第三课——最短路
最短路
最短路的算法是学了非常多次的一个算法了,但是这次学到的算是更加全面的一次。以前从数据结构中学到的两种最短路的算法,Dijkstra和Floyd。这两个算法在这篇文章中也会提到,最为最基础的两种最短路算法,后续的算法也都是在他们的基础上展开的。文章的最后,还提到了最短路的一个变种(故切算是?)差分约束。
Dijkstra
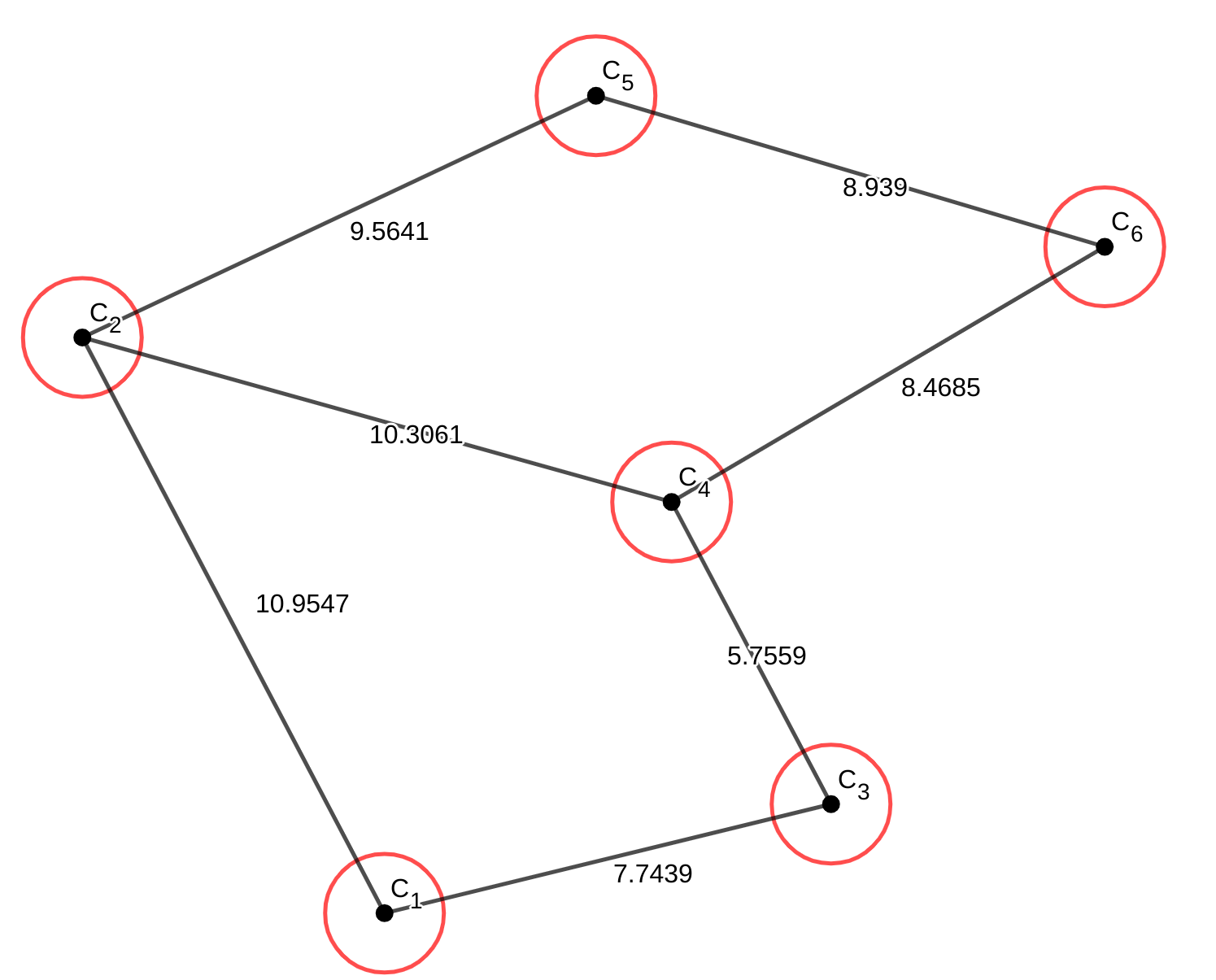
Dijkstra的想法其实有一种局部搜索的感觉,它做的事情是:“按照中转次数递增的顺序找最短路。”。和人的思想很像,看下面这张图:
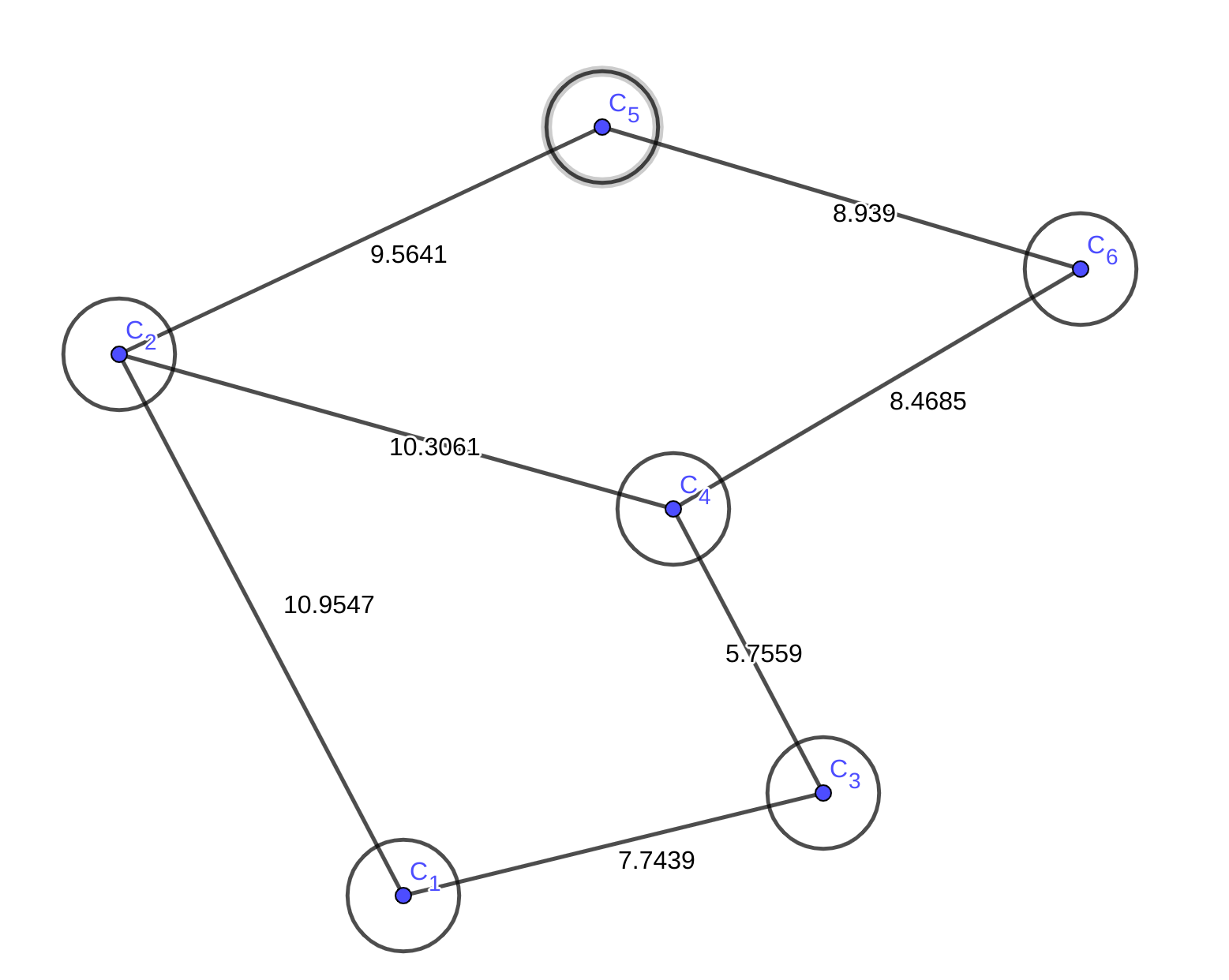
假如我从\(C_{1}\)出发,那么人会先看到自己一步能走到的地方:
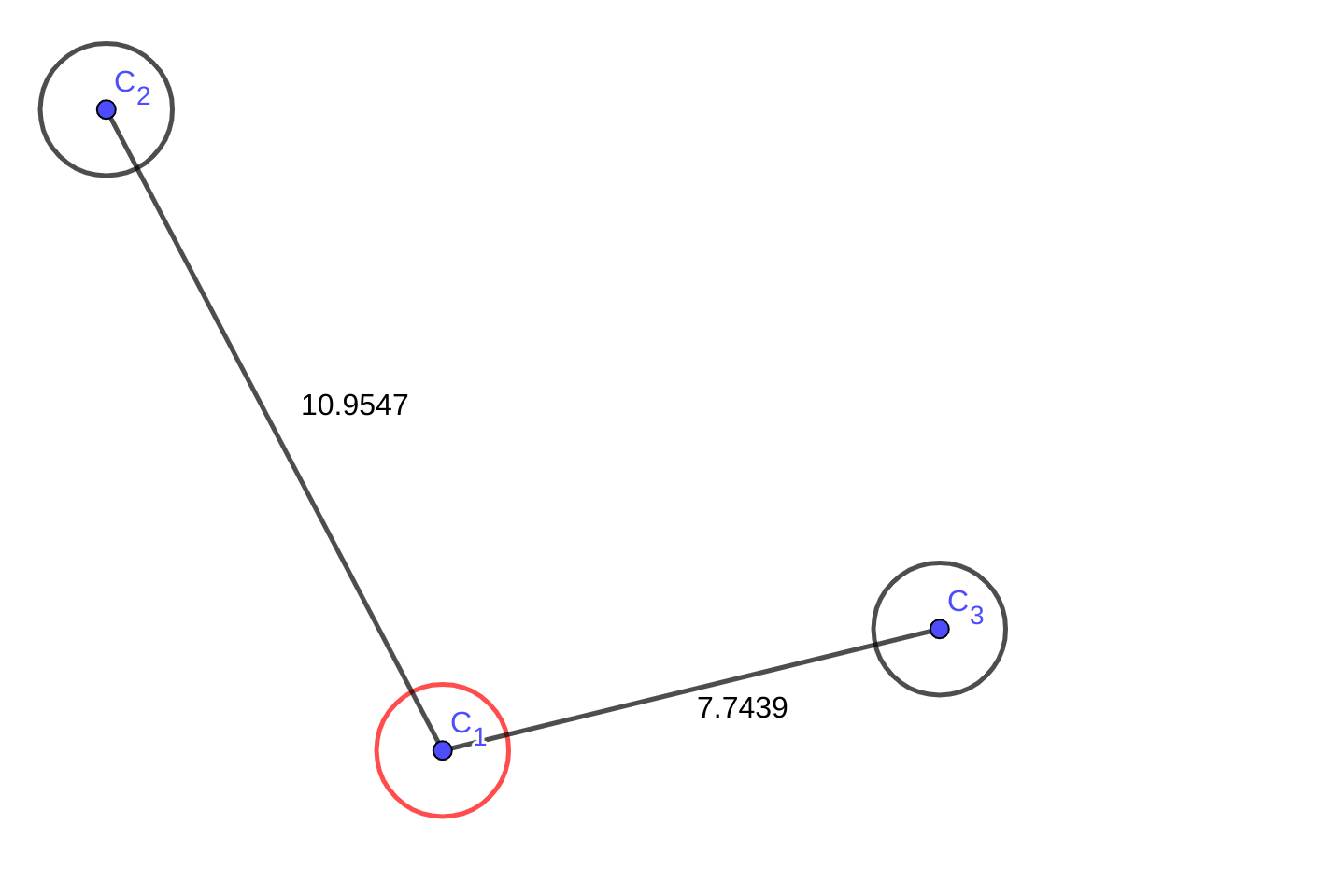
不管它最终要到哪里,都应该先走到最近的地方,也就是\(C_{3}\),那么\(C_{1}\)到\(C_{3}\)的最短路就找到了,也就是\(edge_{1,3}\)。然后我们把\(C_{3}\)一步能到的点加入视线中:
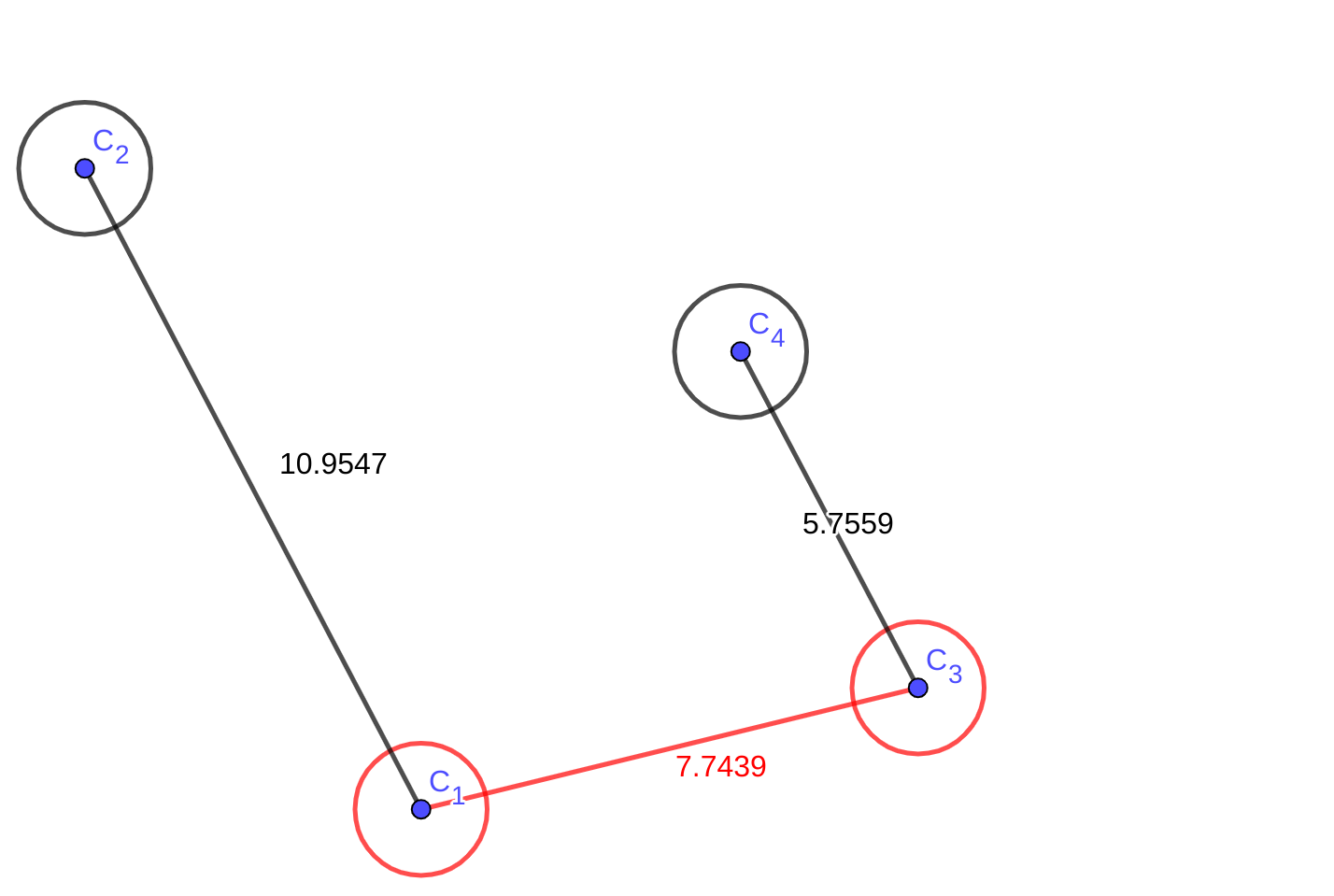
这里我们通过中转可以到达\(C_{4}\),但是发现从\(C_{3}\)中转再到\(C_{4}\)的距离大于到\(C_{2}\)的距离。所以我们把\(C_{2}\)加入候选集。同样的,\(C_{2}\)能到的点也要加入视线。
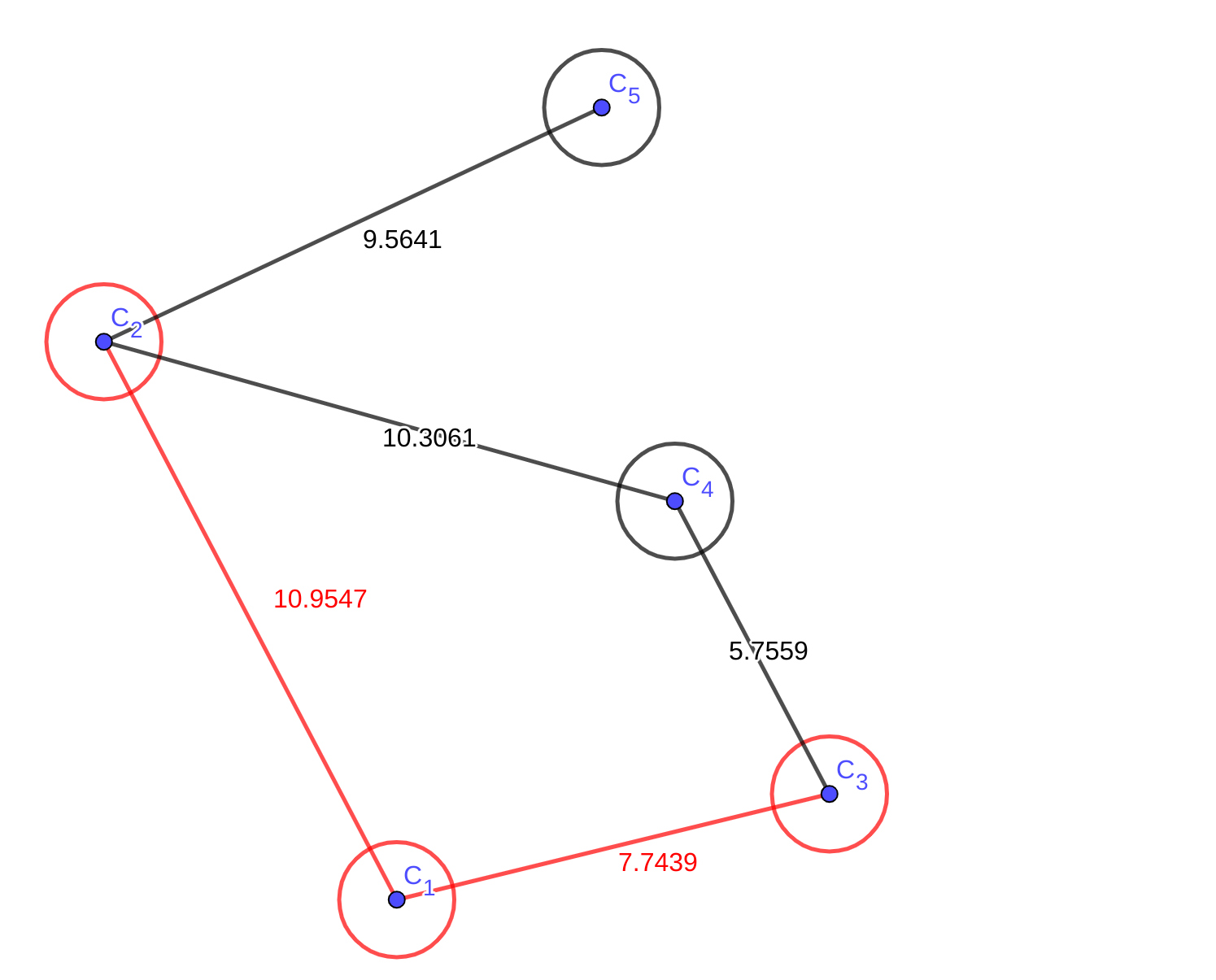
后续的操作我就用图片展示了:
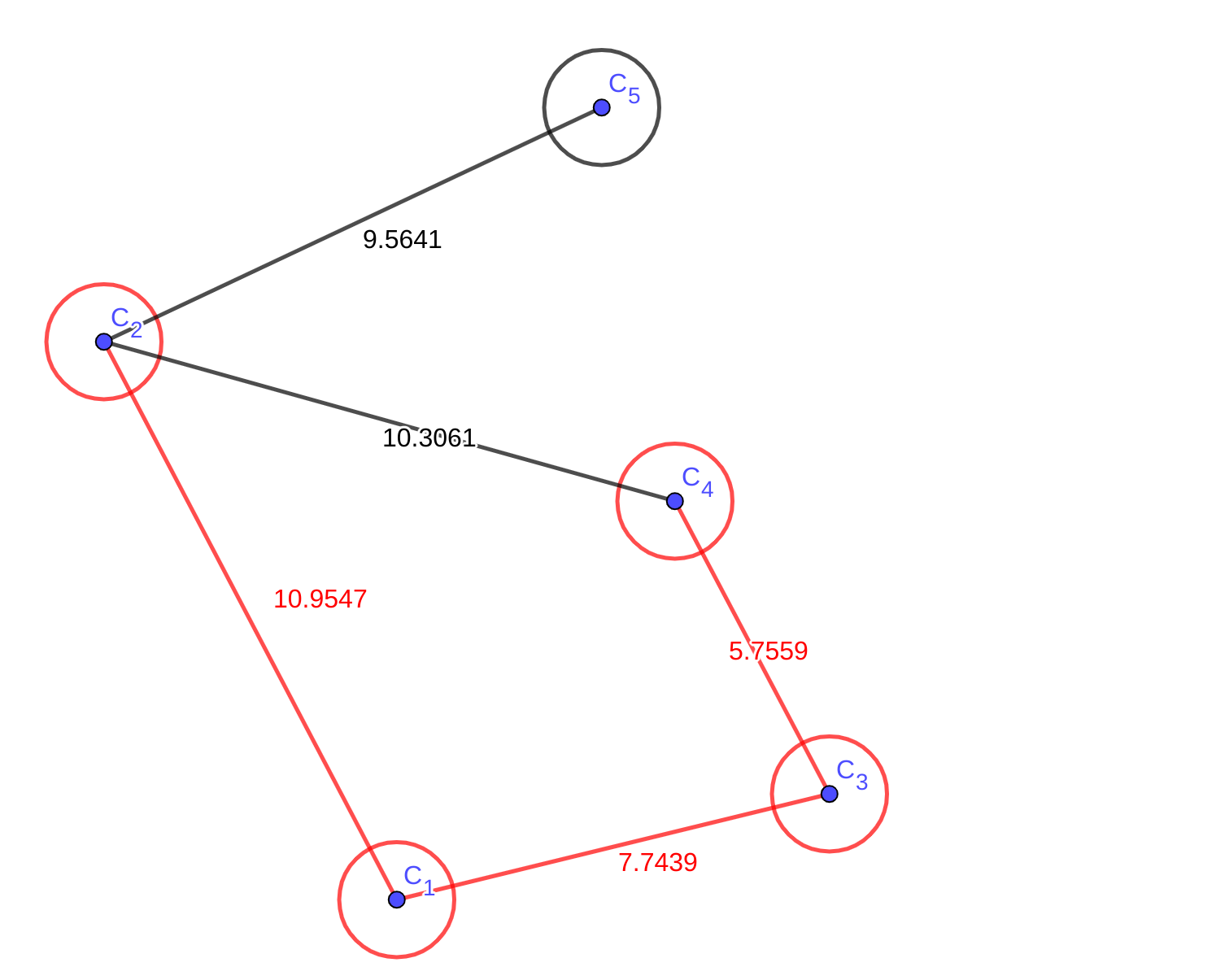
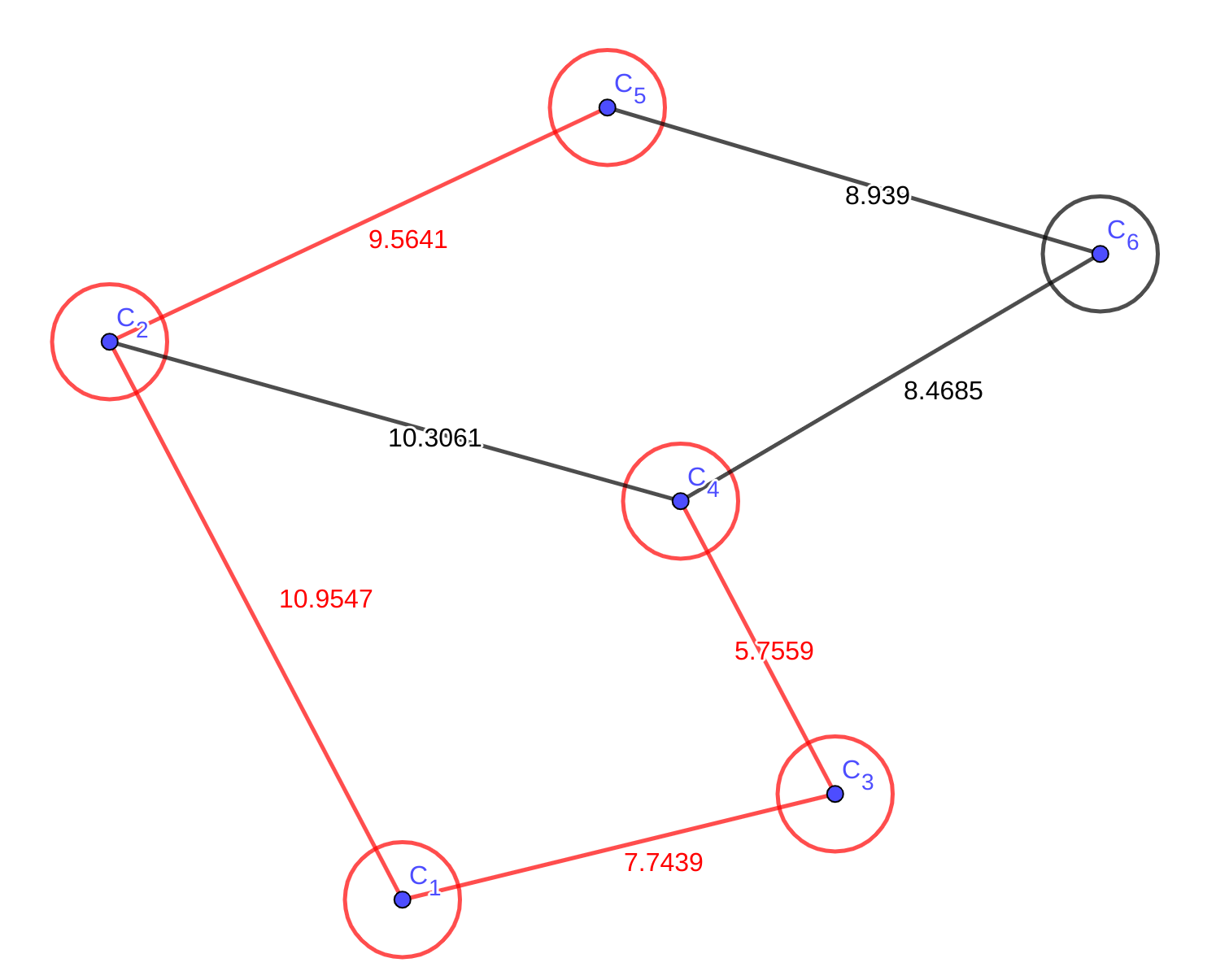
