后缀自动机
极强大的字符串算法。
endpos
定义 \(s\) 的一个子串的 \(\operatorname{endpos}\) 为该子串在 \(s\) 中所有出现的结尾位置的集合。
例如 \(s=\text{ababc}\),则 \(\operatorname{endpos}(\text{ab})=\{2,4\}\)(字符位置从 \(1\) 开始编号)。因为 \(\text{ab}\) 在 \(\text{ababc}\) 中出现了 \(2\) 次,这两次的结尾位置分别为 \(2\) 和 \(4\)。
一些结论:
引理 1: 若 \(u,v\) 为 \(s\) 的子串(\(|u|\le|v|\)),则要么 \(\operatorname{endpos}(u)\subseteq\operatorname{endpos}(v)\),要么 \(\operatorname{endpos}(u)\cap\operatorname{endpos}(v)=\varnothing\)。
如果 \(u\) 为 \(v\) 的后缀,则在 \(v\) 任意一次出现的位置,\(u\) 一定也出现了,所以 \(\operatorname{endpos}(u)\subseteq\operatorname{endpos}(v)\)。
如果 \(u\) 不是 \(v\) 的后缀,则在 \(v\) 任意一次出现的位置,\(u\) 一定没有出现,所以 \(\operatorname{endpos}(u)\cap\operatorname{endpos}(v)=\varnothing\)。
将 \(\operatorname{endpos}\) 相同的子串归为一类,叫做 \(\operatorname{endpos}\) 等价类。
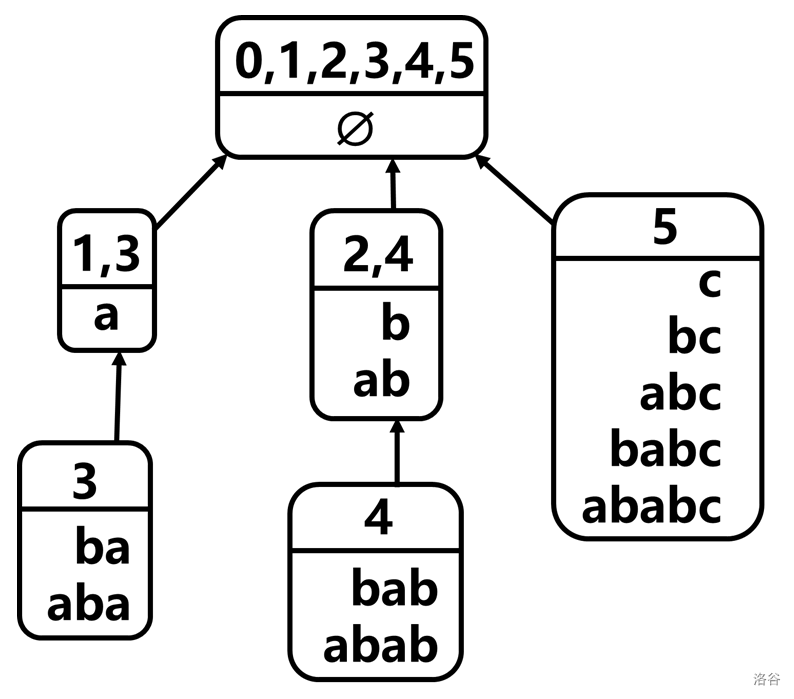
例如 \(\text{ababc}\) 有 \(5\) 个 \(\operatorname{endpos}\) 等价类:
\(\operatorname{endpos}=\{1,3\}\):\(\text{a}\)
\(\operatorname{endpos}=\{3\}\):\(\text{ba},\text{aba}\)
\(\operatorname{endpos}=\{2,4\}\):\(\text{b},\text{ab}\)
\(\operatorname{endpos}=\{4\}\):\(\text{bab},\text{abab}\)
