
Java8新特性
准备
先看2个例子
1.筛选集合中年龄大于20的用户的用户名列表,并输出
1 // 初始化集合 2 List<User> users = Arrays.asList( 3 new User("周一", 20), 4 new User("吴二", 25), 5 new User("郑三", 30), 6 new User("王四", 35) 7 );
普通方式
1 List<String> userNames = new ArrayList<>(); 2 for (User user : users) { 3 if (user.getAge().intValue() > 20) { 4 userNames.add(user.getName()); 5 } 6 } 7 for (String userName : userNames) { 8 System.out.println(userName); 9 }
java8方式
1 users.stream() 2 .filter(user -> user.getAge().intValue() > 20) 3 .map(User::getName) 4 .forEach(System.out::println);
2.Integer集合排序
1 // 初始化集合 2 List<Integer> integers = Arrays.asList(5, 4, 3, 2, 1);
普通方式
1 integers.sort(new Comparator<Integer>() { 2 @Override 3 public int compare(Integer o1, Integer o2) { 4 return Integer.compare(o1, o2); 5 } 6 }); 7 System.out.println(integers);
java8方式
1 integers.sort((x, y) -> Integer.compare(x, y)); 2 System.out.println(integers);
更精简一点
1 integers.sort(Integer::compare); 2 System.out.println(integers);
Lambda表达式
匿名内部类的方式,会有大量的样板代码(固定代码),如
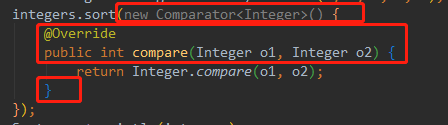
而且对这个例子而言,我们真正的意图是要传递一个如何进行排序的操作,而这里传递的是一个对象,无法清晰的描述我们的意图。
Lambda表达式一方面化简了样板代码,另一方面是传递方法、操作、行为。
Lambda表达式结构分为两部分,以->分隔,->左边的是参数,->右边的是表达式内容,如下:
user -> user.getAge().intValue() > 20
参数 执行的操作
类型推断
List<String> userNames = new ArrayList<>(); // new时未指定泛型
javac可以根据上下文推断泛型类型,如上面的代码中,定义的list的泛型是String,则在new时无需再指定。
Lembda表达式中也可以做类型推断,如下面的代码,无需指定参数x, y的类型,因为integers集合的泛型是Integer类型,javac可以根据上下文推断出来。
integers.sort((x, y) -> Integer.compare(x, y));
函数式接口
使用Lembda表达式,其实是java帮助我们实现了接口(如果sort中的Comparator接口),但是接口里面有两个抽象方法会怎样?
使用Lembda表达式对接口的要求是,接口中只能有一个抽象方法,这种接口被称为函数式接口。java8中提供了@FunctionInterface注解,用于标识和约束函数式接口。
默认方法
接口中可以添加默认方法,即非抽象方法,可以被继承、重写。
静态方法
接口中可以添加静态方法,和普通类中的静态方法一样
Stream-Api
Stream是用函数式变成的方式在集合类上进行复杂操作的工具。
映射
map,从原有数据映射成新的数据,数据类型可以不一致,下面的代码是从user映射成username

过滤
过滤符合条件的数据,定义的Lambda表达式需返回boolean值

收集
转成另一个集合,如list,set,map等

归约
化简/合并数据,如计算Integer集合的累加值,identity参数为累加起始值

方法引用
如下面的代码,javac可以推断出map的参数是User类型,则表达式可以化简为User::getName,注意没有(),因为不是去调用getName方法而是传递这个操作。
Parallel
并行化是把工作进行拆分在多核cpu上执行的方式。
通过 integers.parallelStream() 或者 integers.stream().parallel() 可以创建并行stream,充分利用cpu资源,底层基于forkjoin模式。
所以需要注意,forkjoin中会有工作拆分和结果汇总操作,这部分操作会占用一部分时间,所以这种方式只适合处理大数据。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号