
幂等问题本质和业务场景的解决方案
1、基本概念
幂等数学上的概念就是f(x)=f(f(x)),数学上的定义大家可以自行去网上查询,在计算机领域所谓幂等性设计,就是说,一次和多次请求某一个资源应该具有同样的副作用。基本上我们开发的系统一般涉及到所谓“重复”的问题都是幂等的范畴。
备注:上面的数学公式硬套在我们的一般的系统系统中总感觉是第一次的请求结果作为第二次的参数,不过不用怀疑,数据公式就是这么规定的。我们理解就好。
2、怎样定义你的数据是重复的
一般我们要解决的幂等问题,我们会从各个角度来定义什么样的数据是重复的。下面我定义的两个重复类型。
业务上的重复:所谓业务上的重复就是我们自定义的重复,完全遵从了业务需求。怎么判断它是不是重复的,比如相同订单号的订单数据就是重复的,订单号和支付编码同时相同的数据也是重复的,其他信息比如下单时间,支付时间等等这些我们不作为判断依据。
技术上的重复:所谓技术上的重复就是一个数据报文完全相同的数据。比如TCP协议中网络丢包了,他要重发数据包,重发的数据包就是重复的、再比如nginx重发引起的重复。
3、为什么会出现重复现象?
因为在我们把系统解耦隔离后,服务间的调用可能会有三个状态,一个是成功(Success),一个是失败(Failed),一个是超时(Timeout)。前两者都是明确的状态,而超时则是完全不知道是什么状态。
比如:
1、订单创建接口第一次调用超时或者客户端浏览器等卡了一下,然后调用方重试了一次。是否会多创建一笔订单?
2、订单创建时,我要去扣减库存,这是接口发生了超时,调用方重试了一次。是否会多扣一次库存?
那这个时候我们就需要对重复数据做处理,保证数据的一致性。这个时候就需要我们的服务是幂等的。“相同”请求的数据只保存一份。
4、幂等的本质
我们的各种业务操作基本上都会存储在数据库(DB)中。所以我们分析一下CRUD四种操作的幂等性。
首先C就是create对应一般数据库就是 insert语句,如果就是普通的插入insert user ("name","age")重复两次执行这个sql它会产生两条数据,所以C不是幂等操作,使我们解决的问题之一。
第二个R就是Read读操作,对应数据库就是select,执行数据库sql select name from user where name="name"每次读不会引起数据的变化所以读操作的天然的幂等。
第三个U就是update操作,执行sql语句可能时 update user set age=age+1 where name="name",这个sql操作会引起数据的变更多次执行造成副作用非常明显,每执行一次sql age值就会加一操作。多以update操作不是幂等的我们需要针对处理。
第四个D对应的就是delete操作,一般执行sql为 delete from user where name="name",这个sql执行一次或者多次sql都是执行成功的,虽然第二次执行没有真正的删除数据,但是没有造成副作用的影响。
所以我们之所以需要我们的服务要幂等的,就是因为写数据和更新数据会引起的数据不一致。
5、具体案例的具体方案
业务场景1
扣款场景:先查询余额够不够然后进行各种打折求和逻辑运算,最后更新余额。