\(\operatorname{endpos}=\{5\}\):\(\text{c},\text{bc},\text{abc},\text{babc},\text{ababc}\)
观察可发现:
引理 2: 任意一个 \(\operatorname{endpos}\) 等价类里的字符串,依次为后者的后缀,且长度递增。
感性理解:从某个子串开始,不断向前添加字符,\(\operatorname{endpos}\) 不变。直到再添加字符 \(\operatorname{endpos}\) 就变了,那么这个过程中得到的所有字符串构成一个 \(\operatorname{endpos}\) 等价类。
结合两个引理可知:\(\operatorname{endpos}\) 的包含关系构成树,称为 parent tree。例如 \(\text{ababc}\) 的 parent tree 为:
实际上,parent tree 的结点就是后缀自动机的结点:
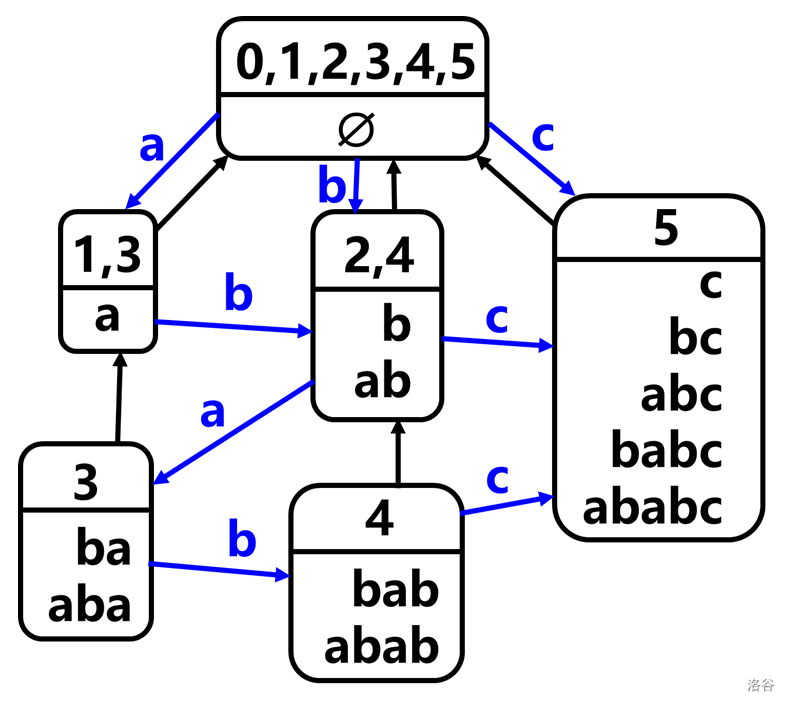
parent tree 结点包含的字符串就是在 SAM 上能走出来的字符串。
回顾
SAM 比较复杂,在这里回顾一下这些定义,读者可以对照上面的后缀自动机来理解。
在 SAM 中,结点有两个含义:\(\text{endpos}\) 和一些字符串。(在图中,我用横线把一个结点分成了两份,上面的是 \(\text{endpos}\),下面的就是那些字符串)
在 SAM 中,有两种边:parent tree 边(黑边)和 Trie 边(蓝边)。
两个结点的 \(\text{endpos}\) 要么一个包含于另一个,要么没有交集。包含关系构成 parent tree。
如果 \(u\) 的 \(\text{endpos}\) 包含于 \(v\),则 \(u\) 代表的字符串为 \(v\) 的后缀。
从一个字符串的开头不断删字符,相当于沿 parent tree 向上走。特别地,从整个字符串(上图中为 \(\text{ababc}\))的所有后缀是一条在 parent tree 上的链(上图中包括 \(\{0,1,2,3,4,5\}\) 和 \(\{5\}\) 两个结点),下文称为后缀链。
