re模块
正则表达式:
官方定义:正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,
组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑
白话:正则 是一种处理文字的规则,通过一些规则,让我们从杂乱无章的文字中提取有效信息
字符组:[字符组]
在同一位置可能出现的各种字符组成了一个字符组,在正则表达式中用[]表示
字符分很多类,如字母,数字,标点等等
假如现在要求一个位置'只能出现一个数字',那么这个位置上的字符只能是0,-9之一
白话:表示在一个字符的位置可以出现的所有情况的集合就是一个字符组
几个简单的正规规则:
[0123456789] [0-9] #简写模式必须从小到大 [1-37-9] [a-z] #简写模式必须从小到大 [A-Z] #A-z 大A到小z之间不是连续的,有特殊符号(ASCII码)
元字符:
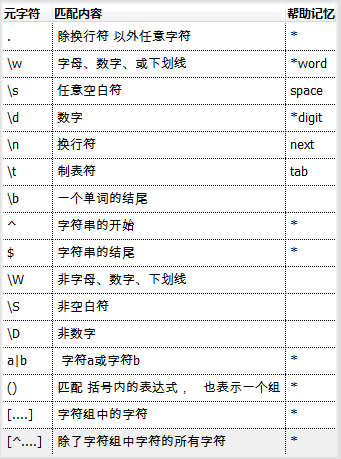
[\w\W] [\d\D] [\s\S] 这三个表示全集(无敌) 可以匹配任意字符
量词:

贪婪原则:量词有一个原则,就是 贪婪原则 (按最多的匹配,没有才按少的匹配)
非贪婪:加? 惰性匹配(按最少重复次数匹配)
\d*? # 匹配0个 匹配数字 加?,懒得一个也不匹配
so:
正则匹配:字符 量词 非贪婪标志
a.? "xyabc" # ab 贪婪 ?是量词
a.*? "xyabc" # a 非贪婪 ?是非贪婪标志
a.* "gjklgj" # ‘’ 匹配到一个 ‘’空字符 (a后面0个任意字符)
非贪婪经典用法:
.*?t "abctdeftxyz" # abct deft 匹配2个结果 (遇见t就停)
字符集:
[]
[^...]
[^和]+ "hello和Kitty和world" #hello Kitty world 3个匹配结果
分组() 和 或|
a|b 顺序:先匹配a 再匹配b
示例:身份证15位或18位
^([1-9]\d{16}[0-9x]|[1-9]\d{14}) # 用 | ,长的要放到前面
先匹配|前面的[1-9]\d{16}[0-9x] 如果匹配不到,在匹配|后面的[1-9]\d{14}
^[1-9]\d{14}(\d{2}[0-9x])?$ # ? 是量词
()表示分组,将 \d{2}[0-9x] 分成一组,就可以整体约束他们出现的次数为0-1次
转义符\
正则表达式 字符串 \\d “\\d” \\\\d “\\d” r'\d' r'\d' r'\\d' r'\\d'
re模块
常用的方法:
re. findall() 找到所有 找不到返回【】空列表
import re res = re.findall('o','hello,world') #res 得到一个 列表 print(res) # ['o', 'o'] 找到所有的'o'
re.search() .group()取值 从左到右,只找第一个 找不到返回None
res = re.search('o','hello world') print(res) #<_sre.SRE_Match object; span=(4, 5), match='o'> match='o' 需要用 .group()返回值 print(res.group()) # o 如果res=None None.group() 会报错 AttributeError: 'NoneType' object has no attribute 'group'
re.match() .group()取值 从头匹配,想当于^ 找不到返回None
None.group() AttributeError: 'NoneType' object has no attribute 'group'
re.split() 分割,拿到一个 列表
res = re.split('o','hello') print(res) #['hell', ''] res = re.split('[ab]','abcd') print(res) # ['' , '' , 'cd'] res = re.split('[ab]','abad') print(res) #['' , '' , '' , 'd']
re.sub() 替换 类似replace()
re.sub( re, new , str , count ) count 替换次数 replace( old , new , count) res = re.sub('\d','Y','aaa1aaa2aa3aa',2) 替换2次 print(res) #aaaYaaaYaa3aa
re.subn() 也是替换, 不过返回一个元组 (返回值,次数)
res = re.subn('\d','Y','ee1ee2ee3e') print(res) #('eeYeeYeeYe', 3)
re.compile() 编译正则 多次调用同一个正则表达式的时候,编译一次就OK