这里有个点,提一下。可以发现当前\(edge{1,2,4}\)是比\(edge{1,3,4,6}\)短的,但是因为\(C_{4}\)已经存在最短路了,而且那条路一定比新的路更短,所以不需要考虑在候选集中的点的最短路了。接下来应该更新\(C_{6}\):
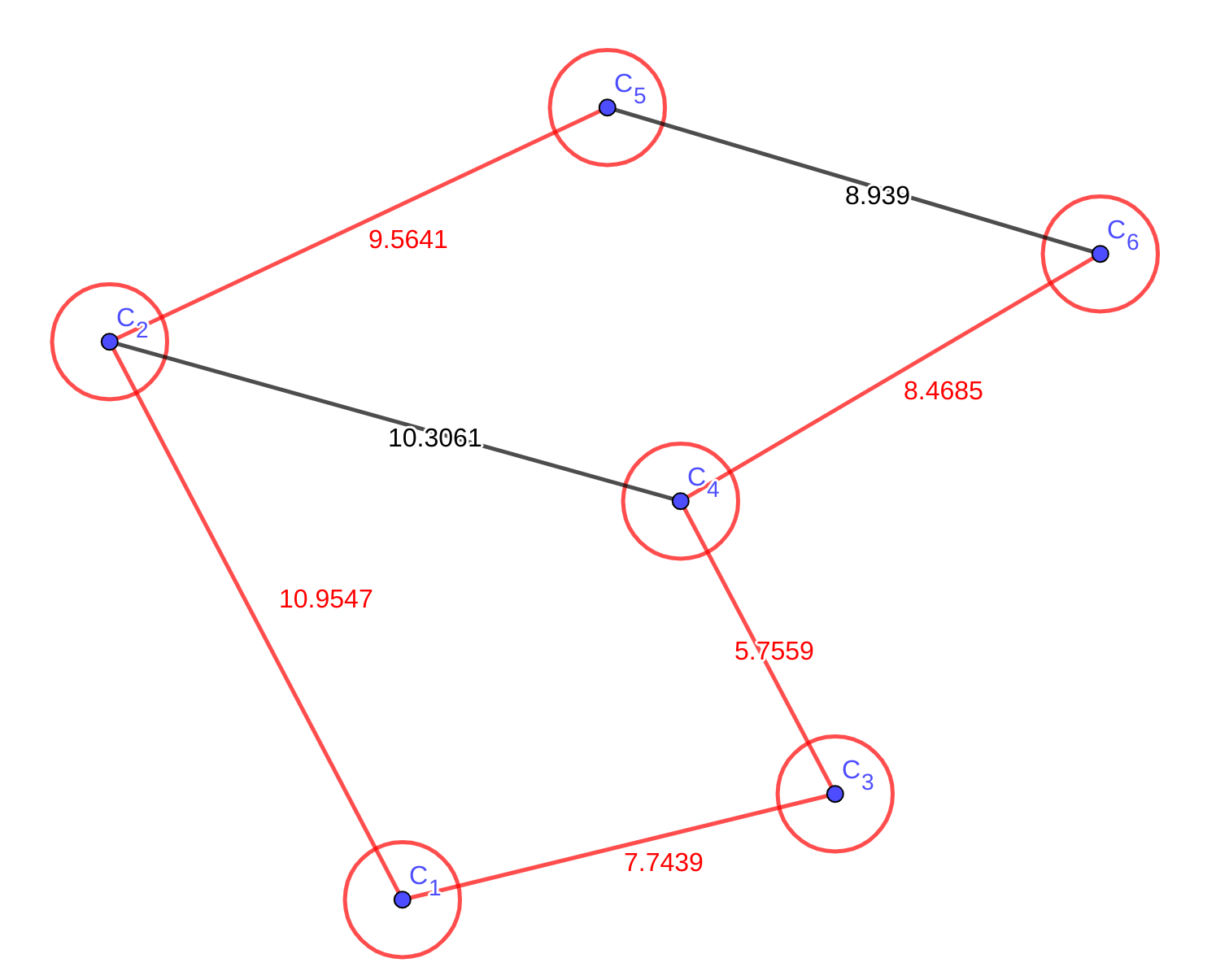
到这里,从起点到所有点的最短路就都算出来了。这是人脑的求路过程,而Dijkstra也是非常相似的做法,这里给出代码描述:
/*数据定义*/
#define N 101 //节点个数、
//inf 不能赋值为0x7fffffff,执行inf+inf时会溢出。
#define inf 0x3FFFFFFF
int map[N][N];
int via[N];
int dis[N]; //起点到某一个点的最短距离
/*初始化*/
for(int i=0;i<=n;i++){
via[i] = 1;
dis[i] = inf;
for(int j=0;j<=n;j++)map[i][j]=inf;
}
/*算法部分*/
int start = 1, target = n;
int now = start;
dis[start]=0;
via[start]=0;
while(now!=target){
int MIN = inf,next=now;
for(int i=1;i<=n;i++){ //注意这里,下面要讲
if(map[now][i]!=inf) //没有这一句会上溢出,因为涉及了0x7FFFFFF+0x7FFFFFFF
dis[i] = min(dis[i],map[now][i]+dis[now]);
if(via[i]&&dis[i]<MIN){
next = i;
MIN = dis[i];
}
}
if(MIN == inf)break;
now = next;
via[now]=0;
}
