
ES--04
第三十一讲!
分布式文档系统 写一致性原理以及相关参数
课程大纲
(1)consistency,one(primary shard),all(all shard),quorum(default)
我们在发送任何一个增删改操作的时候,比如说put /index/type/id,都可以带上一个consistency参数,指明我们想要的写一致性是什么?
put /index/type/id?consistency=quorum
one:要求我们这个写操作,只要有一个primary shard是active活跃可用的,就可以执行
all:要求我们这个写操作,必须所有的primary shard和replica shard都是活跃的,才可以执行这个写操作
quorum:默认的值,要求所有的shard中,必须是大部分的shard都是活跃的,可用的,才可以执行这个写操作
(2)quorum机制,写之前必须确保大多数shard都可用,int( (primary + number_of_replicas) / 2 ) + 1,当number_of_replicas>1时才生效
quroum = int( (primary + number_of_replicas) / 2 ) + 1
举个例子,3个primary shard,number_of_replicas=1,总共有3 + 3 * 1 = 6个shard
quorum = int( (3 + 1) / 2 ) + 1 = 3
所以,要求6个shard中至少有3个shard是active状态的,才可以执行这个写操作
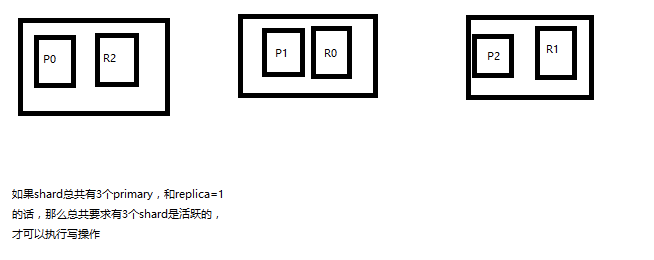
(3)如果节点数少于quorum数量,可能导致quorum不齐全,进而导致无法执行任何写操作
3个primary shard,replica=1,要求至少3个shard是active,3个shard按照之前学习的shard&replica机制,必须在不同的节点上,如果说只有2台机器的话,是不是有可能出现说,3个shard都没法分配齐全,此时就可能会出现写操作无法执行的情况(写操作只能在primary shard上进行)
es提供了一种特殊的处理场景,就是说当number_of_replicas>1时才生效,因为假如说,你就一个primary shard,replica=1,此时就2个shard
同样的replica shard也不允许放到一起
(1 + 1 / 2) + 1 = 2,要求必须有2个shard是活跃的,但是可能就1个node,此时就1个shard是活跃的,如果你不特殊处理的话,导致我们的单节点集群就无法工作
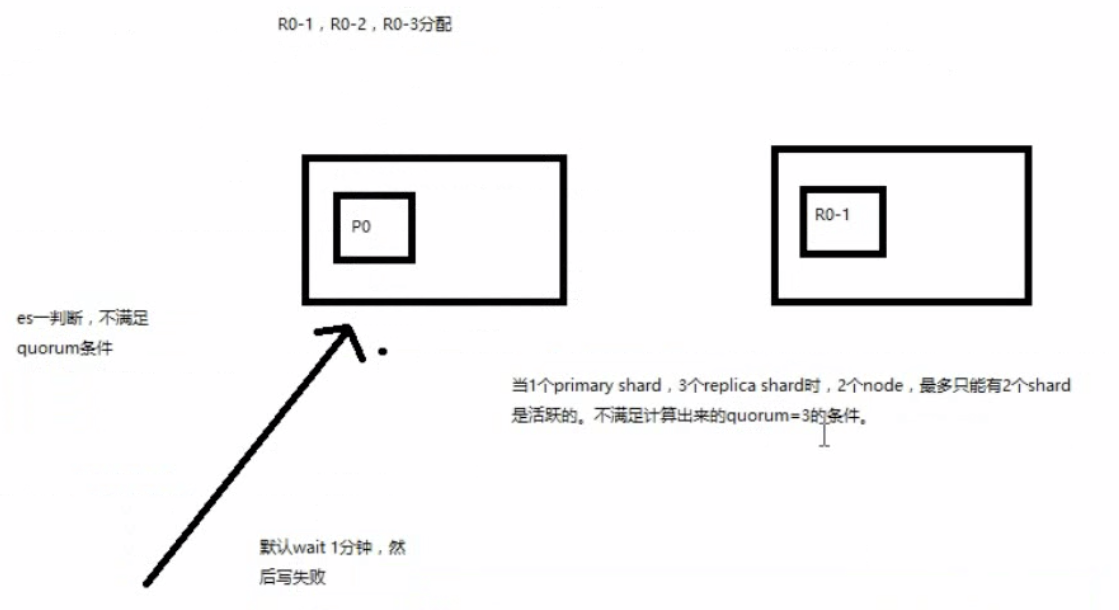
