符名称和圆括号()。
- 任何传入参数和自变量必须放在圆括号中间,圆括号中间可以用于定义参数
- 函数的第一行语句可以选择性地使用文档字符串,用于存放函数说明
- 函数内容以冒号起始,并缩进
- return[表达式] 用于结束函数,选择性地返回一个值给调用者。不带表达式的return相当于返回None
- 默认情况下,参数值和参数名称时按函数声明中定义的顺序来匹配的
python定义函数使用def关键字
def函数名(参数列表):
函数体
def hello():
print("Hello World")
hello()
什么是lambda函数?
python中有两中定义函数的方式,一种是用关键字def进行定义。使用这种方式定义函数时需要指定函数得到名称,这类函数被称为普通函数;另外一种时用关键字lambda进行定义,不需要指定函数的名字,这类函数被称为lambda函数。lambda函数又称匿名函数,他是一种单行的小函数,语法简单,简化代码,不会产生名冲突,也不会占用命名空间。lambda函数是一个可以接收任意多个参数(包括可选参数)并且返回单个表达式值的函数。lambda函数返回的表达式不能超过一个。不要试图使用lambda函数来实现复杂的业务逻辑功能,因为这回是代码变得晦涩难懂。如果有这样的要求,那么应该定义一个普通的函数,然后在普通的函数里实现复杂的业务逻辑。
lambda函数的语法:
lambda 参数:表达式
其中参数可以有多恶,用逗号隔开开;冒号右边表达式只能有一个,并且lambda函数返回的是函数对象,所以,使用lambda函数时,需要定义一个变量去接收。
sum = lambda x,y=y+x
print(sum(12,123))
再例如
g = lambda x,y=0,z=0:x+y+z
g(1)
g(3,4,6)
或者
print((lambda x,y=0,z=0:x+y+z),(3,5,6))
如果定义的哈桑农户非常简单,例如只有一个表达式,不包含其他命令,那么可以考虑lambda函数。否则,建议定义普通函数,毕竟普通函数没有太多限制
现有元组(('a'),('b'),('c'),('d')),请使用python中的匿名函数生成列表.[{'a', 'c'}, {'b', 'd'}]
匿名函数即lambda函数,参数为(x,y),返回{x,y},这里还应使用map函数,map(func,iterable)函数对于iterable依次传递给func,返回的时可迭代对象
date = (('a'),('b'),('c'),('d'))
print(date[0:2])
print(date[2:4])
v = list(map(lambda x,y:{x,y},date[0:2],date[2:4]))
print(v)
下面代码的输出的是什么?
def multipliers():
return [lambda x:i * x for i in range(4)]
print([m(2) for m in multipliers()])

注意结果不是[0,2,4,6].multipliers函数是将生成器对象生成的匿名函数转化成列表,匿名函数使用的是相同的内存空间。转化成列表后循环结束,命名空间里的i都是3.
