
python学习笔记4
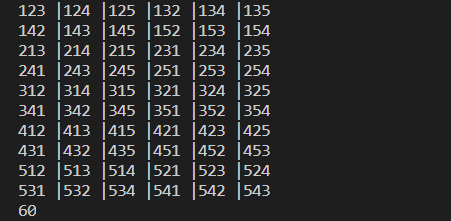
1,2,3,4,5能组成多少个互不相同的无重复的三位数?
一共可以生成5*4*3=60个互不相同的无重复的三位数
i = 0
for x in range(1,6):
for y in range(1,6):
for z in range(1,6):
if(x != y) and (y != z) and (z != x):
i += 1
if i % 6:
print("%d%d%d"%(x,y,z),end=' |')
else:
print("%d%d%d"%(x,y,z))
#或者用内置函数itertools
import itertools
print(len(list(itertools.permutations('12345',3))))
判断用户输入的年份是否为闰年
闰年是公历中的名词。闰年分为普通闰年和世纪闰年。公历闰年判定遵循的规律为四年一闰,百年不闰,四百年在闰
公历闰年的简单计算方法(符合以下条件之一的年份即为闰年,反之则是平年)
普通闰年:能被4整除但不能被100整除的年份为普通闰年,例如,如2004年就是闰年,1900年不是闰年。
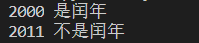
世纪闰年:能被400整除的为世纪闰年。例如,2000年是世纪闰年,1900年不是世纪闰年。
方法一:使用if进行分层进行判断
def year_l(year):
if(year % 4) == 0:
if(year % 100) == 0:
if(year % 400) == 0:
print("{0} 是闰年".format(year))
else:
print("{0} 不是闰年".format(year))
else:
print("{0} 是闰年".format(year))
else:
print("{0} 不是闰年".format(year))
year_l(2000)
year_l(2011)
方法二:使用if判断的条件进行整合
year = int(input("请输入一个年份:"))
if (year % 4) == 0 and (year % 100) != 0 or (year % 400) == 0:
print("{0} 是闰年".format(year))
else:
print("{0} 不是闰年".format(year))

方法三:使用python提供的函数进行判断
import calendar
year = int(input("请输入年份:"))
check_year = calendar.isleap(year)
if check_year == True:
print("{0} 是闰年".format(year))
else:
print("{0} 不是闰年".format(year))

判断用户输入的数值是否为质数
质数就是一个大于1的自然数,除了1和她本身外,不能被其它自然数(质数)整除(2,3,5,7等)换句话说就是该数除了1和它本身以外不再有其他的因素
def pd_num(num):
#质数大于1
if num > 1:
for i in range(2,num):
if(num % i) == 0:
print(num,"不是质数")
print("-->",i,"乘以",num // i,"是",num)
break
else:
print(num,"是质数")
else:
print(num,"不是质数")
pd_num(1)
pd_num(4)
pd_num(5)

如何获取一个字符串中某个字符的个数?
可以使用for循环,也可以使用collections模块Counter方法。Counter是一个简单的计数器
from collections import Counter
s = 'aabaffbgaa'
#统计序列中元素出现的次数,以字典的形式返回
c1 = Counter(s)
print(type(c1))
print(dict(c1))
print(Counter([2,4,2,5,6,2]))

有一篇英文文章保存在a.txt中,请用Python实现统计这篇文章内每个单词的出现频率,并返回出现频率最高的前10个单词及其出现次数(只考虑空格,标点符号可忽略)
可以使用collections模块的Counter函数
from collections import Counter
c = Counter
with open('a.txt','r',encoding='utf-8') as f:
for line in f.readlines():
words = line.split()
c1 = Counter(words)
c.update(c1)
deque是为了高效实现插入和删除操作的双向列表,适用于队列和栈
from collections import deque
d = deque([12,3,'hello',4])
d.append('world')
d.appendleft('hah')
print(d)
d.pop()
d.popleft()#从左边删除元素
print(d)
d.extend(['a','b'])
d.extendleft(['c','d'])
print(d)
d.rotate(-2)#正数,向右移动指定的元素,移动的元素会放到左边;负数,向左移2位
print(d)
print(list(d))

在使用dict是,如果引用的key不存在,就会抛出KeyError。如果希望Key不存在时,返回一个默认值,那么就可以用defaultdict
from collections import defaultdict
#参数使用的默认值的类型
#dd = defaultdict(int)#相当于默认值0
dd = defaultdict(list)
dd['key1'] = 100
print(dd['key2'])#如果key值不存在,不会异常,会返回指定类型的默认值
#参数时函数,函数返回值作为默认值
dd2 = defaultdict(lambda:'abc')
print(dd2['kk'])