(4)quorum不齐全时,wait,默认1分钟,timeout,100,30s 默认是毫秒 加上s 就是秒
等待期间,期望活跃的shard数量可以增加,最后实在不行,就会timeout
我们其实可以在写操作的时候,加一个timeout参数,比如说put /index/type/id?timeout=30,这个就是说自己去设定quorum不齐全的时候,es的timeout时长,可以缩短,也可以增长
quorum不满足条件的场景
shard&replica机制
1.index包含多个shard
2.每个shard都是一个最小工作单元,承载部分数据,lucene实例,完整的建立索引和处理请求的能力
3.增减节点时,shard会自动在nodes中负载均衡
4.primary shard和replica shard,每个document肯定只存在于某一个primary shard以及其对应的replica shard中,不可能存在于多个primary shard
5.replica shard是primary shard的副本,负责容错,以及承担读请求负载
6.primary shard的数量在创建索引的时候就固定了,replica shard的数量可以随时修改
7.primary shard的默认数量是5,replica默认是1,默认有10个shard,5个primary shard,5个replica shard
8.primary shard不能和自己的replica shard放在同一个节点上(否则节点宕机,primary shard和副本都丢失,起不到容错的作用),但是可以和其他primary shard的replica shard放在 同一个节点上
第三十二讲!
document查询的内部原理实现
课程大纲
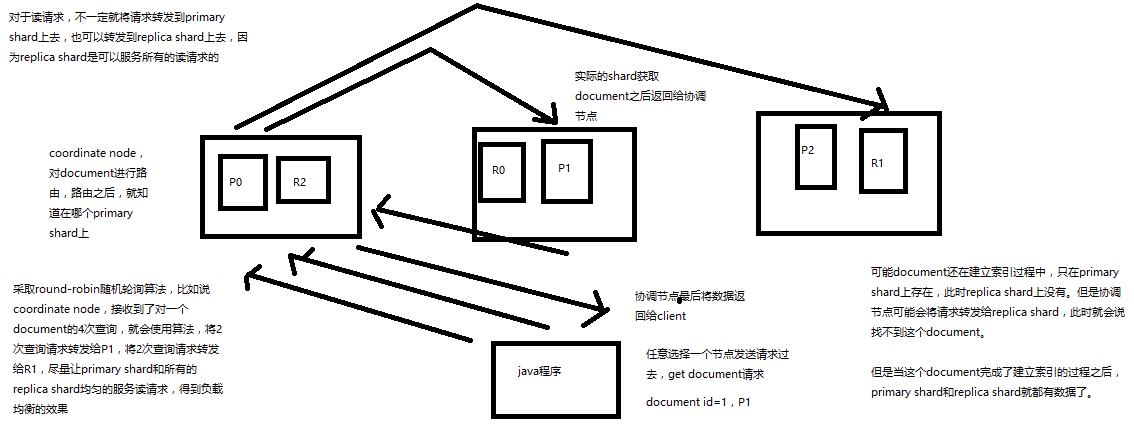
1、客户端发送请求到任意一个node,成为coordinate node
2、coordinate node对document进行路由,将请求转发到对应的node,此时会使用round-robin随机轮询算法,在primary shard以及其所有replica中随机选择一个,让读请求负载均衡
3、接收请求的node返回document给coordinate node
4、coordinate node返回document给客户端
5、特殊情况:document如果还在建立索引过程中,可能只有primary shard有,任何一个replica shard都没有,此时可能会导致无法读取到document,但是document完成索引建立之后,primary shard和replica shard就都有了
第三十三讲!
