日志收集(ElasticSearch)串联查询 MDC
之前写过将应用程序或服务程序产生的日志直接写入搜索引擎的博客 其中基本过程就是 app->redis->logstash->elasticsearch 整个链路过程 本来想将redis替换成kafka的 无奈公司领导不让(不要问我为什么没有原因不想回答,哦也!就这么酷!!!)
然后又写了相关的优化,其实道理很简单 就是 部署多个redis 多个logstash就ok了 (注意redis建议不要部署集群单节点就OK因为他只承担了消息传输的功能别无其他,架集群的好处就是APP应用自己分发负载了,如果是多个redis单节点需要个类似nginx的东西做负载转发,其实最好使用F5这类的硬件会更好)好了不多说废话下面直奔主题。
遇到的问题
1、去ES(ElasticSearch 以下简称ES)查询日志用关键字搜索要搜索好几次才能定位的问题?
2、多线程调用公用的方法很多时候是不是有点迷糊找不着北等等 不止这些
想要达到的目的
通过关键字(关键字可以是订单号,操作码等可以标识一条信息,一般在数据库里面都是主键)一次查询出来所有的整个链路的相关日志
好,我们的目的很明确,不想各种过滤条件一大堆去定位真正想要的日志,一个关键搞定多所有。
说道这里可能有很多童鞋对日志框架比较了解第一就会想到MDC,没错就是他。下面才是真正的主题,哈哈!
MDC我就不多介绍这里我在网上随便找了一个介绍的 如果熟悉可以略过(https://blog.csdn.net/liubo2012/article/details/46337063)
MDC其实就是在方法里面前后标记一下,然后在这个标记范围内(包括中间调用的方法嵌套)所有的日志都会打上相应的标签记录方便查询
那怎么和我们之前的 方案结合和 我们之前用的是下面这个包,这个包是支持MDC传输的具体源码大家可以参看github实现https://github.com/kmtong/logback-redis-appender
<dependency> <groupId>com.cwbase</groupId> <artifactId>logback-redis-appender</artifactId> <version>1.1.5</version> </dependency>
当我们引入这个包之后logback.xml文件是如下配置的
<?xml version="1.0" encoding="UTF-8"?> <configuration debug="false" scan="true" scanPeriod="1 seconds"> <include resource="org/springframework/boot/logging/logback/base.xml" /> <!