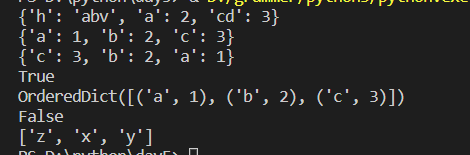
使用dict时,Key是无序的,在对dict做迭代是,无法确定Key的顺序。如果要保持Key的顺序,那么可以用OrderedDict
from collections import OrderedDict
#dict类型的字典,key值是无序的,但是3.6版本,输入和输出顺序是一样的
d1 = {}
d1['h'] = 'abv'
d1['a'] = 2
d1['cd'] = 3
print(d1)
d2 = {}
d2['a'] = 1
d2['b'] = 2
d2['c'] = 3
print(d2)
d3 = {}
d3['c'] = 3
d3['b'] = 2
d3['a'] = 1
print(d3)
#比较对象的内容是否相同
print(d2 == d3)
od1 = OrderedDict()
od1['a'] = 1
od1['b'] = 2
od1['c'] = 3
print(od1)
od3 = OrderedDict()
od3['c'] = 3
od3['a'] = 1
od3['b'] = 2
print(od1 == od3)
od = OrderedDict()
od['z'] = 1
od['x'] = 2
od['y'] = 3
print(list(od.keys()))
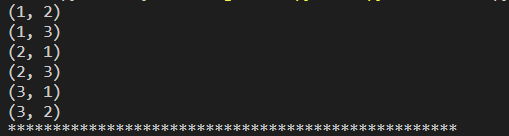
itertools模块提供了用于操作迭代对象的使用的函数。itertools模块提供的全部是处理迭代功能的函数,它们的返回值不是list,而是Iterator,只有for循环迭代的时候才能取到值
import itertools
#排列,例如(1,2))和(2,1)两个排列
#第二个参数,表示使用几个数进行排列
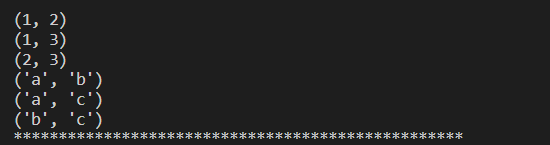
it1 = itertools.permutations([1,2,3],2)
for v in it1:
print(v)
print('*'*50)
#组合
it2 = itertools.combinations([1,2,3],2)
for j in it2:
print(j)
it3 = itertools.combinations('abc',2)
for k in it3:
print(k)
print('*'*50)
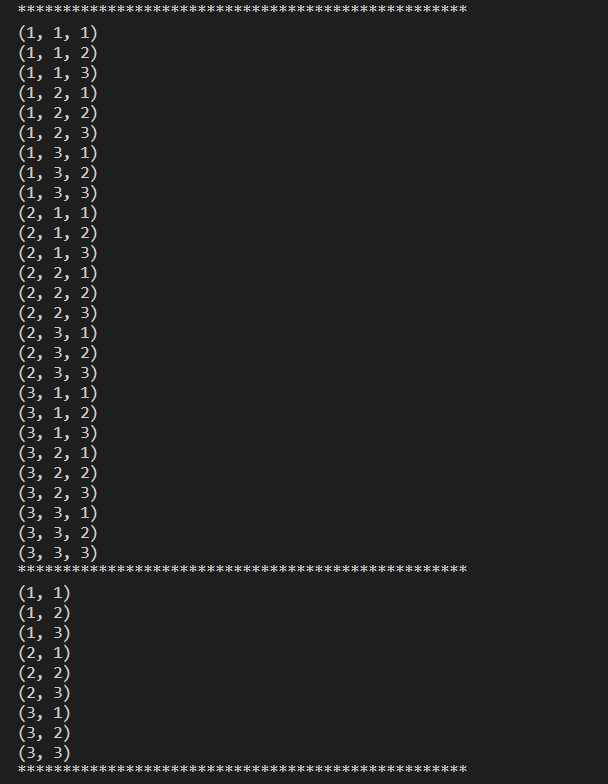
#笛卡尔积,能得到的所有可能的排雷组合,每个序列的元素个数相乘,等到所有的排列组合的个数
it4 = itertools.product([1,2,3],[1,2,3],[1,2,3])
for x in it4:
print(x)
print('*'*50)
#第二个参数,用来设置几个相同的序列做笛卡尔积
it5 = itertools.product([1,2,3],repeat=2)
for y in it5:
print(y)
print('*'*50)
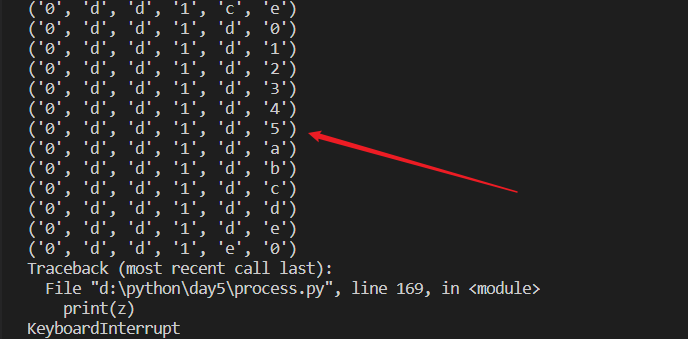
# #密码的暴力破解
# it6 = itertools.product('0123456abcde',repeat=6)
# for z in it6:
# print(z)
编程建议
- 字符串拼接,尽量使用join
- 单列对象,尽量使用is、is not,不要使用 ==
- 使用is not 而不是not is
- 使用def来定义函数,而不是将匿名函数赋值给某个变量
- 尽量使代码整齐,简洁
- 使用isinstance()来判断instance的类型