场景分析:上面的场景我们基本可以抽象成如下过程
1查询余额->2逻辑运算->3修改数据
对应的操作如下
1:select money from account where uid="uid" 结果money=100
2:加入商品50打8折,new_money=money>50*0.8?money-50*0.8:"余额不足"
3:update account set money=new_money where uid="uid"
上面我们提到 对于update操作数据库是不幂等的,需要我们的特殊处理。
我们分析一下上面的第3步update语句,加入同一个账户app端和web端都有登录,同时提交了不同订单支付就会出现两条update语句并且new_money数据不一致(是否一致都会导致同样的问题,这里只是说明一种明显的情况),这样就会造成一条sql覆盖另一条sql执行的结果现象。显然第3步不是幂等的会产生数据不一致问题。
业务场景1实现方案:
一般实现方案:在第3条update改写为如下语句
update account set money=new_money where uid="uid" and money=100
对于要求不高并发量并不算太大的情况下这样操作基本就可以了。
但是这个方案会产生ABA的问题
分析一下如下3个并发线程执行过程
线程1:获取到money=100,还没有执行完处于逻辑计算中
线程2:获取到money=100,new_money=100-47并且回写DB为money=53
线程3:获取到money=53,new_money=53+47并且回写DB为money=100
这个时候线程1在线程2和线程3完成之后在更新DB,执行成功返回影响行数为1。虽然说更新成功了,但是此时的100已经不是线程1当初读取时的100了
这种情况对于像余额、库存等没有什么影响,但是如果你实现的是堆栈,就是说前后操作如果有顺序就有可能出现数据不一致问题。
特殊实现方案:
在表中增加一个version字段update语句修改如下
update account set money=new_money,version=new_version where uid="uid" and version=old_version
有人问可不可以使用如下sql(diff为有增加或减少的差值)
update account set money=money-diff where uid="uid"
不可以,可以想象一下会发生什么情况(多次执行此sql会出现负值和重复增加或减少现象,不幂等)
一般扣款、充值等可以使用一般方案来实现。
业务场景2
web多次请求:
我们在浏览器或者app端在没有等到服务端对应的响应的时候可能会出现重复提交请求现象。同时业务上依然会有人为的重复操作,比如一些异步请求,我连续两次相同请求不知道哪个请求先到达如果幂等没有处理好就会出现两条一模一样的数据。
请求场景分析:我们在网上商城购买物品的时候会有下单操作,当我们点击了下单按钮之后没有等到服务端返回的时候可能会多次点击下单按钮,或者我们的操作系统卡顿了一下,我们以为没有点击成功,引起多次点击的情况。这个时候就会触发多次提交后台服务同样的数据。