分布式文档系统 bulk api的奇特json格式与底层性能优化关系大解密!
课程大纲
bulk api奇特的json格式
{"action": {"meta"}}\n
{"data"}\n
{"action": {"meta"}}\n
{"data"}\n
[{
"action": {
},
"data": {
}
}]
1、bulk中的每个操作都可能要转发到不同的node的shard去执行
为什么不能采用常规格式
2、如果采用比较良好的json数组格式
允许任意的换行,整个可读性非常棒,读起来很爽,es拿到那种标准格式的json串以后,要按照下述流程去进行处理
(1)将json数组解析为JSONArray对象,这个时候,整个数据,就会在内存中出现一份一模一样的拷贝,一份数据是json文本,一份数据是JSONArray对象
(2)解析json数组里的每个json,对每个请求中的document进行路由
(3)为路由到同一个shard上的多个请求,创建一个请求数组
(4)将这个请求数组序列化
(5)将序列化后的请求数组发送到对应的节点上去
3、耗费更多内存,更多的jvm gc开销
我们之前提到过bulk size最佳大小的那个问题,一般建议说在几千条那样,然后大小在10MB左右,所以说,可怕的事情来了。假设说现在100个bulk请求发送到了一个节点上去,然后每个请求是10MB,100个请求,就是1000MB = 1GB,然后每个请求的json都copy一份为jsonarray对象,此时内存中的占用就会翻倍,就会占用2GB的内存,甚至还不止。因为弄成jsonarray之后,还可能会多搞一些其他的数据结构,2GB+的内存占用。
占用更多的内存可能就会积压其他请求的内存使用量,比如说最重要的搜索请求,分析请求,等等,此时就可能会导致其他请求的性能急速下降
另外的话,占用内存更多,就会导致java虚拟机的垃圾回收次数更多,跟频繁,每次要回收的垃圾对象更多,耗费的时间更多,导致es的java虚拟机停止工作线程的时间更多
4、现在的奇特格式
{"action": {"meta"}}\n
{"data"}\n
{"action": {"meta"}}\n
{"data"}\n
(1)不用将其转换为json对象,不会出现内存中的相同数据的拷贝,直接按照换行符切割json
(2)对每两个一组的json,读取meta,进行document路由
(3)直接将对应的json发送到node上去
5、最大的优势在于,不需要将json数组解析为一个JSONArray对象,形成一份大数据的拷贝,浪费内存空间,尽可能地保证性能
第三十四讲!
_search结果解析
课程大纲
1、我们如果发出一个搜索请求的话,会拿到一堆搜索结果,本节课,我们来讲解一下,这个搜索结果里的各种数据,都代表了什么含义
2、我们来讲解一下,搜索的timeout机制,底层的原理,画图讲解
GET /_search
{
"took": 6,
"timed_out": false,
"_shards": {
"total": 6,
"successful": 6,
