

基于keras的胶囊网络(CapsNet)
1 简介
胶囊网络(CapsNet)由 Hinton 于2017年10月在《Dynamic Routing Between Capsules》中提出,目的在于解决 CNN 只能提取特征,而不能提取特征的状态、方向、位置等信息,导致模型的泛化(举一反三)能力较差,如:
(1)将图片旋转180°,CNN 模型可能不能准确识别,因为 CNN 模型不能识别特征的方向信息,如需识别倒着的图片,需要使用倒着的图片训练 CNN 模型;
(2)将某人脸部图片的眼睛和嘴巴位置调换,CNN 模型可能也会识别为此人,因为 CNN 模型只关注眼睛、鼻子、耳朵、嘴巴等脸部特征是否准确,而不关注特征位置是否正确。
传统神经网络的基本单位是神经元,表示一个标量;胶囊网络的基本单位是胶囊(capsule),表示一个向量,由于向量有方向和大小,因此能够识别特征的状态、方向、位置等信息。
2 基本原理
胶囊网络(CapsNet)主要由动态路由层(Dynamic Routing Layer)堆叠而成,本节主要讲解动态路由层的前向传播原理。
胶囊网络的结构与全连接层相似,如下图所示:
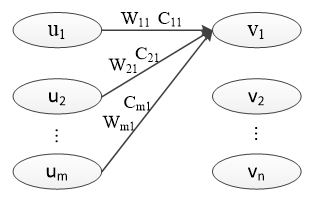 胶囊网络结构
胶囊网络结构
其中,u1,u2,...,um 为底层胶囊,v1,v2,...,vn 为高层胶囊,W 和 C 为待调参数,W 通过网络反向传播更新,C 通过动态路由算法更新。
2.1 前向传播
前向传播公式如下:
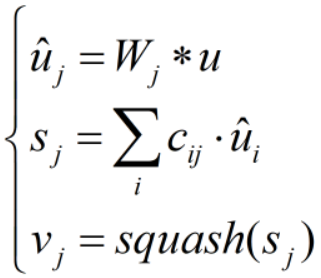
u 为上层胶囊输出,v 为本层胶囊输出。W 不一定是全连接形式的参数,“”也不一定是向量乘法运算;通常,“”指一维卷积运算,W 指卷积核。c 为耦合系数,由动态路由算法获取。squash 为激活函数,如下式所示:
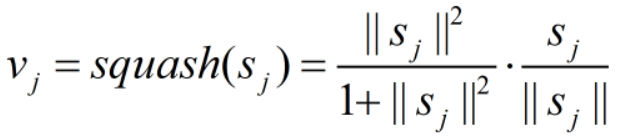
从上式可以看出,vj 和 sj 方向相同,并且 vj 的模长经squash()函数非线性映射到 [0, 1) 上,增加了模型的非线性映射能力。
2.2 动态路由
c 通过动态路由算法获取,在模型的反向传播中,不更新 c 的取值。动态路由算法的核心公式如下:
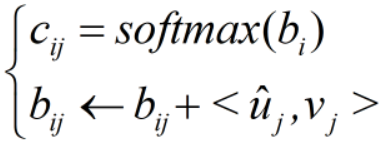
其中,<>表示内积运算,bi 的维度与 ui 的维度相同,初值为0。
为方便清晰查看胶囊网络中数据流向,笔者绘制了数据流向图如下:(注:图中省略了复杂的变量角标)
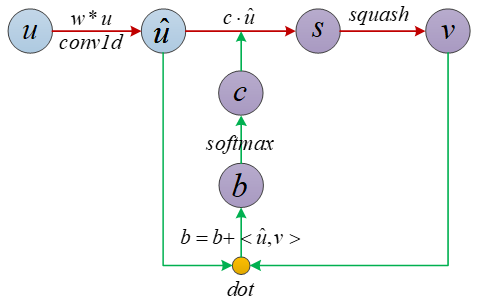
其中,红线表示前向传播数据流向,绿线表示动态路由数据流向;带紫色圆圈背景的变量表示在动态路由算法中会更新的变量。从图中可以看出,cij 的大小主要取决于 <ui, vj> ,即 vj 与 ui 的相似度,因此,当 vj 与 ui 较相似时,cij 较大,这点有点像注意力机制。
2.3 损失函数——Margin Loss
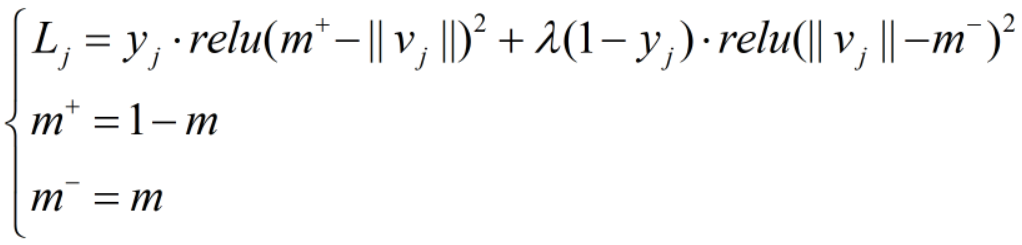
其中,y 为预测值,m 和 λ 为待调参数,通常 m=0.1 、 λ =0.5
3 实验
本文以 MNIST 手写数字分类为例,讲解胶囊网络模型。关于 MNIST 数据集的说明,见使用TensorFlow实现MNIST数据集分类。通过在 CNN 模型的最后一层叠加一层动态路由层,并将每个胶囊输出向量的模长作为提取数字特征的强度。
笔者工作空间如下:

代码资源见--> CapsNet
CapsuleLayer.py
from keras import backend as K
from keras.layers import Layer
"""
压缩函数,使用0.5替代hinton论文中的1,如果是1,所有的向量的范数都将被缩小。
如果是0.5,小于0.5的范数将缩小,大于0.5的将被放大
"""
def squash(x, axis=-1):
s_quared_norm = K.sum(K.square(x), axis, keepdims=True) + K.epsilon() #||x||^2
scale = K.sqrt(s_quared_norm) / (0.5 + s_quared_norm) #||x||/(0.5+||x||^2)
result = scale * x
return result
# 定义我们自己的softmax函数,而不是K.softmax.因为K.softmax不能指定轴
def softmax(x, axis=-1):
ex = K.exp(x - K.max(x, axis=axis, keepdims=True))
result = ex / K.sum(ex, axis=axis, keepdims=True)
return result
# 定义边缘损失,输入y_true, p_pred,返回分数,传入fit即可
def margin_loss(y_true, y_pred):
lamb, margin = 0.5, 0.1
result = K.sum(y_true * K.square(K.relu(1 - margin -y_pred))
+ lamb * (1-y_true) * K.square(K.relu(y_pred - margin)), axis=-1)
return result
class Capsule(Layer):
def __init__(self,
num_capsule,
dim_capsule,
routings=3,
share_weights=True,
activation='squash',