-- <jmxConfigurator/> --> <contextName>logback</contextName> <property name="log.path" value="\logs\logback.log" /> <property name="log.pattern" value="%d{yyyy-MM-dd HH:mm:ss.SSS} -%5p ${PID} --- traceId:[%X{mdc_trace_id}] [%15.15t] %-40.40logger{39} : %m%n" /> <appender name="file" class="ch.qos.logback.core.rolling.RollingFileAppender"> <file>${log.path}</file> <encoder> <pattern>${log.pattern}</pattern> </encoder> <rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"> <fileNamePattern>info-%d{yyyy-MM-dd}-%i.log </fileNamePattern> <timeBasedFileNamingAndTriggeringPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedFNATP"> <maxFileSize>10MB</maxFileSize> </timeBasedFileNamingAndTriggeringPolicy> <maxHistory>10</maxHistory> </rollingPolicy> </appender> <appender name="redis" class="com.cwbase.logback.RedisAppender"> <tags>test</tags> <host>10.10.12.21</host> <port>6379</port> <key>spp</key> <mdc>true</mdc> <callerStackIndex>0</callerStackIndex> <location>true</location> <!-- <additionalField> <key>traceId</key> <value>@{destination}</value> </additionalField> --> </appender> <root level="info"> <!-- <appender-ref ref="file" /> --> <!-- <appender-ref ref="UdpSocket" /> --> <!-- <appender-ref ref="TcpSocket" /> --> <appender-ref ref="redis" /> </root> <!-- <logger name="com.example.logback" level="warn" /> --> </configuration>
我们把<mdc>true</mdc>标签设置为true 默认是false就可以了,下面我们看下我们的测试代码