if(dis[target]==inf)printf("-1\n");
else printf("%d\n",dis[target]);
Dijkstra有一个非常明显的问题,通过比较与人脑的算法就能看出来,Dijkstra算法在判断下一个要进候选集的点的时候,需要遍历所有的点,这也使得复杂度来到了\(O(n^2)\)。想像一下,如果一个图比较稀疏,比如城市道路,可能有上千个十字路口,但是每个十字路口只有四条边左右。这个时候,如果也需要搜索每一个点的话,就会显得非常的多余。下面就是一个对比:
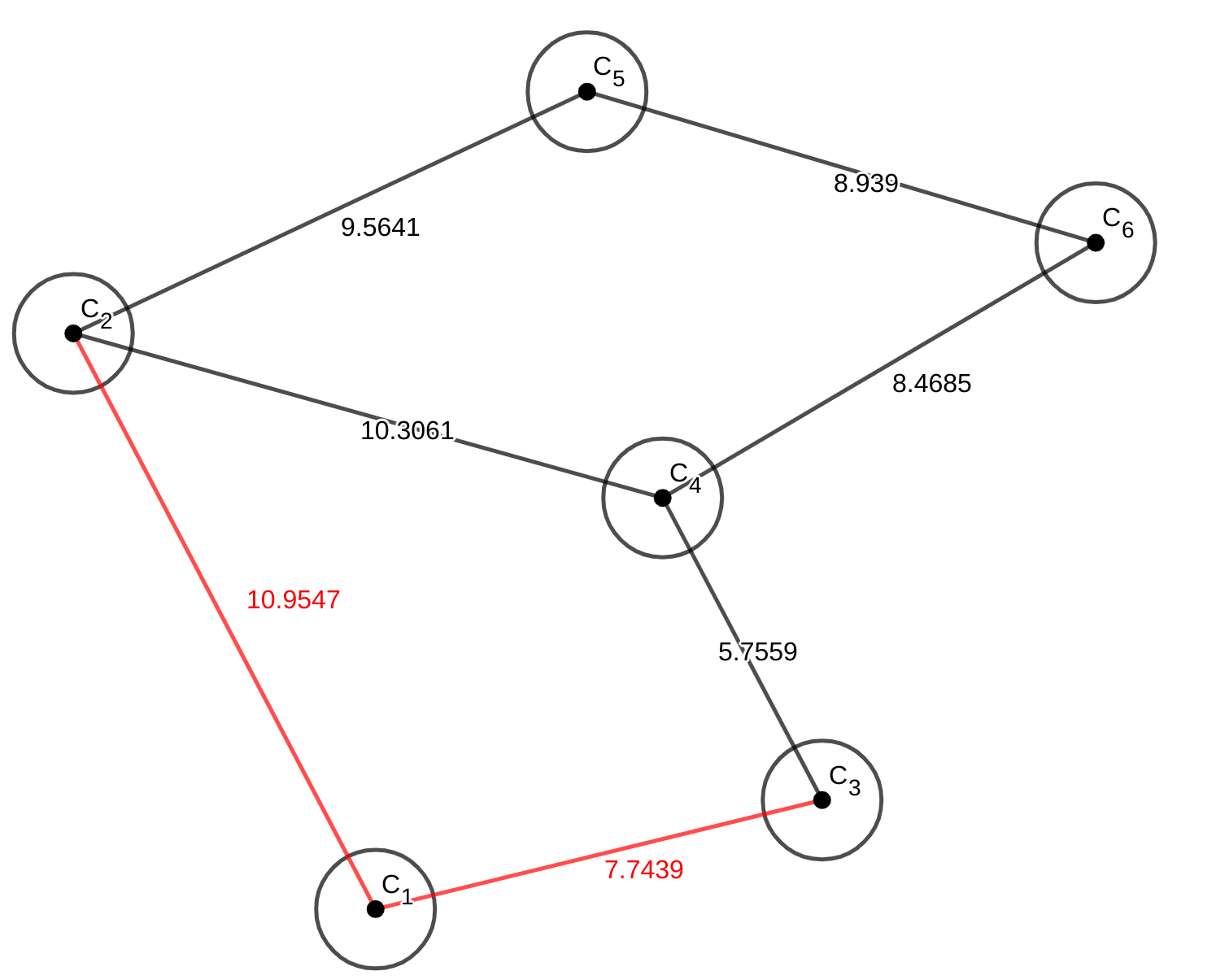
所以我可以使用链表来存储点的邻边,这样就能非常方便的访问各个点边了,但是有人会说了链表太慢了,我才不用,于是我们用数组来模拟链表——链式前向星。
链式前向星
这是一种数据结构,它用数组来存储邻接表。
邻接表我就不介绍了,这里直接介绍链式前向星:
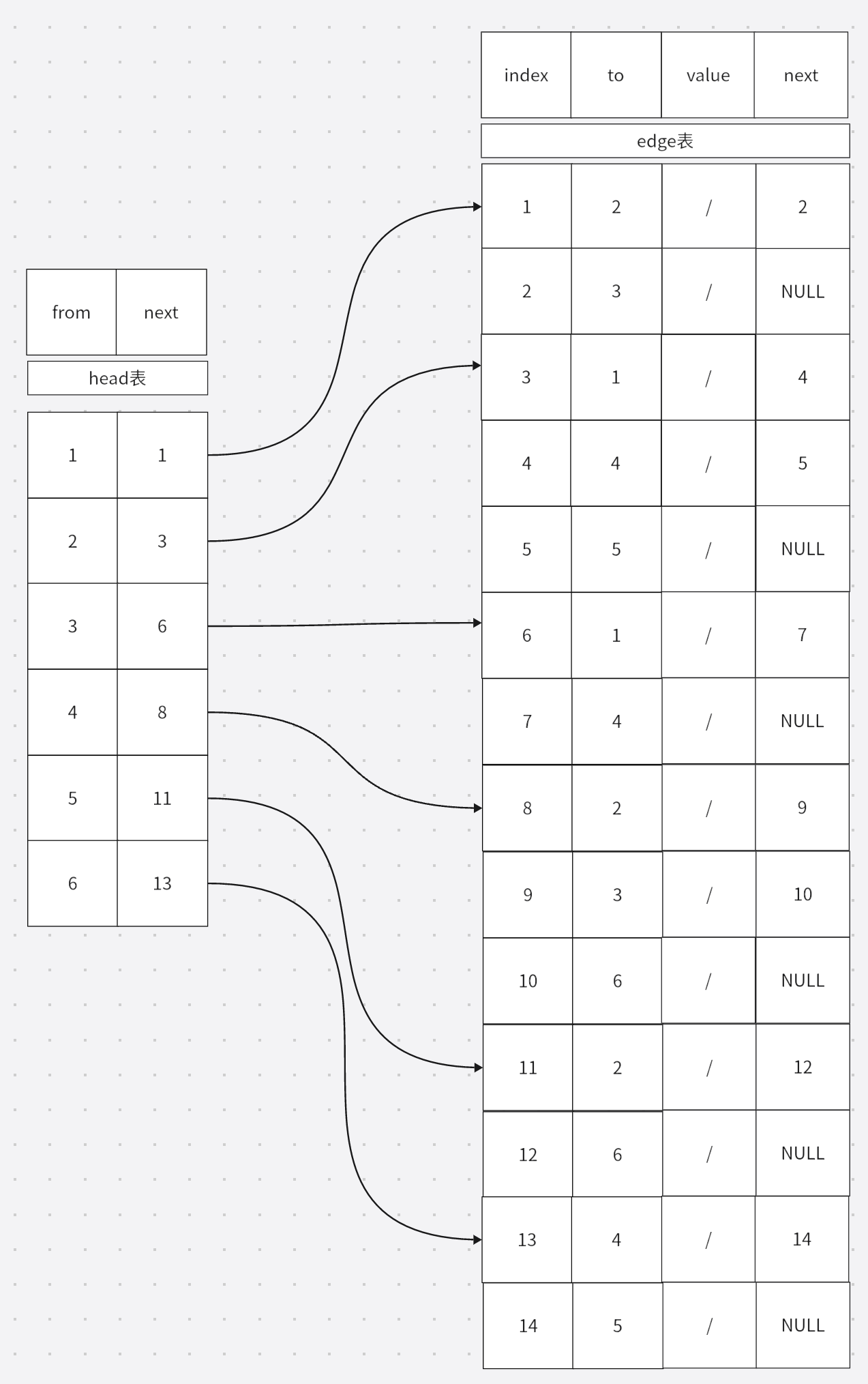
图上模拟的就是内存中的数据存储。这个数据结构主要由两个表组成,第一个是head表,其中from作为下标而存在,实际上它只有一个值,就是next,表示从该下标对应的顶点出发的点存储位置。比如,我们上面提到的图中,\(C_{1}\)点有两条出边,分别是\(C_{2},C_{3}\),那么我们可以通过head[1].next找到edge表中对应的边。再看edge表,首先是一个下标index实际并不存储,然后是to它是边的另一个顶点的编号,再是value也就是该边的权值,最后是next它和head表中的next有着相同的属性,他们都是edge表的下标。通过edge[1].next我们可以找到\(C_{1}\)的下一条边。也就是\(edge_{1,3}\)。学过链表的同学想必已经理解了。没有学过的同学可以再思考一下。
最后是这个数据结构的一个基础实现,主要是一个插入操作。