**kwargs):
super(Capsule, self).__init__(**kwargs) # Capsule继承**kwargs参数
self.num_capsule = num_capsule
self.dim_capsule = dim_capsule
self.routings = routings
self.share_weights = share_weights
if activation == 'squash':
self.activation = squash
else:
self.activation = activation.get(activation) # 得到激活函数
# 定义权重
def build(self, input_shape):
input_dim_capsule = input_shape[-1]
if self.share_weights:
# 自定义权重
self.kernel = self.add_weight( #[row,col,channel]->[1,input_dim_capsule,num_capsule*dim_capsule]
name='capsule_kernel',
shape=(1, input_dim_capsule,
self.num_capsule * self.dim_capsule),
initializer='glorot_uniform',
trainable=True)
else:
input_num_capsule = input_shape[-2]
self.kernel = self.add_weight(
name='capsule_kernel',
shape=(input_num_capsule, input_dim_capsule,
self.num_capsule * self.dim_capsule),
initializer='glorot_uniform',
trainable=True)
super(Capsule, self).build(input_shape) # 必须继承Layer的build方法
# 层的功能逻辑(核心)
def call(self, inputs):
if self.share_weights:
#inputs: [batch, input_num_capsule, input_dim_capsule]
#kernel: [1, input_dim_capsule, num_capsule*dim_capsule]
#hat_inputs: [batch, input_num_capsule, num_capsule*dim_capsule]
hat_inputs = K.conv1d(inputs, self.kernel)
else:
hat_inputs = K.local_conv1d(inputs, self.kernel, [1], [1])
batch_size = K.shape(inputs)[0]
input_num_capsule = K.shape(inputs)[1]
hat_inputs = K.reshape(hat_inputs,
(batch_size, input_num_capsule,
self.num_capsule, self.dim_capsule))
#hat_inputs: [batch, input_num_capsule, num_capsule, dim_capsule]
hat_inputs = K.permute_dimensions(hat_inputs, (0, 2, 1, 3))
#hat_inputs: [batch, num_capsule, input_num_capsule, dim_capsule]
b = K.zeros_like(hat_inputs[:, :, :, 0])
#b: [batch, num_capsule, input_num_capsule]
for i in range(self.routings):
c = softmax(b, 1)
o = self.activation(K.batch_dot(c, hat_inputs, [2, 2]))
if K.backend() == 'theano':
o = K.sum(o, axis=1)
if i < self.routings-1:
b += K.batch_dot(o, hat_inputs, [2, 3])
if K.backend() == 'theano':
o = K.sum(o, axis=1)
return o
def compute_output_shape(self, input_shape): # 自动推断shape
return (None, self.num_capsule, self.dim_capsule)
注:以上代码来自--> https://github.com/bojone/Capsule
CapsNet.py
from keras import backend as K
from tensorflow.examples.tutorials.mnist import input_data
from keras.models import Model
from keras.layers import Input,Conv2D,MaxPooling2D,Reshape,Lambda
from CapsuleLayer import Capsule,margin_loss
#载入数据
def read_data(path):
mnist=input_data.read_data_sets(path,one_hot=True)