原因是python的闭包是演示绑定(LateBinding)的,这说明再闭包中使用的的变量直到内层函数被调用的时候才会被查找到。当调用multipliers()返回的函数时,i参数的值会再这是被再调用环境中查找,所以,无论调用返回的那个函数,for循环此时已经结束,i等于它最终的值3.因此所有的函数都要乘以传递过来的3,因此上面的代码传递了2作为参数,所以它们都返回了6(即3*2)
如何绕过这个问题呢
方法一是使用python的生成器(generator)
def multpliers():
for i in range(4):yield lambda x:i*x
方法二是创造一个闭包,通过一个默认参数来立即绑定它的参数
def multpliers():
return [lambda x,i=i:i*x for i in range(4)]
或者是使用functools.partial函数来实现
from functools import partial
from operator import mul
def multilipliers():
return [partial(mul,i) for i in range(4)]
实现两个数相乘
s = lambda a,b:a*b
print(s(4,6))
普通函数和lambda函数有什么异同点
相同点:
都可以定义固定的方法和程序处理流程
都可以包含函数
不同点:
lambda函数代码更简洁,但是def定义的普通函数更为直观,易理解
def定义的是普通函数,而lambda定义的是表达式
lambda函数不能包含分支或者循环,不能包含return语句
关键字lambda用来创建匿名函数,而关键字def用来创建有名称的普通函数
单下划线与双下划线的区别有哪些
python用下划线作为前后缀指定特殊变量和定义方法,主要有如下四种形式
单下划线(_)
名称前的单下划线(如,_name)
名称前的双下划线(__name)
名称前后的双下划线(__init__)
单下划线
在交互式解释器中,单下划线代表的式上一条执行语句的结果,或者是作为零时变量
名称前的单下划线
用于指定属性和方法是私有的,但是python不想java一样具有私有属性、方法和类,在属性和方法之前加单下划线,只是代表该属性、方法或类名只能在内部使用,是API中非公开的部分。如果使用“from <moudel> import * ”和“from <package> import *"时这些属性、方法或类将不被导入。
如果想要被调用需要在文件开头加入 __all__
#将普通属性、但下划线的属性、方法、和类加入__all__列表
__all__=['vale','_otherValue','_otherMethod','_WClass']
名称前的双下划线
如果在一个程序中包含了构造器方法、普通方法、双下划线方法,当调用双下划线方法时,将会报Method类没有这个方法属性的错误。但是如果想要调用这个__OtherFun()改怎么办呢?答可以通过它的这个函数的类去调用它,例如m._first__OtherFun(),即只要以_类名__方法(属性)的形式既可以实现方法或者属性的访问了。类前面是单下划线,类名后是双下划线,然后加上方法或者属性。但是一般不建议这样去调用,因为这是python内部进行调用的形式。
为什么会有这样设计呢
class AMethod(object):
def __method(self):
print("__method in class Amthod!")
def method(self):
self.__method()
print("another method in class Amthod!")
class BMethod(AMethod):
def __method(self):
print("__method in class Bmthod!")
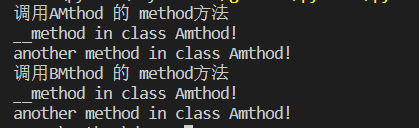
if __name__=="__main__":
print("调用AMthod 的 method方法")
a = AMethod()
a.method()
print("调用BMthod 的 method方法")
b = BMethod()
b.method()
'''
定义了两个类,AMethod和继承 AMethod类的BMethod类。在AMethod类中,定义了两个方法,一个时以下划线开头的__method方法,另一个是普通方法。在BMethod类中,重写了AMethod类的__method方法
'''
其中的b.method()并没有调用BMthod类的__method方法,这是因为设计的目的是为了避免父类的方法被子类轻易覆盖
名称前后的双下划线
表示在python内部调用的方法,一般不建议在程序中调用。例如,当调用len()方法时,实际上调用了python中内部的__len__方法,虽然不建议调用这种以下划线开头的以及结尾的方法,但是可以对这些方法进行重写
总结
- 单下划线:在交互解释器中,表是上一条语句执行输出的结果。另外,还可以作为特殊的临时变量,表示在后面将会不再用到的这个变量
- 名称前的单下划线:只能在内部使用,是API中非公开的部分,不能被导入到程序中,除非再“all”列表中包含了以单下划线开头的属性、方法或类
- 名称前的双下划线:以双下划线开头的属性伙房可以避免父类 的属性和方法被子类轻易覆盖,一般不建议这样定义属性和方法
- 名称前后有下划线:这类方法是python内部定义的方法,可以重写这些方法,这样python就可以调用这个重写的方法。
函数参数传递方式是什么?