#define N 100005 //顶点数
#define M 200005 //边数
long long head[N];
struct Edge{
long long to,dis,next;
}edge[M];
void add_dege(long long from,long long to,long long value){
edge[++cnt].to = to;
edge[cnt].dis = value;
edge[cnt].next = head[from];
head[from] = cnt;
}
堆优化的Dijkstra
学会了链式前向星,我们来尝试一下思考如何用在Dijkstra上吧。
我们需要优化的点是:Dijkstra每次更新候选集的时候,需要遍历所有的点。
优先队列的设计
那么我们可以使用一个优先队列来维护我们当前访问到的点,并且排序的依据应该是该点到起始点的当前最短路长度。回到我们的人工计算最短路上来:
我们起初候选集里只有起点,但是我们能访问到的点有两个,并且这两个点都不在候选集里面。于是我们将他们连同他们的当前最短路加入优先队列中,下次从队列中取出最短的最短路就可以了。
我们可以设计一个放入队列中的数据包like this,其中,重载了小于运算符是为了让它在优先队列中能自动排序。因为我们需要构造最小堆,所以应该重载为a.dis<dis。因为优先队列是默认最大堆,而默认使用小于符号排序,所以我们需要重载反向的小于符号。
struct node{
long long id,dis;
bool operator <(const node&a)const{return a.dis<dis;}
};
点的重复
点的重复指的是一个点可能多次入队列,但是只要我们取出了某一个点,就能判断:后续出现的该点的距离一定比当前大,也就是后续的点都是多余的部分。 所以我们维护一个数组来标记顶点是否出队列,一旦出队列,就在后续的计算中不再接受该顶点。看代码:
