
spark性能优化
两种序列化机制:
java和kryo序列化机制;
那么我们如何优化kryo类库的使用呢?
1、优化缓存大小
如果注册的要序列化的自定义的类型,本身就特别大,比如包括了超过100field,那么就会导致要序列化的对象过大,
此时就需要对kryo本身进行优化,因为kryo内部的缓存可能不够存放那么大的class对象,此时就需要调用SparkConf.set()方法,
设置spark.kryoserializer.buffer.mb参数的值,将其调大;
2、预先注册自定义类型
不进行注册自定义类型,kryo类库也能正常工作,但是,对于它要序列化的每个对象,都会保存一份它的全限定类名,此时反而
会耗费大量内存,因此通常都建议预先注册好要序列化的自定义的类;
那么我们在什么场景下使用kryo序列化类库呢?
在算子函数使用到了外部的大数据的情况,举例就是我们在外部定义了一个封装了应用了所有配置的对象,比如自定义了一个
MyConfiguration对象,里面包含了100m的数据,之后在算子函数里面使用到了这个外部的大对象;
那么我们去如何优化数据结构?
1、优先使用数组以及字符串,而不是集合类,换言之,就是优先用array,而不是
ArrayList、LinkedList、HashMap集合;
2、避免使用多层嵌套的对象结构,举例:
public class Teacher{
private List<Student> students = new ArrayList<String>()
}
3、对于有些能够避免的场景,尽量使用int替代String,因为String虽然比ArrayList、
HashMap等数据结构高效多了,占用内存量少多了,注意! 在spark应用中,id就不要用
常用的uuid了,因为无法转成int,就用自增int类型id即可;
对多次使用的RDD进行持久化或Checkpoint
若程序中,对某一个RDD,基于它进行了多次transformation或者action操作,那么就有必要对其进行持久化
操作,从而避免对一个RDD反复进行计算,另外,如果要保证在RDD的持久化数据可能丢失的情况下,
还要保证高性能,那么可以对RDD进行Checkponit操作;
接着使用序列化的持久化 :
除了上一步优化之外,还可以利用序列化的持久化优化其性能,比如MORY_ONLY_SER、MEMORY_AND_SER等;
使用RDD.persist(StorageLevel.MEMORY_ONLY_SER)这样的语法;如此一来,将数据序列化之后,再持久化,可以大大
减少对内存的消耗,此外,数据量小了以后,如果要写入磁盘,那么磁盘IO性能消耗也较小;对RDD持久化序列化后,RDD的每个
parttion的数据,都是序列化为一个巨大的字节数组,这样会减少内存的消耗,但有一个缺点就是,获取RDD数据时,需要对其进行反序列化,
会增大其性能开销;
因此,对于序列化的持久化级别,还可以进一步优化,也就是说,使用Kryo序列化类库,这样可以获得更快的序列化速度,并占用更小的内存空间,】
但是注意,如果RDD的元素(RDD<T>的泛型类型)是自定义类型的话,在Kryo中提前注册自定义类型;
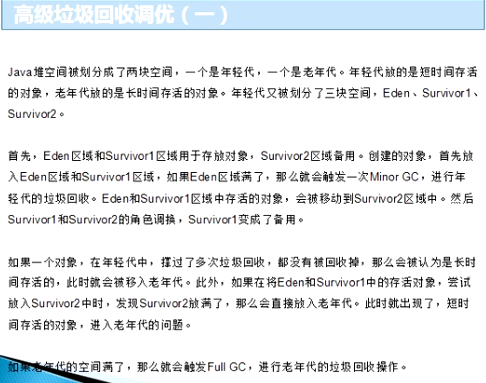
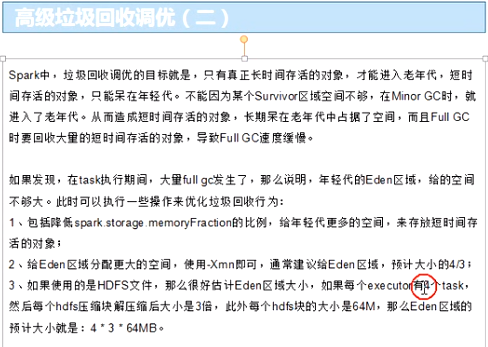
什么是Java虚拟机垃圾回收调优机制?
如何提高并行度?
