第3课作业
第3课作业
基础作业:
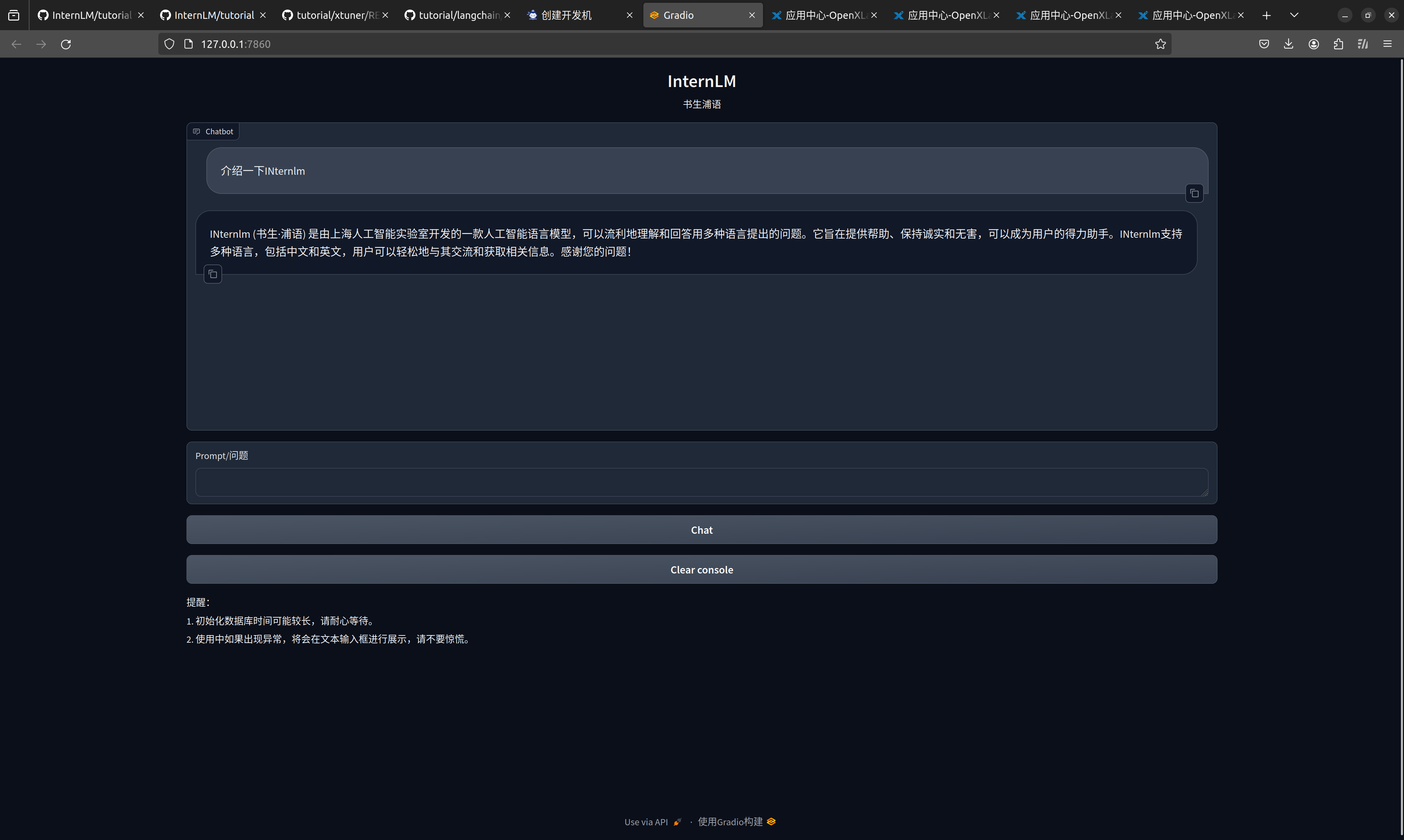
复现课程知识库助手搭建过程 (截图)
#genData.py
# 首先导入所需第三方库
from langchain.document_loaders import UnstructuredFileLoader
from langchain.document_loaders import UnstructuredMarkdownLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import Chroma
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
from tqdm import tqdm
import os
# 获取文件路径函数
def get_files(dir_path):
# args:dir_path,目标文件夹路径
file_list = []
for filepath, dirnames, filenames in os.walk(dir_path):
# os.walk 函数将递归遍历指定文件夹
for filename in filenames:
# 通过后缀名判断文件类型是否满足要求
if filename.endswith(".md"):
# 如果满足要求,将其绝对路径加入到结果列表
file_list.append(os.path.join(filepath, filename))
elif filename.endswith(".txt"):
file_list.append(os.path.join(filepath, filename))
return file_list
# 加载文件函数
def get_text(dir_path):
# args:dir_path,目标文件夹路径
# 首先调用上文定义的函数得到目标文件路径列表
file_lst = get_files(dir_path)
# docs 存放加载之后的纯文本对象
docs = []
# 遍历所有目标文件
for one_file in tqdm(file_lst):
file_type = one_file.split('.')[-1]
if file_type == 'md':
loader = UnstructuredMarkdownLoader(one_file)
elif file_type == 'txt':
loader = UnstructuredFileLoader(one_file)
else:
# 如果是不符合条件的文件,直接跳过
continue
docs.extend(loader.load())
return docs
# 目标文件夹
tar_dir = [
"/root/data/InternLM",
"/root/data/InternLM-XComposer",
"/root/data/lagent",
"/root/data/lmdeploy",
"/root/data/opencompass",
"/root/data/xtuner"
]
# 加载目标文件
docs = []
for dir_path in tar_dir:
docs.extend(get_text(dir_path))
# 对文本进行分块
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500, chunk_overlap=150)
split_docs = text_splitter.split_documents(docs)
# 加载开源词向量模型
embeddings = HuggingFaceEmbeddings(model_name="/root/data/model/sentence-transformer")
# 构建向量数据库
# 定义持久化路径
persist_directory = 'data_base/vector_db/chroma'
# 加载数据库
vectordb = Chroma.from_documents(
documents=split_docs,
embedding=embeddings,
persist_directory=persist_directory # 允许我们将persist_directory目录保存到磁盘上
)
# 将加载的向量数据库持久化到磁盘上
vectordb.persist()
进阶作业:
选择一个垂直领域,收集该领域的专业资料构建专业知识库,并搭建专业问答助手,并在 OpenXLab 上成功部署(截图,并提供应用地址)
未实现。
本文来自博客园,作者:zhywyt,转载请注明原文链接:https://www.cnblogs.com/zhywyt/p/18049988

 浙公网安备 33010602011771号
浙公网安备 33010602011771号