设有一条 Trie 边 \((u,v)\),字符为 \(c\)。则 \(u\) 代表的每个字符串末尾添加字符 \(c\) 后,得到的字符串都属于 \(v\)。(比如在上图中,结点 \(\{2,4\}\) 包含两个字符串:\(\text{b}\) 和 \(\text{ab}\)。将两个字符串结尾都加上字符 \(c\),得到的 \(\text{bc}\) 和 \(\text{abc}\) 都在结点 \(\{5\}\) 里。而正好有一条字符为 \(c\) 的 Trie 边从 \(\{2,4\}\) 指向 \(\{5\}\))
根的 \(\text{endpos}\) 应该包含从 \(0\) 到字符串长度的所有正整数(试着建立 \(\text{aa}\) 的 SAM,你就知道为什么要包含 \(0\) 了),根代表的字符串一般认为是空串。或者你也可以认为根就是个形式,没有实际意义。
建立
建立 SAM 的算法是在线的,即每添加一个字符就能马上得到当前的 SAM。
设原串为 \(s\),添加的字符为 \(c\),则新串为 \(s+c\)(下文称为新串),新串的长度为 \(n\)。
实际上,我们只需要在 SAM 里添加新串的所有后缀。这些后缀中可能有些在 \(s\) 中出现过(下文称为旧字符串),有些没出现过(例如 \(s+c\) 在 \(s\) 中肯定没出现过)(下文称为新字符串,区别于新串)。
情况 1
新串的所有后缀都是新字符串。
例:\(s=\text{abab},c=\text{c}\)。
添加字符之前的字符串 \(s=\text{abab}\) 的后缀自动机如图:
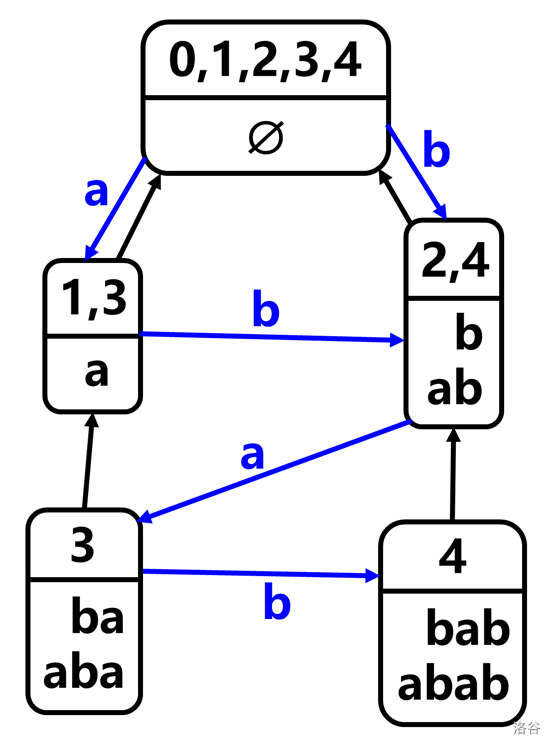
\(s+c=\text{ababc}\) 的所有后缀为 \(\text{c,bc,abc,babc,ababc}\),在上图中都没出现。
也就是说这五个字符串的 \(\text{endpos}\) 都为 \(\{5\}\)。
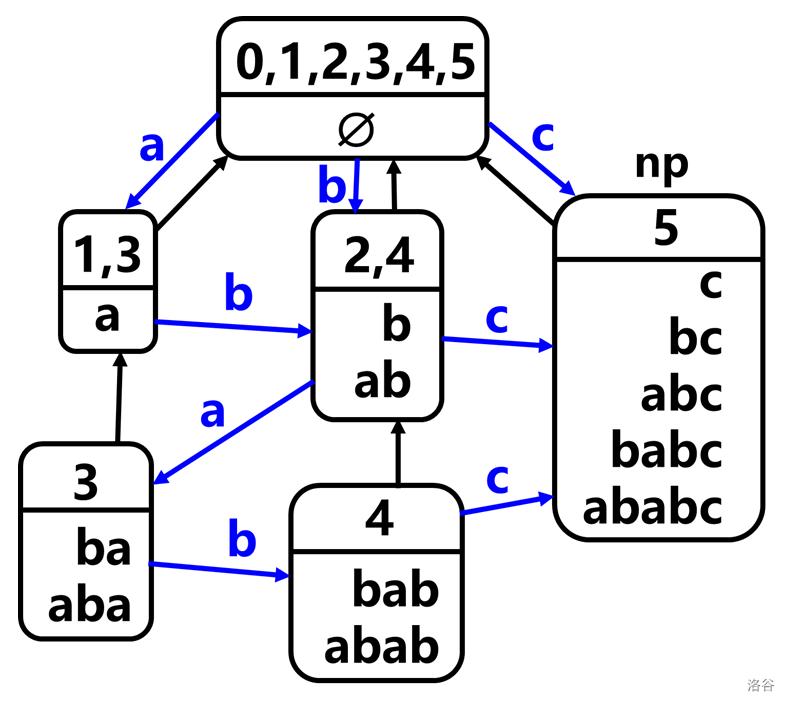
所以添加一个结点 \(np\)(名字和代码统一)(可结合下图理解),表示 \(\text{endpos}=\{5\}\),包含 \(\text{c,bc,abc,babc,ababc}\) 这五个字符串。
然后考虑 \(np\) 在 parent tree 上的父结点,应该是根,因为其他结点的 \(\text{endpos}\) 都不包含 \(5\)。(注意这里根的 \(\text{endpos}\) 自动添加了一个 \(5\))
再考虑哪些结点的 Trie 边需要指向 \(np\)。注意到原串的所有后缀加上 \(c\) 都是新串的后缀,所以应该将后缀链上的每个结点都指向 \(np\)。
情况 2