middle = re.compile('\d{3}') #将正则表达式编译成一个 正则表达式对象, res1 = middle.search('abc6666xyz') #正则表达式对象 调用search,参数为括号中待匹配的字符串 res2 = middle.search('def6666zyx') res3 = middle.findall('qwq6666klk') print(res1.group()) print(res2.group()) print(res3) #666 #666 #['666']
re.finditer() 找所有, 返回一个存放匹配结果的 迭代器
res = re.finditer('\d','abc123xyz456hehe') print(res) #<callable_iterator object at 0x00000000024C7EF0> for i in res: print(i) #返回值需要 .group() 取值 # <_sre.SRE_Match object; span=(3, 4), match='1'> # <_sre.SRE_Match object; span=(4, 5), match='2'> # <_sre.SRE_Match object; span=(5, 6), match='3'> # <_sre.SRE_Match object; span=(9, 10), match='4'> # <_sre.SRE_Match object; span=(10, 11), match='5'> # <_sre.SRE_Match object; span=(11, 12), match='6'> for i in res: print(i.group()) # or(print([i.group() for i in res])) 要用列表推导式 # 1 # 2 # 3 # 4 # 5 # 6 #迭代器为空,用 .group() 不报错
注意: findall() 和 split() 的优先顺序
findall()的优先级查询
组内优先 import re res1 = re.findall('www\.(baidu|cnblog)\.com','www.baidu.com') #search()没有优先级 print(res1) #优先返回 ()组内匹配结果 #['baidu'] res2 = re.findall('www\.(?:baidu|cnblog)\.com','www.baidu.com') print(res2) # ?: 取消组内优先级 #['www.baidu.com']
split()的优先级查询
import re res1 = re.split('\d+','ABC123abc34xyz') print(res1) # \d+ 没有保留匹配项 #['ABC', 'abc', 'xyz'] res2 = re.split('(\d+)','ABC123abc34xyz') print(res2) # (\d+) 保留了匹配项 # ['ABC', '123', 'abc', '34', 'xyz'] #在匹配部分加上()之后所切出的结果是不同的, #没有()的没有保留所匹配的项,但是有()的却能够保留了匹配的项, #这个在某些需要保留匹配部分的使用过程是非常重要的。
分组的命名 和 组的引用
1、匹配标签
import re res1 = re.search(r'www.(?P<web_name>baidu|cnblog).com',r'www.baidu.com').group('web_name') print(res1) #baidu res2 = re.search(r'www.(?P<web_name>baidu|cnblog).com',r'www.baidu.com').group() print(res2) #www.baidu.com
tag标签
import re res1 = re.search("<(?P<tag_name>\w+)>\w+</(?P=tag_name)>","<h1>hello</h1>") #还可以在分组中利用?<name>的形式给分组起名字 #获取的匹配结果可以直接用group('名字')拿到对应的值 print(res1.group('tag_name')) #h1 print(res1.group()) #<h1>hello</h1> import re res1 = re.search(r"<(\w+)>\w+</\1>","<h1>hello</h1>") #如果不给组起名字,也可以用\序号来找到对应的组,表示要找的内容和前面的组内容一致 #获取的匹配结果可以直接用group(序号)拿到对应的值 print(res1.group(1)) #h1 print(res1.group()) #<h1>hello</h1>
2、匹配整数
import re res = re.findall('\d+\.\d+|(\d+)', "1-2*(60+(40.35/5)-(-4*3)") #先找小数,而先返回分组内的整数 print(res) #['1', '2', '60', '', '5', '4', '3'] res.remove('') print(res) #['1', '2', '60', '5', '4', '3']

 浙公网安备 33010602011771号
浙公网安备 33010602011771号