
Controller机制
Controller机制
1 前言
Controller 是从Kafka集群中选取一个的broker,负责管理topic分区和副本的状态的变化,以及执行重分配分区之类的管理任务。

第一个启动的broker会成为一个controller,它会在Zookeeper上创建一个临时节点(ephemeral):/controller。其他后启动的broker也尝试去创建这样一个临时节点,但会报错,此时这些broker会在该zookeeper的/controller节点上创建一个监控(Watch),这样当该节点状态发生变化(比如:被删除)时,这些broker就会得到通知。此时,这些broker就可以在得到通知时,继续创建该节点。保证该集群一直都有一个controller节点。
当controller所在的broker节点宕机或断开和Zookeeper的连接,它在Zookeeper上创建的临时节点就会被自动删除。其他在该节点上都安装了监控的broker节点都会得到通知,此时,这些broker都会尝试去创建这样一个临时的/controller节点,但它们当中只有一个broker(最先创建的那个)能够创建成功,其他的broker会报错:node already exists,接收到该错误的broker节点会再次在该临时节点上安装一个watch来监控该节点状态的变化。每次当一个broker被选举时,将会赋予一个更大的数字(通过zookeeper的条件递增实现),这样其他节点就知道controller目前的数字。
当一个broker宕机而不在当前Kafka集群中时,controller将会得到通知(通过监控zookeeper的路径实现),若有些topic的主分区恰好在该broker上,此时controller将重新选择这些主分区。controller将会检查所有没有leader的分区,并决定新的leader是谁(简单的方法是:选择该分区的下一个副本分区),并给所有的broker发送请求。
每个分区的新leader指导,它将接收来自客户端的生产者和消费者的请求。同时follower也指导,应该从这个新的leader开始复制消息。
当一个新的broker节点加入集群时,controller将会检查,在该broker上是否存在分区副本。若存在,controller通知新的和存在的broker这个变化,该broker开始从leader处复制消息。
下面将从以下几个介绍controller的相关原理:
2 controller启动
2.1选举controller
在KafkaServer.startup()中,KafkaController对象被构建,在启动KafkaApis、replicaManager后,KafkaController.startup()被调用。

startup()函数非常简单,这里直接粘代码:
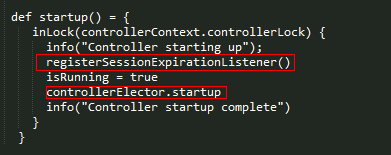
除去日志以及标识状态的isRunning赋值,值得看的代码就两句。其中registerSessionExpirationListener()用于在zookeeper会话失效后重连时取消注册在zookeeper上的各种Listener,而controllerElector.startup则启动了选举,这些都将发生在ZookeeperLeaderElector类中。