package com.zjs.canal.client.client; import org.junit.Test; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import org.slf4j.MDC; public class testaa { protected final static Logger logger = LoggerFactory.getLogger(testaa.class); @Test public void test(){ MDC.put("destination", "123456789"); for (int i = 0; i < 10; i++) { logger.info("aaaaaaaa"+i); test1(); } MDC.remove("destination"); } public void test1() { for (int i = 0; i < 10; i++) { logger.info("bbbbbbbb"+i); } } }
上面的测试有两层嵌套下面是ES日志输出
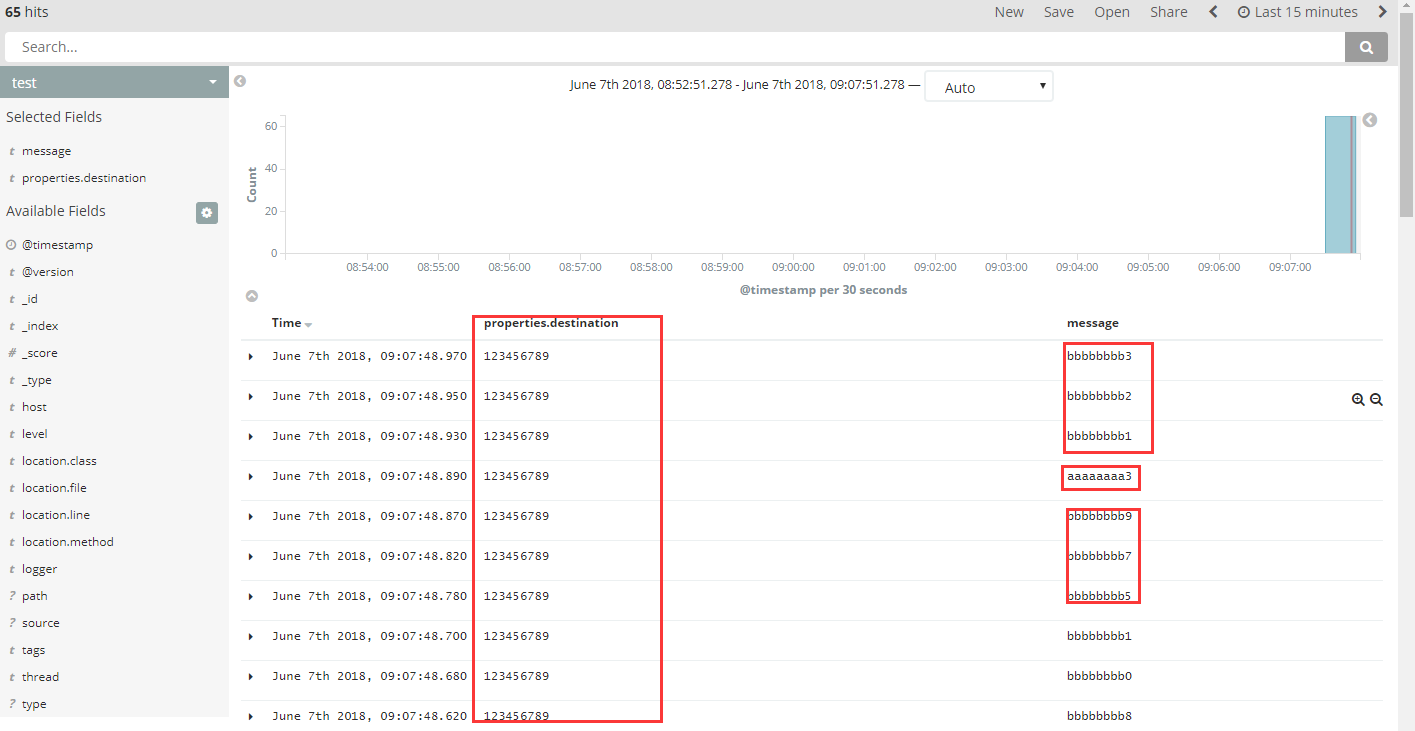
大家可以看到日志输出内容包含了两个方法,都包含相应的properties.destination字段并且值也是一样的(当然真正使用的时候destination MDC的关键字是动态的,选查询的主要关键字)
这样通过关键字一下就能把所有相关的日志都查询出来就能看出数据整个处理流程,这样就非常方便我们的查询定位排查问题
我上面的代码有一段注释不知道大家有没有注意到
就是下面这段
<!-- <additionalField> <key>traceId</key> <value>@{destination}</value> </additionalField> -->
其实我们把<mdc>true</mdc>这句设为false也是可以了不过需要添加一个字段来引用数据(把上面的配置取消注释)这样我们就可以自定义命名跟踪字段的名称了(本人更倾向使用这种)
然后配置就办成下面这样
<appender name="redis" class="com.cwbase.logback.RedisAppender"> <tags>test</tags> <host>10.10.12.21</host> <port>6379</port> <key>spp</key> <!-- <mdc>true</mdc> --> <callerStackIndex>0</callerStackIndex> <location>true</location> <additionalField> <key>traceId</key> <value>@{destination}</value> </additionalField> </appender>
然后看下效果
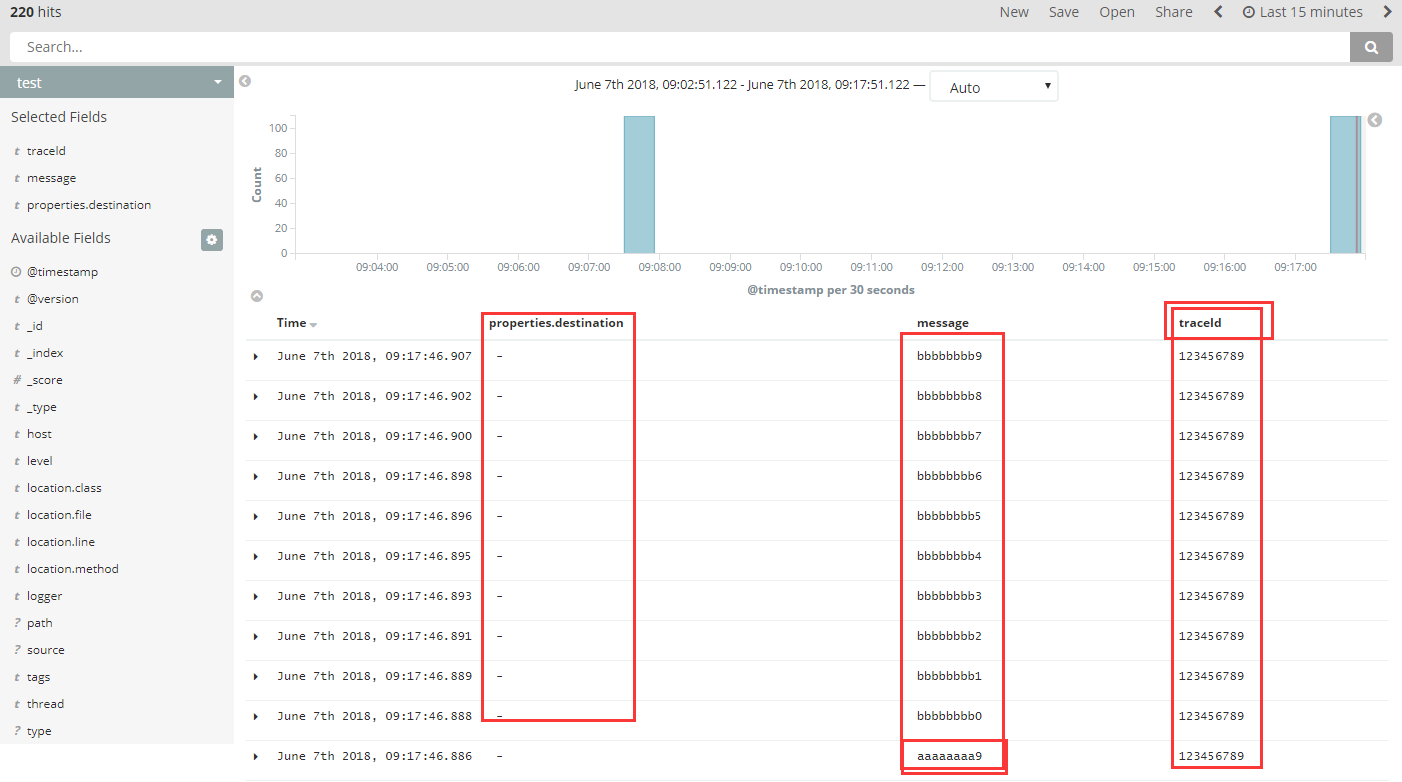
这是之前的默认字段就没有值了mdc引用的值变成我们新的字段里面去了
其实都可以开启 但是会打印两份MDC和自定义字段,这样就会重复了,所以说没必要了
好了 今天就说的这里希望对看博客的你有所帮助

 浙公网安备 33010602011771号
浙公网安备 33010602011771号