"failed": 0
},
"hits": {
"total": 10,
"max_score": 1,
"hits": [
{
"_index": ".kibana",
"_type": "config",
"_id": "5.2.0",
"_score": 1,
"_source": {
"buildNum": 14695
}
}
]
}
}
took:整个搜索请求花费了多少毫秒
hits.total:本次搜索,返回了几条结果
hits.max_score:本次搜索的所有结果中,最大的相关度分数是多少,每一条document对于search的相关度,越相关,_score分数越大,排位越靠前
hits.hits:默认查询前10条数据,完整数据,_score降序排序
shards:shards fail的条件(primary和replica全部挂掉),不影响其他shard。默认情况下来说,一个搜索请求,会打到一个index的所有primary shard上去,当然了,每个primary shard都可能会有一个或多个replic shard,所以请求也可以到primary shard的其中一个replica shard上去。
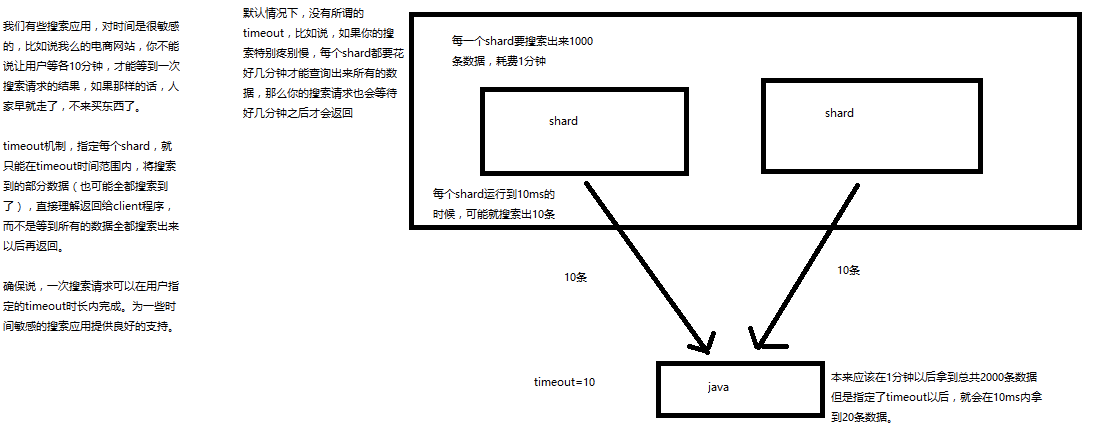
timeout:默认无timeout,latency平衡completeness,手动指定timeout,timeout查询执行机制
timeout机制:制定每个shard 就能在timout时间范围内将搜索到的部分数据(也可能全部搜索大搜了),直接返回给clinet程序,而不是等到所有的数据全都搜索到再返回
timeout=10ms,timeout=1s,timeout=1m
GET /_search?timeout=10m
第三十五讲!
初识搜索引擎 multi-index&multi-type搜索模式解析以及搜索原理初步图解
课程大纲
1、multi-index和multi-type搜索模式
告诉你如何一次性搜索多个index和多个type下的数据
/_search:所有索引,所有type下的所有数据都搜索出来
/index1/_search:指定一个index,搜索其下所有type的数据
/index1,index2/_search:同时搜索两个index下的数据
/*1,*2/_search:按照通配符去匹配多个索引
/index1/type1/_search:搜索一个index下指定的type的数据
/index1/type1,type2/_search:可以搜索一个index下多个type的数据
/index1,index2/type1,type2/_search:搜索多个index下的多个type的数据
/_all/type1,type2/_search:_all,可以代表搜索所有index下的指定type的数据
GET test_inde*/_search
2、初步图解一下简单的搜索原理
搜索原理初步图解
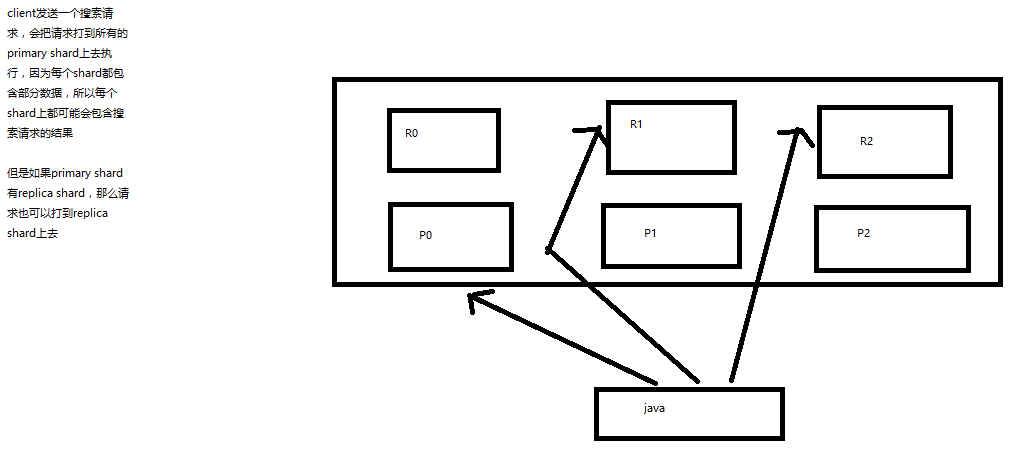
第三十六讲!