新串的后缀既有新字符串又有旧字符串。
例:\(s=\text{aba},c=\text{b}\)。
原自动机如图:
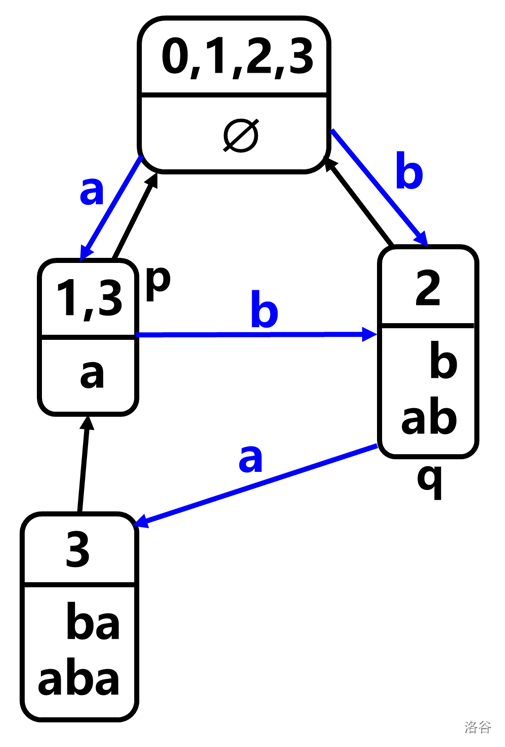
\(s+c\) 的所有后缀为 \(\text{b,ab,bab,abab}\)。其中前两个在原 SAM 中出现了,为结点 \(\{2\}\)。
(我们称结点 \(\{2\}\) 为 \(q\),称 \(\{1,3\}\) 结点为 \(p\))
注意到结点 \(q\) 中的所有字符串都是 \(s+c\) 的后缀,所以可以将 \(q\) 的 \(\text{endpos}\) 从 \(\{2\}\) 变成 \(\{2,4\}\)。
对于 \(\text{bab,abab}\) 这两个字符串,还是需要新建一个结点 \(np\),其 \(\text{endpos}=\{4\}\)。
考虑 \(np\) 的父结点,应该为 \(q\)。
考虑指向 \(np\) 的结点,同样应该是后缀链上的结点。但是并不是所有,而应只是 \(p\) 以下的结点。(稍后将详细讨论)(可结合下图理解)
得到新 SAM:
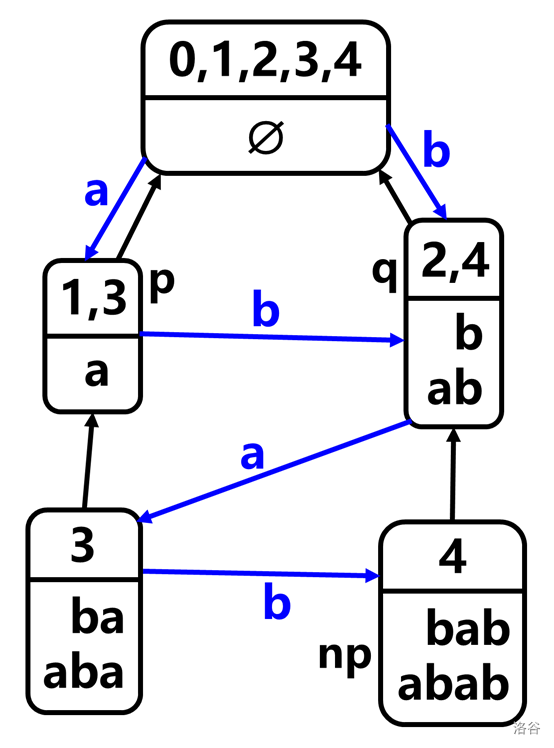
接下来仔细思考如何找到 \(q\)。
仍然,在原串的所有后缀后加一个 \(c\),将得到新串的所有后缀。
所以要想找 \(q\),只要找到其父结点 \(p\)。而 \(p\) 又在后缀链上,所以沿着后缀链找 \(p\) 即可。
后缀链上哪个是 \(p\) 呢?首先 \(p\) 必须要有一个 \(c\) 的 Trie 子结点(即 \(q\)),其次离根最远的那个就是。
如果不是离根最远的那个的话,虽然也能找到一个类似的 \(q\),但这个 \(q\) 可能并不是 \(np\) 的直接父结点,而只是一个普通的祖先结点。读者可以用 \(\text{ababa+b}\) 试一试。
最后的算法步骤就是:沿着后缀链向上爬,直到某个结点有 \(c\) 的 Trie 边,这条边指向的结点就是 \(q\)。
回到上图上面的问题:为什么在后缀链上,只有 \(p\) 以下的结点才连一条到 \(np\) 的边?因为 \(p\) 以及 \(p\) 以上的结点,都已经有这样的 Trie 子结点了(例如 \(p\) 就有 \(q\))。这些 Trie 子结点都是 \(np\) 的祖先,而非 \(np\) 本身。
情况 3
在情况 2 中,\(q\) 的所有字符串都是新串的后缀,如果不是呢?