值传递指的是在调用函数时,将实际参数赋值一份传递给形式参数,这样在函数中就可以修改形式参数,而不会影响到实际的参数。引用传递指的是,在调用函数时,将实际参数的地址传递给函数,这这样在函数中对参数的修改将会直接影响到实际参数。
对于不可变类型(数值型、字符串、元组),因为变量不能被修改,所以运算不会影响到变量自身,而对于可变类型(列表、字典)来说,函数内的运算可能会更改传入的参数变量,对于不可变数据类型来说,可以认为函数的参数传递是值传递,而对于可变数据类型来说,函数的参数传递是引用传递。
实例
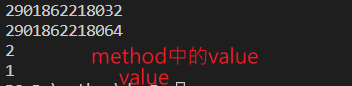
def method(value):
value = 2
print(id(value))
print(value)
value=1
print(id(value))
method(value)
print(value)
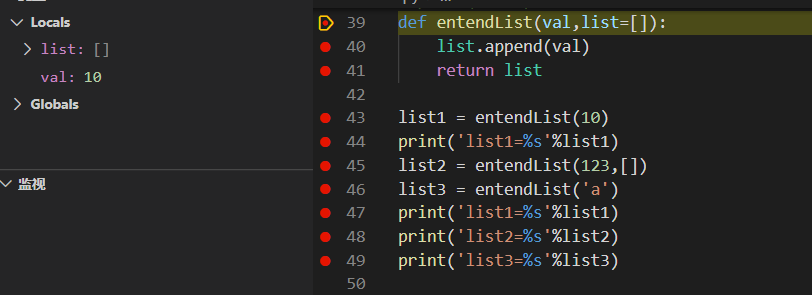
def entendList(val,list=[]):
list.append(val)
return list
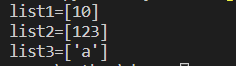
list1 = entendList(10)