课程大纲
1、讲解如何使用es进行分页搜索的语法
size,from
GET /_search?size=10
GET /_search?size=10&from=0
GET /_search?size=10&from=20
分页的上机实验
GET /test_index/test_type/_search
"hits": {
"total": 9,
"max_score": 1,
我们假设将这9条数据分成3页,每一页是3条数据,来实验一下这个分页搜索的效果
GET /test_index/test_type/_search?from=0&size=3

{
"took": 2,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 9,
"max_score": 1,
"hits": [
{
"_index": "test_index",
"_type": "test_type",
"_id": "8",
"_score": 1,
"_source": {
"test_field": "test client 2"
}
},
{
"_index": "test_index",
"_type": "test_type",
"_id": "6",
"_score": 1,
"_source": {
"test_field": "tes test"
}
},
{
"_index": "test_index",
"_type": "test_type",
"_id": "4",
"_score": 1,
"_source": {
"test_field": "test4"
}
}
]
}
}
第一页:id=8,6,4
GET /test_index/test_type/_search?from=3&size=3
第二页:id=2,自动生成,7
GET /test_index/test_type/_search?from=6&size=3
第三页:id=1,11,3
2、什么是deep paging问题?为什么会产生这个问题,它的底层原理是什么?
deep paging性能问题,以及原理深度图解揭秘,很高级的知识点
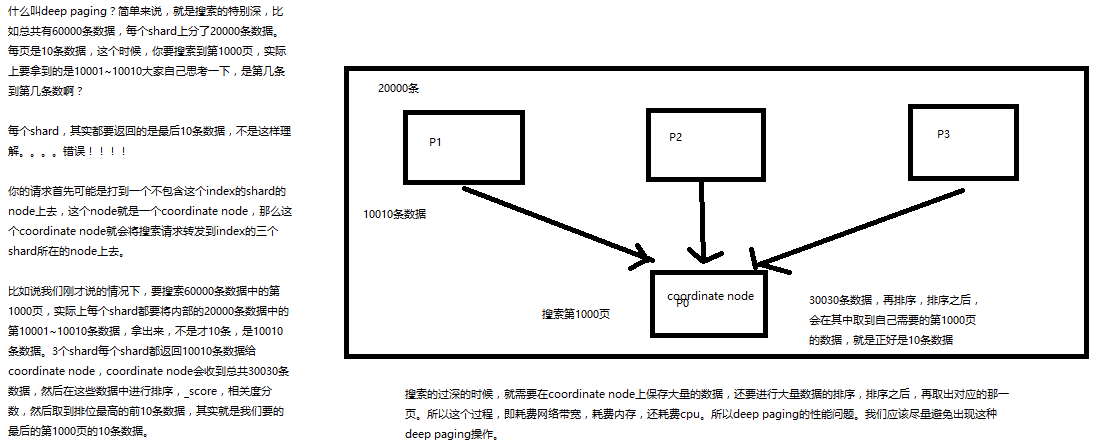
第三十七讲!