void Dijkstra(){
priority_queue<node>q;
q.push(node{s,0});
for(long long i = 1;i<=n;i++){
dis[i] = INF;
}
dis[s]=0;
while(!q.empty()){
node a = q.top();
q.pop();
long long now = a.id;
if(vis[now])continue; //一旦出队列,就在后续的计算中不再接受该顶点
vis[now]=1;
for(long long i = head[now];i;i=edge[i].next){
long long j = edge[i].to;
if(dis[now]+edge[i].dis<dis[j]){
dis[j]=dis[now]+edge[i].dis;
q.push(node{j,dis[j]});
}
}
}
}
一个完整的例子
#include <iostream>
#include <queue>
#include <cstring>
using namespace std;
#define INF 0x3FFFFFFFFFFFFFFF
#define N 100005
#define M 200005
long long cnt,head[N];
long long n,m,s;
long long dis[N],vis[N];
struct Edge{
long long to,dis,next;
}edge[M];
void add_dege(long long from,long long to,long long value){
edge[++cnt].to = to;
edge[cnt].dis = value;
edge[cnt].next = head[from];
head[from] = cnt;
}
struct node{
long long id,dis;
bool operator <(const node&a)const{return a.dis<dis;}
};
void Dijkstra(){
priority_queue<node>q;
q.push(node{s,0});
for(long long i = 1;i<=n;i++){
dis[i] = INF;
}
dis[s]=0;
while(!q.empty()){
node a = q.top();
q.pop();
long long now = a.id;
if(vis[now])continue;
vis[now]=1;
for(long long i = head[now];i;i=edge[i].next){
long long j = edge[i].to;
if(dis[now]+edge[i].dis<dis[j]){
dis[j]=dis[now]+edge[i].dis;
q.push(node{j,dis[j]});
}
}
}
}
int main(){
while(scanf("%lld%lld%lld",&n,&m,&s)!=-1){
//初始化
cnt = 0;
memset(head,0,sizeof(long long)*N);
memset(dis,0,sizeof(long long)*N);
memset(vis,0,sizeof(long long)*N);
memset(edge,0,sizeof(Edge)*M);
long long u,v,w;
for(long long i=0;i<m;i++){
scanf("%lld%lld%lld",&u,&v,&w);
add_dege(u,v,w);
}
Dijkstra();