例:\(s=\text{aaba},c=\text{b}\)。
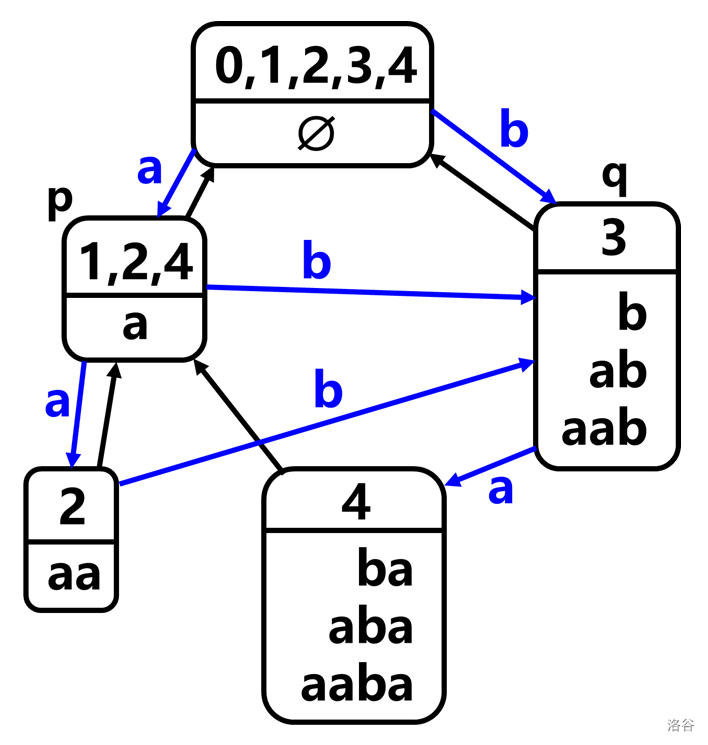
不妨直接把新串的 SAM 建出来看看。
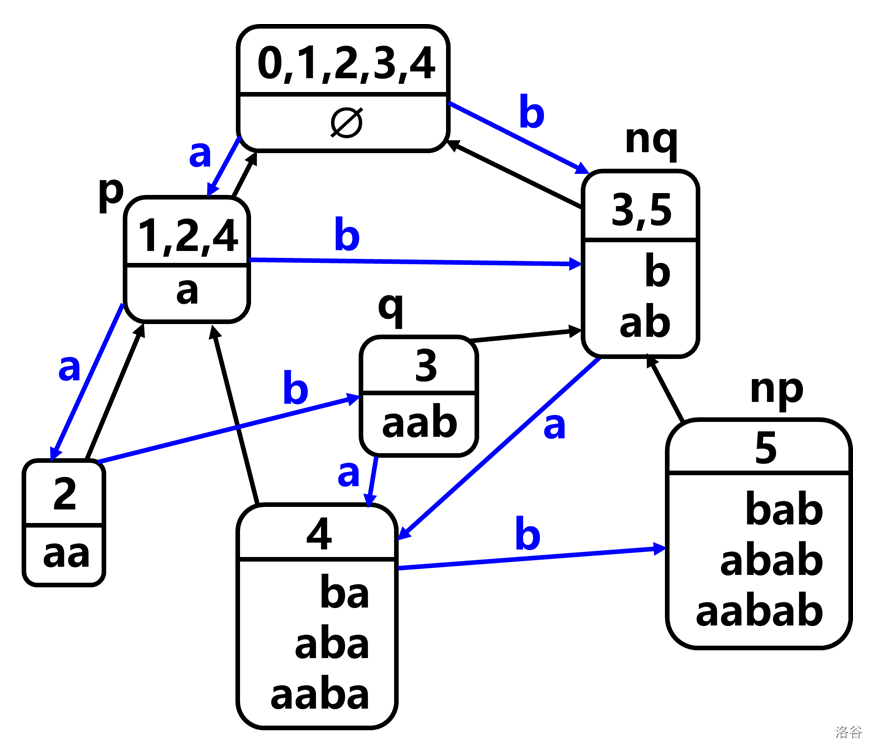
注意到第一张图中的 \(q\) 结点包含 \(\text{b,ab,aab}\),但是在第二张图中这三个字符串分到了两个结点里,我们称为 \(q\) 和 \(nq\)。
显然,我们需要分裂 \(q\) 结点,其中包含新串后缀的称为 \(nq\)。
其余和情况 2 类似,读者可以自己分析。只需考虑一件事:有些结点本来有 Trie 边指向 \(q\),现在需要指向 \(nq\);但有些结点不用改。
哪些需要改呢?既然要指向 \(nq\),那么它必然包含 \(nq\) 的前缀,而这样的字符串就是原串的后缀,在后缀链上。
所以只有在后缀链上,并且原本指向 \(q\) 的结点,才需要更改并指向 \(nq\)。
代码讲解
上面其实没讲完,剩下的对着代码讲吧。
SAM 代码极短,比线段树之类的简单数据结构还要短不少,轻松进 1K。
如果说 SA 有个 25 行简洁高效的代码,那么这就是 SAM 23 行的实现。
SAM 大概是 2012 年被陈立杰引入 OI 的,所以 2009 年的后缀树确实很复杂。
现在不是了,反串的 parent tree 就是后缀树,同样 23 行。
SA 的线性构造,比如 SA-IS、DC3 什么的似乎很厉害很学术,其实 SAM(构造的后缀树)就能线性构造 SA。
SAM nb
#include<bits/stdc++.h>
using namespace std;
const int N=2000010;//注意 SAM 需要开 2 倍数组
string S;
int cnt=1,lst=1,ch[N][26],fa[N],len[N];
int main(){
cin>>S;