课程大纲
1、query string基础语法
将参数拼接到url上面
GET /test_index/test_type/_search?q=test_field:test
GET /test_index/test_type/_search?q=+test_field:test
GET /test_index/test_type/_search?q=-test_field:test
+:必须包含才能搜索出来 和没有符号基本一样
-:必须不包含才能搜索到
一个是掌握q=field:search content的语法,还有一个是掌握+和-的含义
2、_all metadata的原理和作用
GET /test_index/test_type/_search?q=test (包含test的都搜出来了)
直接可以搜索所有的field,任意一个field包含指定的关键字就可以搜索出来。我们在进行中搜索的时候,难道是对document中的每一个field都进行一次搜索吗?不是的
es中的_all元数据,在建立索引的时候,我们插入一条document,它里面包含了多个field,此时,es会自动将多个field的值,全部用字符串的方式串联起来,变成一个长的字符串,作为_all field的值,同时建立索引
后面如果在搜索的时候,没有对某个field指定搜索,就默认搜索_all field,其中是包含了所有field的值的
举个例子
{
"name": "jack",
"age": 26,
"email": "jack@sina.com",
"address": "guamgzhou"
}
"jack 26 jack@sina.com guangzhou",作为这一条document的_all field的值,同时进行分词后建立对应的倒排索引
生产环境不使用
第三十八讲!mapping是啥
课程大纲
插入几条数据,让es自动为我们建立一个索引
PUT /website/article/1
{
"post_date": "2017-01-01",
"title": "my first article",
"content": "this is my first article in this website",
"author_id": 11400
}
PUT /website/article/2
{
"post_date": "2017-01-02",
"title": "my second article",
"content": "this is my second article in this website",
"author_id": 11400
}
PUT /website/article/3
{
"post_date": "2017-01-03",
"title": "my third article",
"content": "this is my third article in this website",
"author_id": 11400
}
尝试各种搜索
GET /website/article/_search?q=2017 3条结果
GET /website/article/_search?q=2017-01-01 3条结果
GET /website/article/_search?q=post_date:2017-01-01 1条结果
GET /website/article/_search?q=post_date:2017 1条结果
查看es自动建立的mapping,带出什么是mapping的知识点
自动或手动为index中的type建立的一种数据结构和相关配置,简称为mapping
dynamic mapping,自动为我们建立index,创建type,以及type对应的mapping,mapping中包含了每个field对应的数据类型,以及如何分词等设置
我们当然,后面会讲解,也可以手动在创建数据之前,先创建index和type,以及type对应的mapping
GET /website/_mapping/article
{
"website": {
"mappings": {
"article": {
"properties": {
"author_id": {
"type": "long"
},
"content": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"post_date": {
"type": "date"
},
"title": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
}
}
}
搜索结果为什么不一致,因为es自动建立mapping的时候,设置了不同的field不同的data type。不同的data type的分词、搜索等行为是不一样的。所以出现了_all field和post_date field的搜索表现完全不一样。
第三十九讲!初识搜索引擎_精确匹配与全文搜索的对比分析
课程大纲
1、exact value
2017-01-01,exact value,搜索的时候,必须输入2017-01-01,才能搜索出来
如果你输入一个01,是搜索不出来的
必须和值完全一样才能搜索到
2、full text
(1)缩写 vs. 全称:cn vs. china
(2)格式转化:like liked likes
(3)大小写:Tom vs tom
(4)同义词:like vs love
2017-01-01,2017 01 01,搜索2017,或者01,都可以搜索出来
china,搜索cn,也可以将china搜索出来
likes,搜索like,也可以将likes搜索出来
Tom,搜索tom,也可以将Tom搜索出来
like,搜索love,同义词,也可以将like搜索出来
就不是说单纯的只是匹配完整的一个值,而是可以对值进行拆分词语后(分词)进行匹配,也可以通过缩写、时态、大小写、同义词等进行匹配
第四十讲!倒排索引核心原理
课程大纲
doc1:I really liked my small dogs, and I think my mom also liked them.
doc2:He never liked any dogs, so I hope that my mom will not expect me to liked him.
分词,初步的倒排索引的建立
word doc1 doc2

演示了一下倒排索引最简单的建立的一个过程
搜索
mother like little dog,不可能有任何结果
mother
like
little
dog
这个是不是我们想要的搜索结果???绝对不是,因为在我们看来,mother和mom有区别吗?同义词,都是妈妈的意思。like和liked有区别吗?没有,都是喜欢的意思,只不过一个是现在时,一个是过去时。little和small有区别吗?同义词,都是小小的。dog和dogs有区别吗?狗,只不过一个是单数,一个是复数。
normalization,建立倒排索引的时候,会执行一个操作,也就是说对拆分出的各个单词进行相应的处理,以提升后面搜索的时候能够搜索到相关联的文档的概率
时态的转换,单复数的转换,同义词的转换,大小写的转换
mom —> mother
liked —> like
small —> little
dogs —> dog
重新建立倒排索引,加入normalization,再次用mother liked little dog搜索,就可以搜索到了

mother like little dog,分词,normalization
mother --> mom
like --> like
little --> little
dog --> dog
doc1和doc2都会搜索出来
doc1:I really liked my small dogs, and I think my mom also liked them.
doc2:He never liked any dogs, so I hope that my mom will not expect me to liked him.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号