for(long long i=1;i<=n;i++){
i==1?1:printf(" ");
printf("%lld",dis[i]);
}
printf("\n");
}
}
Floyd
相比Dijkstra,Floyd真是再简单不过了,它使用的是一个非常清晰的动态规划的思想,使用三次循环直接算出任意两点之间的最短路。这里先给出核心代码:
for(k=0;k<n;k++)
for(i=0;i<n;i++)
for(j=0;j<n;j++)
e[i][j] = min(e[i][j],e[i][k]+e[k][j]);
状态转移方程的含义就是从i点出发,借助k点到达j点是否会更快。
Bellman-Ford
Bellman-Ford优化了Floyd固定\(O(N^3)\)的时间复杂度,继承了Floyd的动态规划的思想,得到了这么一个可以控制最大中转次数的路径算法:
for(int k=1;k<=n-1;k++){ //控制中转的次数
for(int i=1;i<m;i++){ //遍历所有的边
if(dis[v[i]]>disp[u[i]]+w[i]){
dis[v[i]]=dis[u[i]]+w[i];
}
}
}
其中v[i]是第i条边的入点,u[i]是第i条边的出点,w[i]是第i条边的权值。它的单点时间复杂度是\(O(N\times M )\),可能会比Dijkstra还慢,但是优点是算法简单,而且可以解负权边。
如何解负权边呢?
Dijkstra不能解负权边的原因是遇到负环的时候会出现死循环,而Bellman-Ford可以控制中转次数。如果一条路的中转次数超过了n-1次那说明它一定经过了负权环。也就是说,只要我们再进行一次内部循环,如果dis数组发生了改变,说明存在负权环。下面是判断负权环的代码其实很简单
for(int k=1;k<=n-1;k++){
for(int i=1;i<m;i++){