for(int i=0;i<S.length();i++){
int p=lst,c=S[i]-'a';
int np=lst=++cnt;
len[np]=len[p]+1;
for(;p&&!ch[p][c];p=fa[p]) ch[p][c]=np;
if(!p) { fa[np]=1; continue; }
int q=ch[p][c];
if(len[q]==len[p]+1){ fa[np]=q; continue; }
int nq=++cnt;
len[nq]=len[p]+1;
fa[nq]=fa[q]; fa[q]=fa[np]=nq;
for(int j=0;j<26;j++) ch[nq][j]=ch[q][j];
for(;p&&ch[p][c]==q;p=fa[p]) ch[p][c]=nq;
}
return 0;
}
cnt 是新建结点时的计数器,lst 是当前代表整个字符串的结点(找后缀链的时候显然要用)。
p 用来在沿着后缀链向上爬。
c np q nq 意义与文章相同。
ch 是 Trie 边,fa 是 parent tree 边,len 是结点代表的最长字符串的长度。
只需注意一点:如何区分情况 2 和情况 3。
将 \(p\) 最长的字符串加一个 \(c\) 字符,得到的字符串属于 \(q\)(Trie 边性质),所以 \(\text{len}_p+1\le\text{len}_q\)。
如果取等号,说明 \(q\) 中的所有字符串都是由 \(p\)(及其祖先)添加字符 \(c\) 得到的,是情况 2。
如果取小于号,说明 \(q\) 中有的字符串并不是 \(p\) 及其祖先添加字符得到的,是情况 3。
复杂度
OI-Wiki 写得不错,建议看 “正确性证明” “对操作次数为线性的证明” “更多性质” 三部分。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号