还有就是我们的网关层、rpc框架、数据访问层可能会有重发机制,这就不可避免的造成技术上的数据重复。
这个场景问题解决的关键就是能有一个值是唯一标识这个请求的,比如订单号,请求码等等。
一般实现方案:
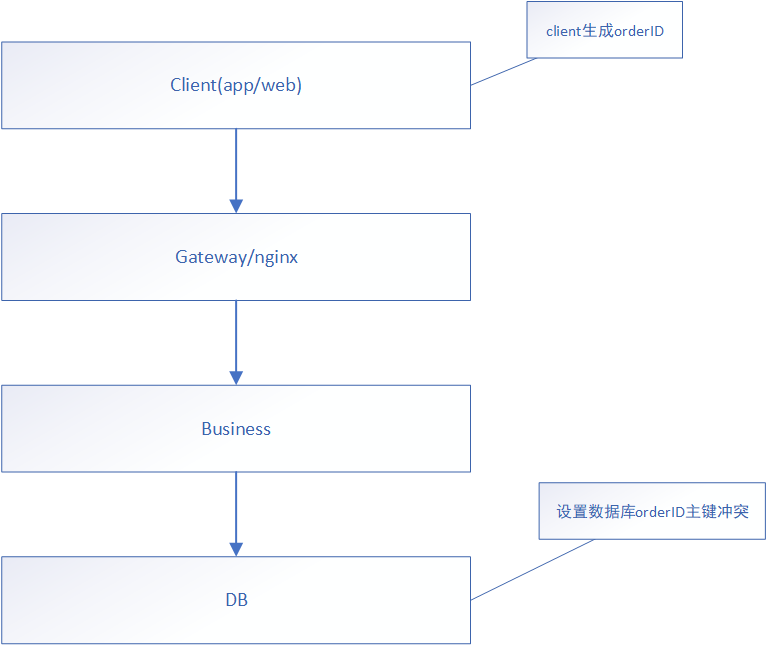
一般实现方案就是在客户端生成一个orderID,我们最容易想到的就是uuid,但是uuid没有顺序性,比较长,而且一堆字母实用意义非常小。所以这里我们可以使用Snowflake方法生成(我们微服务群里面已经有此微服务 uid 专门提供生成唯一ID服务,大家可以使用。)orderID。但是这里一定要注意,orderID的获取一定要在客户端获取到,也就是发送订单数据之前必须获取到orderID,并且这个值与提交表单绑定,已经存在的情况下不能变动,除非有类似刷新操作。
但是这个方案有一个安全问题,如果让别人知道你是这么设计的就会有被攻击的可能,因为它有非常大的可能猜到其他订单的ID是什么以及下一个订单的ID,这个时候他发起更多请求就会造成数据库崩溃等一系列问题。所以下面弥补这个问题。
其他方案:
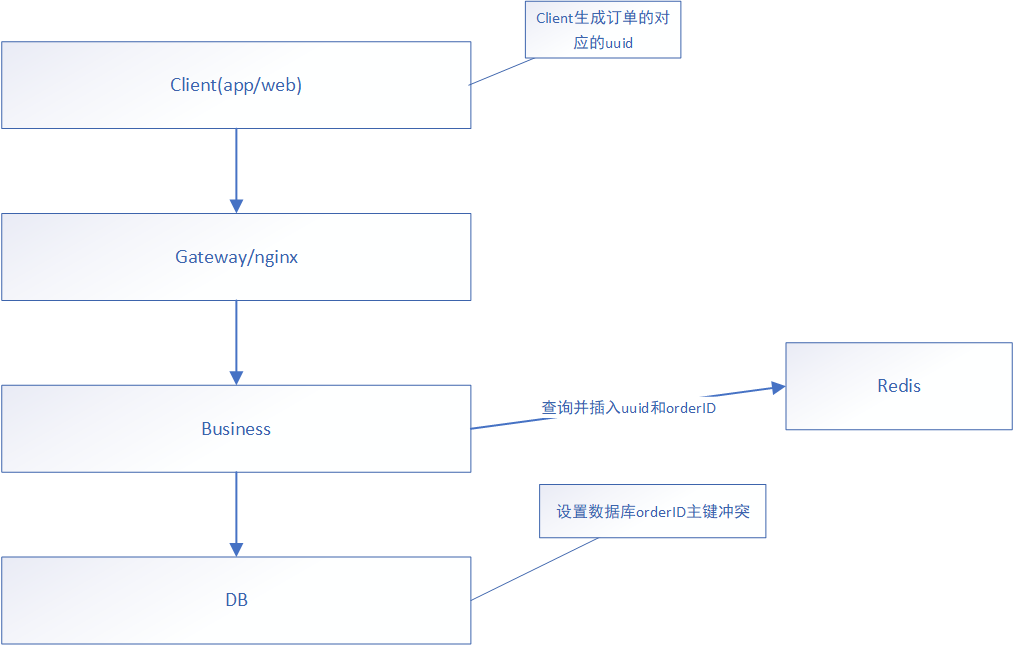
本方案实现过程如下:
1、client端生成与订单数据对应的uuid
2、点击确认提交的时候uuid一同与订单提交(一个表单请求)
3、在业务逻辑层(业务微服务)中做如下逻辑处理
先在redis中查询key为uuid的数据
如果存在数据,既获取到orderID使用即可,也可直接返回等逻辑处理
如果没有查询到,获取orderID并写入redis数据(key:uuid,value:orderID加锁操作,但是这里不会阻塞)
正常调用数据访问层(DB是否设置orderID主键冲突都可以)
这样前端app就不用显式生成订单ID了。
一般client端是点击提交表单按钮之后按钮马上处于禁用状态,或者302跳转页面并把之前的表单设置为过期(PRG模式|Post/Redirect/Get)
业务场景3
场景描述:消费MQ消息重复,或者重复消费MQ消息
我们目前使用的是RocketMQ,MQ它本身是有去重逻辑的,如果是rocketmq客户端触发重复发送这个时候MQ本身会做去重的幂等处理我们不用关系。
我们应该关心的是我们业务上的重复数据处理问题。
和上面的场景一样必须有一个唯一的标识来标记这条消息
有了这个标识在数据库中做唯一索引即可。
或者执行 upset操作,mysql mongodb hbase等都支持此操作
业务场景4
场景描述:带状态的数据,一般就是一条数据的状态可能会是1 2 3 4 并且更新状态是有顺序的比如 我想更新状态为 2 但是这个时候状态为3 是不可以的。只有状态为1的情况下才可以更新状态为2.
这个时候我们可以套用上面给数据行加版本的方式 在where条件中增加一个状态判断
业务场景5
场景描述:如果你的整个操作包含很多步骤建议拆分成最小步骤然后针对解决
终极方案:分布式锁
参考链接

 浙公网安备 33010602011771号
浙公网安备 33010602011771号