print('list1=%s'%list1)#list1=[10]
list2 = entendList(123,[])
list3 = entendList('a')
print('list1=%s'%list1)#list1=[10, 'a']
print('list2=%s'%list2)#list2=[123]
print('list3=%s'%list3)#list3=[10, 'a']
为什么这里的list1的结果会不一样呢,而list1和list3又为什么不一样呢
通常会以为entendList函数的list参数在每一次函数被调用是会被设置为默认值[],但是,真实的情况是,默认的list只在函数定义的时候被创建一次。之后如果再调用entendList函数时不指定list参数,那么使用的都是同一个list。这是因为带默认参数的表达式时在函数定义的时候被计算的,而不是在函数调用时。所以,list1和list3都是在操作同一个默认参数list而list2是在操作它自己创建的一个独立的list(将自己的空list作为参数传递过去)
运行流程
首先list1 开始调用函数,因为只有一个参数10,所以此时list为默认的[],val为10,在使用append函数后list由[]变为了[10],因此存储空间中entendList函数存在的空间存储了[10],list1中存储了[10],然后将list1中存储的内容打印出来。
接着是list2开始调用,因为list2携带了两个参数且最后一个指定为[],因此val的为123,而list就变为了[],所以在使用append函数之后list由[]变为了[123],此时存储空间中list1为[10],list2[123],list[123]
接着是list3开始调用函数,因为list3只有一个参数所以沿用了之前list中的值[10],val为'a',由此可以看出list中的值并不会因为list2携带了[]覆盖掉之前通过append添加进list中的值,当在次调用append函数时list由[10]变为了[10,'a'],但是发现此时存储空间中list为[10,'a'], list1[10,'a'],list2[123],list3[10,'a'],由此做出判断这次的函数调用中list3所使用的list和list1所使用的list是同一个list。
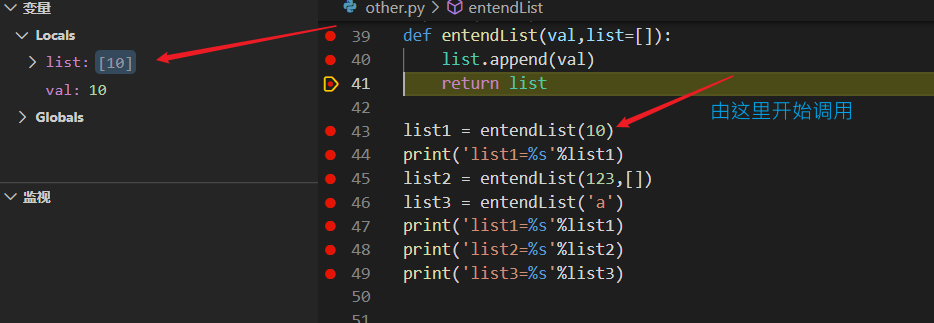
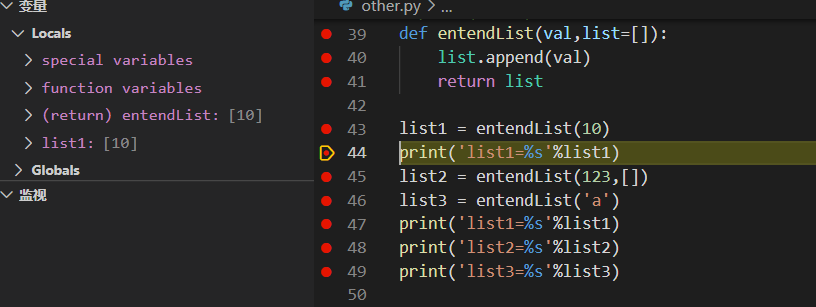
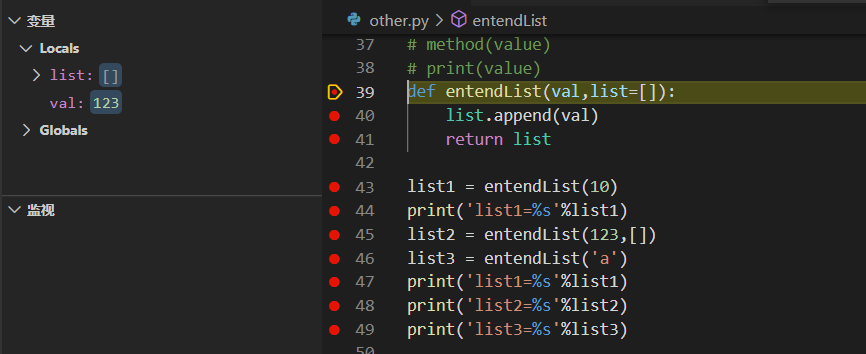
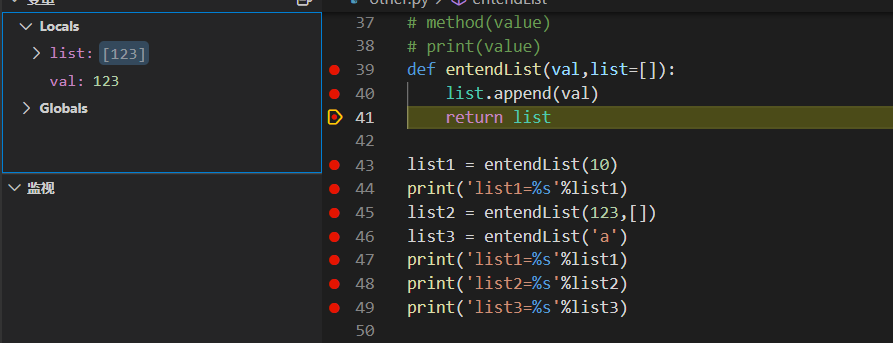