if(dis[v[i]]>disp[u[i]]+w[i]){
dis[v[i]]=dis[u[i]]+w[i];
}
}
}
for(int i=1;i<m;i++){
if(dis[v[i]]>disp[u[i]]+w[i]){
printf("存在负权环\n");
}
}
SPFA
SPFA全称shortest path fast algorithm,也就是快速最短路算法,非常正宗的中国式英语。
SPFA尝试解决Bellman-Ford每次都需要遍历n-1条边的问题,用队列维护需要修改的点。具体做法如下:
首先把起点放入队列,然后松弛相邻的所有点,如果松弛成功而且点不在队列中,则把点加入队列。
//spfa参考代码
void spfa(int u){
queue<int>q;
q.push(u); vis[u]=1;
while(!q.empty()){
int x = q.front();
q.pop(); vis[x]=0;
for(int i=first[x];i!=-1;i=next[i]){
int y = v[i];
if(dis[x]+w[i]<dis[y]){
dis[y]=dis[x]+w[i];
if(!vis[y])vis[y]=1,q.push(y);
}
}
}
}
同样的,spfa也能够判断负环的存在,但是需要我们记录每次使用的点,只要某一个节点我们使用的次数超过了n-1次,那么也能说明存在负环。这里就不给代码了。
差分约束
差分约束是最短路的一种问题表达形式,本质上是同一个问题。
2024-04-05 15:13:11 星期五后续再更新差分约束
本文来自博客园,作者:zhywyt,转载请注明原文链接:https://www.cnblogs.com/zhywyt/p/18105770

 浙公网安备 33010602011771号
浙公网安备 33010602011771号