train_x,train_y=mnist.train.images.reshape(-1,28,28,1),mnist.train.labels,
valid_x,valid_y=mnist.validation.images.reshape(-1,28,28,1),mnist.validation.labels,
test_x,test_y=mnist.test.images.reshape(-1,28,28,1),mnist.test.labels
return train_x,train_y,valid_x,valid_y,test_x,test_y
#模型
def MODEL():
inputs=Input(shape=(28, 28, 1))
x=Conv2D(16, (5, 5), padding='same', activation='relu')(inputs)
x=MaxPooling2D(pool_size=(2,2))(x)
x=Conv2D(32, (5, 5), padding='same', activation='relu')(x)
x=MaxPooling2D(pool_size=(2,2))(x)
x=Reshape((-1, 32))(x) # [None, 49, 32] 即前一层胶囊 [None, input_num, input_dim]
x=Capsule(num_capsule=10, dim_capsule=30, routings=5)(x)
output=Lambda(lambda z: K.sqrt(K.sum(K.square(z), axis=2)))(x) #每个胶囊取模长
model=Model(inputs=inputs, output=output)
return model
#主函数
def main(train_x,train_y,valid_x,valid_y,test_x,test_y):
model = MODEL()
model.compile(loss=margin_loss, optimizer='adam', metrics=['accuracy'])
model.summary()
model.fit(train_x,train_y,batch_size=500,nb_epoch=20,verbose=2)
pre=model.evaluate(test_x,test_y,batch_size=500,verbose=2)
print('test_loss:',pre[0],'- test_acc:',pre[1])
train_x,train_y,valid_x,valid_y,test_x,test_y=read_data('MNIST_data')
main(train_x,train_y,valid_x,valid_y,test_x,test_y)
网络各层输出尺寸:
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) (None, 28, 28, 1) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 28, 28, 16) 416
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 14, 14, 16) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 14, 14, 32) 12832
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 7, 7, 32) 0
_________________________________________________________________
reshape_1 (Reshape) (None, 49, 32) 0
_________________________________________________________________
capsule_1 (Capsule) (None, 10, 30) 9600
_________________________________________________________________
lambda_1 (Lambda) (None, 10) 0
=================================================================
Total params: 22,848
Trainable params: 22,848
Non-trainable params: 0
网络训练结果:
Epoch 18/20
- 42s - loss: 0.0247 - acc: 0.9816
Epoch 19/20
- 43s - loss: 0.0239 - acc: 0.9828
Epoch 20/20
- 43s - loss: 0.0234 - acc: 0.9825
test_loss: 0.024427699740044773 - test_acc: 0.9793000012636185
4 扩展阅读
声明:本文转自基于keras的胶囊网络(CapsNet)


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享4款.NET开源、免费、实用的商城系统
· 全程不用写代码,我用AI程序员写了一个飞机大战
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· 白话解读 Dapr 1.15:你的「微服务管家」又秀新绝活了
· 上周热点回顾(2.24-3.2)