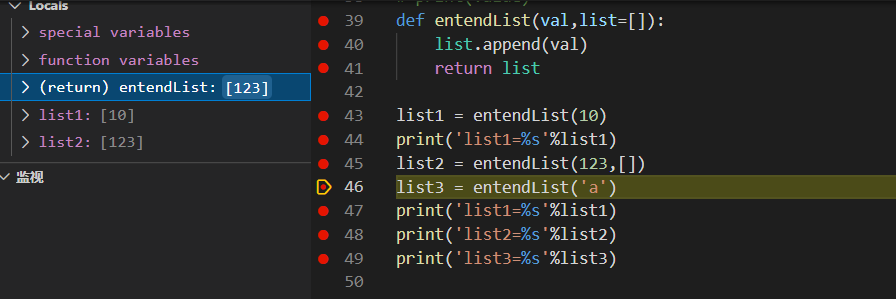
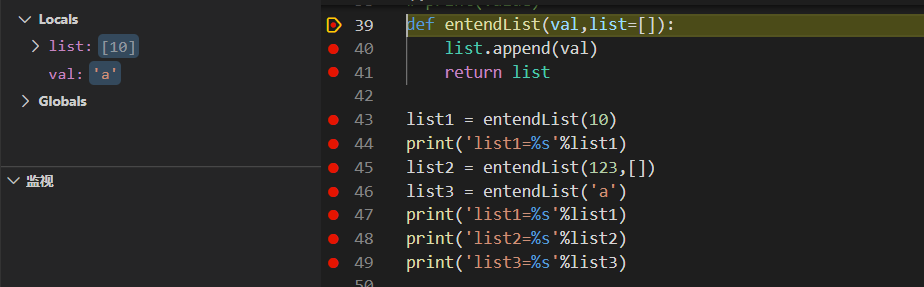
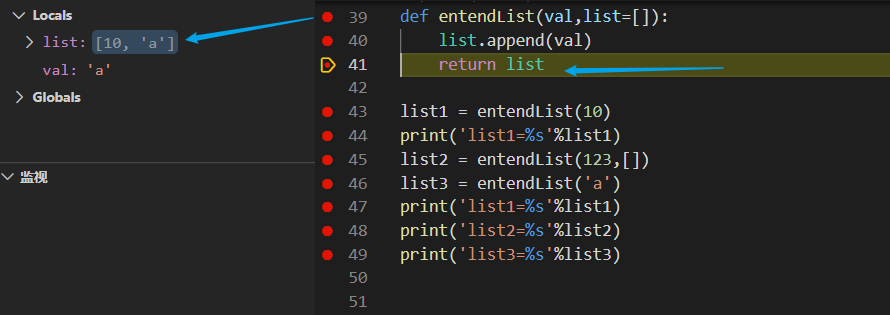
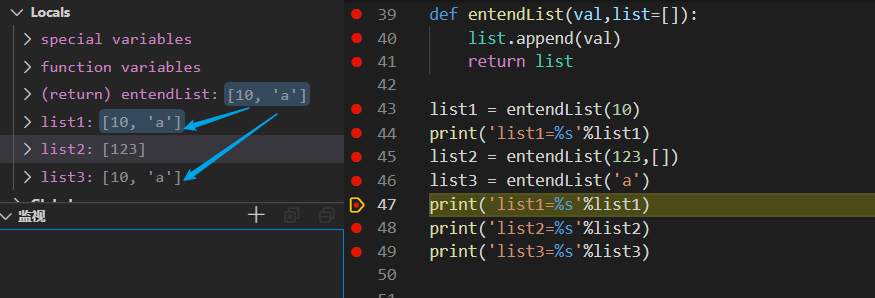
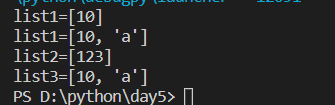
- entendList用的list都是一个,只要带的参数只有一个
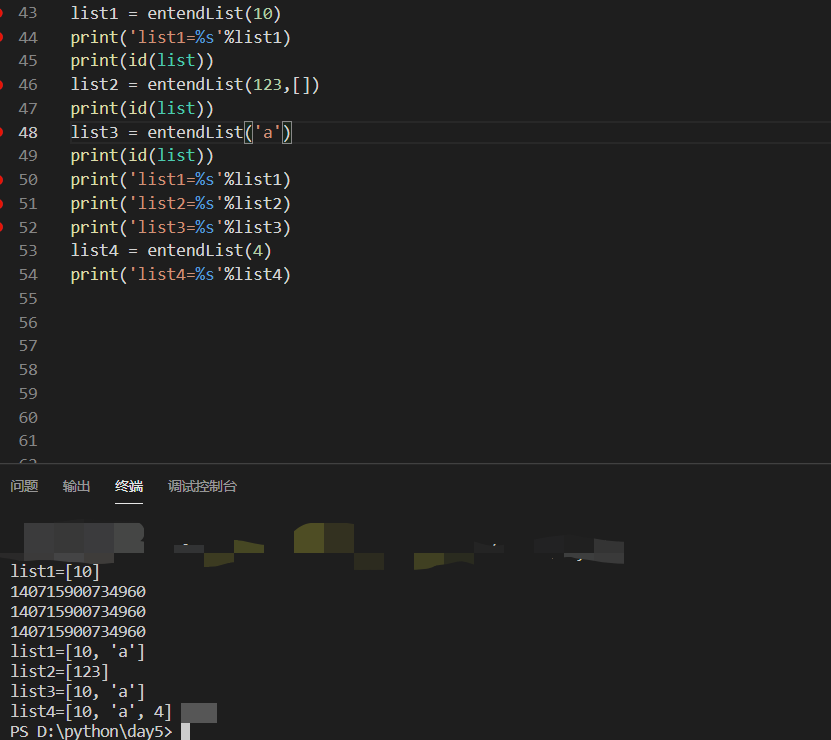
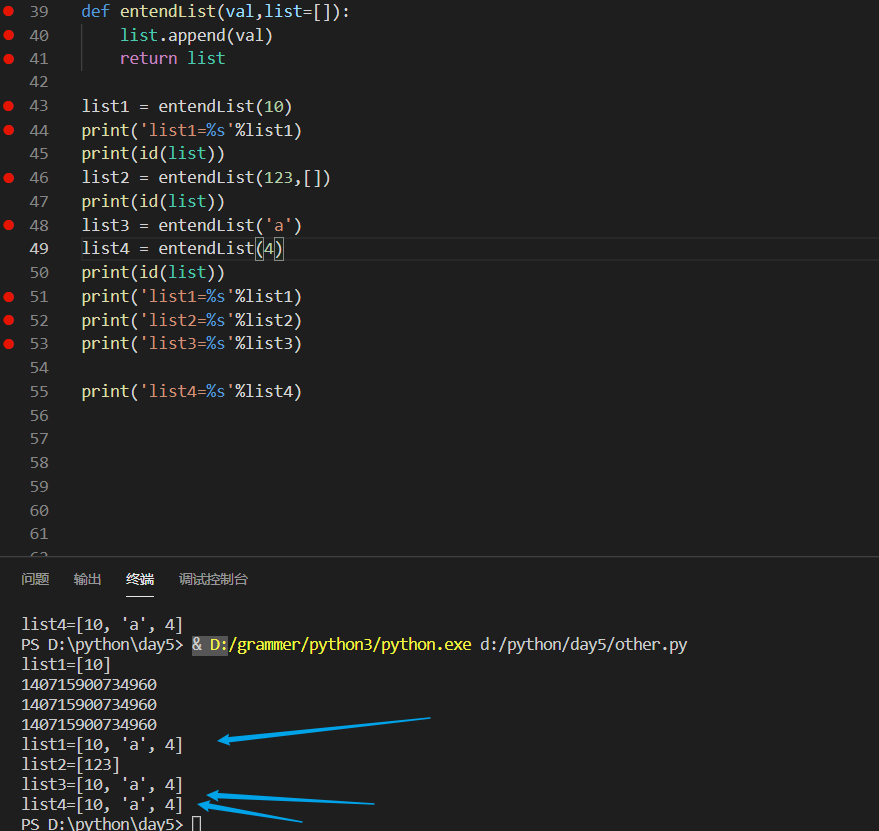
重新对entendlist进行定义
def entendList(val,list=None):
if list is None:
list = []
list.append(val)
return list
list1 = entendList(10)
list2 = entendList(123,[])
list3 = entendList('a')
print('list1=%s'%list1)
print('list2=%s'%list2)
print('list3=%s'%list3)
达到预期效果