实际上spark集群的资源并不一定会被充分利用,所以要尽量设置合理的并行度,来充分地利用集群的资源;
才能充分提高spark程序的性能;
spark会自动设置一文件作为输入源的RDD并行度,依据其大小,例如HDFS,就会给每个block创建一个partition,
也依据这个设置并行度,对于reduceByKey等会发生的shuffle的操作,就使用并行度最大的父RDD的并行度即可;
然后也可以手动使用textFile()、parallelize()等方法的第二个参数来设置并行度,也可以使用spark.default.
parallelism参数,来设置统一的并行度,Spark官方的推荐是,给集群中的每个cpu core设置2-3个task;
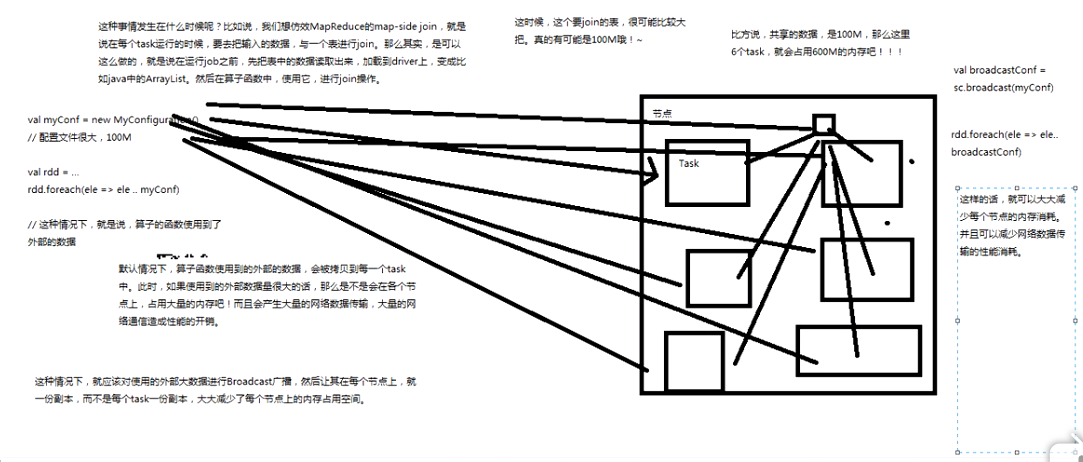
什么是广播共享数据原理?
若你的算子函数中,使用到了特别大的数据,那么这个时候,推荐将该数据进行广播,这样的话,就不至于
将一个大数据拷贝到每一个task上去,而是给每一个节点拷贝一份,然后节点的task共享该数据;
这样就可以减少大数据在节点上的内存消耗,并可以减少数据到节点的网络传输消耗;
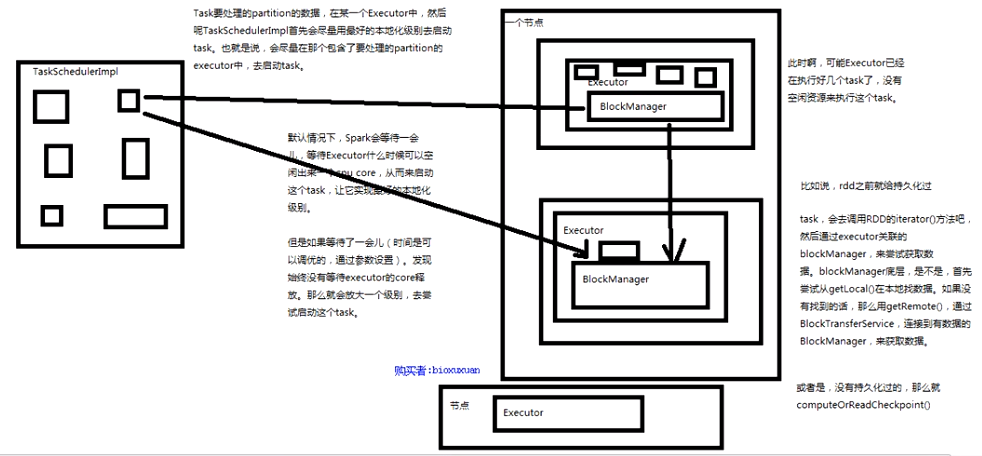
什么是数据本地化?
spark倾向于使用最好的本地化级别来调度task,但这无可能,如果没有任何未处理的数据在空闲的executor上,
那么spark就会放低本地化级别,这是有两个选择,第一,等待,直到executor上的cpu释放出来,那么就分配
task过去,第二,立即在任意一个executor上启动一个task;
spark默认会等待一会儿,来期望task要处理的数据所在的节点上的executor空闲出一个cpu,从而将task分配过去,
只要超过了时间,那么spark就会将task分配到其他任意一个空间的executor上;
原理图:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号