Kafka集群中每个Broker都会调用startup()函数,但是一个集群只有一个Broker能够成为Controller。那么,谁将成为这个controller呢?
KafkaController选举是直接通过zookeeper实现的,就是在zookeeper创建临时目录/controller/并在目录下存放当前brokerId。如果在zookeeper下创建路径没有抛出ZkNodeExistsException异常,则当前broker成功晋级为Controller。除了调用elect外,controllerElector.startup还会在/controller/路径上注册Listener,监听dataChange事件和dataDelete事件,当/controller/下数据发生变化时,表示Controller发生了变化;而因为/controller/下的数据为临时数据,当Controller发生failover时,数据会被删除,触发dataDelete事件,这时就需要重新选举新一任Controller。
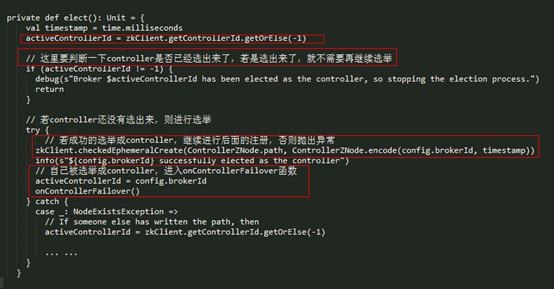
2.1 注册listener
成为KafkaController之后很重要的一件事,就是在zookeeper各个关键路径上添加Listener,所以这里很有必要先总结一下跟controller相关的路径([ ]表示其中的值是随实际情况变化的):
- l /controller/{“brokerid”:”1”}: 决定谁才是这一届Controller,路径下存放当前Controller的brokerId,这些信息以临时数据的形式存放,在会话失效时会被删除。类LeaderChangeListener监听该路径下的dataChange和dataDelete事件。
- l /brokers/topics:子目录为所有topic列表。类TopicChangeListener监听子目录列表变化,如果有新增topic,则调用onNewTopicCreation创建新的topic。
- l /brokers/topics/[topic]/:存放的是topic下各个分区的AR,目录下存放的格式为{“partitions”:{“partitionId1”:[broker1,broker2], …}}。类AddPartitionsListener监听路径下的数据变化,在有新增partition时调用Controller.onNewPartitionCreate,即创建新的partition。
- l /brokers/topics/[topic]/partitions/[partitionId]/state/:存放的是各个分区的leaderAndIsr信息,即各个分区当前的leaderId,以及ISR。类ReassignedPartitionsIsrChangeListener监听该路径下的数据变化,在重新分配replica到partition时,需要等待新的replica追赶上leader后才能执行后续操作。
- l /brokers/ids/[brokerId]/brokerInfoString:存放broker信息,brokerInfoString包括broker的IP,端口等信息;BrokerChangeListener监听/brokers/ids/下子目录变化,从而通知Controller broker的上下线消息。brokerInfoString是Controller判断的broker是否活着的条件之一,controllerContext中的liveBrokers需要相应路径下能够获取到brokerInfo。
- l /admin/reassign_partitions:指导重新分配AR的路径,通过命令修改AR时会写入到这个路径下。类PartitionsReassignedListener监听该路径下的内容变化,调用initiateReassignReplicasForTopicPartition,执行重新分配AR操作。
- l /admin/preferred_replica_election:分区需要重新选举第一个replica作为leader,即所谓的preferred replica。类PreferredReplicaElectionListener监听该路径,并对路径下的partitions执行重新选举preferred replica作为leader。
名词解释
- l AR 当前已分配的副本列表
- l RAR 重分配过的副本列表
- l ORA 重分配之前的副本列表
- l 分区Leader 给定分区负责客户端读写的结点
- l ISR “in-sync” replicas,能够与Leader保持同步的副本集合(Leader也在ISR中)
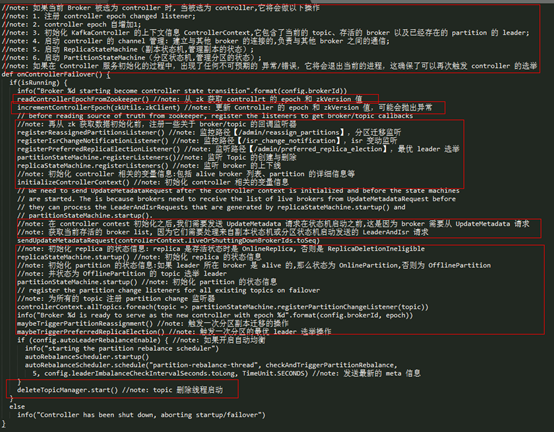
成为KafkaController以后,会执行什么操作呢?
- 升级Controller Epoch,并将新的epoch写入到zookeeper中;新的epoch标识着下一个时代的leader,向其他broker发送命令时会校验epoch;
- 监听zookeeper路径/admin/reassign_partitions;
- 监听zookeeper路径/admin/preferred_replica_election;
- 注册partition状态机中的监听器,监听路径/brokers/topics的子目录变化,随时准备创建topic;
- 注册replica状态机中的监听器,监听路径/brokers/ids/的子目录,以便在新的broker加入时能够感知到;
- 初始化ControllerContext,主要是从zookeeper中读取数据初始化context中的变量,诸如 liveBrokers,allTopics,AR,LeadershipInfo等;
- 初始化ReplicaStateMachine,将所有在活跃broker上的replica的状态变为OnlineReplica;
- 初始化PartitionStateMachine,将所有leader在活跃broker上的partition的状态设置为Onlinepartition;其他的partition状态为OfflinePartition。Partition是否为Online的标识就是leader是否活着;之后还会触发OfflinePartition 和 NewPartition向OnlinePartition转变,因为OfflinePartition和NewPartition可能是选举leader不成功,所以没有成为OnlinePartition,在环境变化后需要重新触发;
- 在所有的topic的zookeeper路径/brokers/topics/[topic]/上添加AddPartitionsListener,监听partition变化;
- KafkaController 启动后,触发一次最优 leader 选举操作,如果需要的情况下;
- KafkaController 启动后,如果开启了自动 leader 均衡,启动自动 leader 均衡线程,它会根据配置的信息定期运行。
完成对各个zookeeper路径的监听后,zookeeper内容的变化驱动Controller进行各种操作,处理如新建topic,删除topic,broker失效,broker恢复等事件。
2.3 Controller Failover
前面startup()中registerSessionExpirationListener()会注册会话监听器,在zookeeper会话过期后又重连成功时调用onControllerResignation(),并重新执行选举操作。 此外,当Controller会话失效时,会删除/controller/路径下创建的临时数据。与此同时,其他broker上的ZookeeperLeaderElector类中的LeaderChangeListener感知到数据删除后会重新执行选举。
onControllerResignation()是Controller转变为普通broker时执行的操作,就是将前面注册的各个Listener取消注册,不再关注zookeeper变化
2.4 initializeControllerContext 初始化 Controller 上下文信息
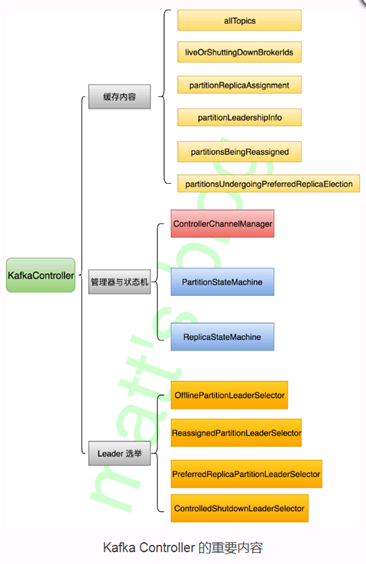
在 KafkaController 中
l 有两个状态机:分区状态机和副本状态机;
l 一个管理器:Channel 管理器,负责管理所有的 Broker 通信;
l 相关缓存:Partition 信息、Topic 信息、broker id 信息等;
l 四种 leader 选举机制:分别是用 leader offline、broker 掉线、partition reassign、最优 leader 选举时触发;
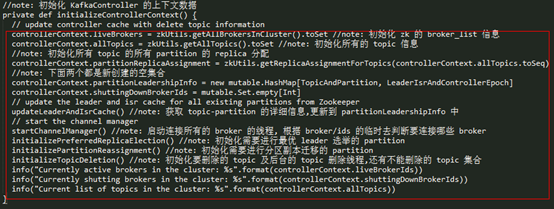
在 initializeControllerContext() 初始化 KafkaController 上下文信息的方法中,主要做了以下事情:
- l 从 zk 获取所有 alive broker 列表,记录到 liveBrokers;
- l 从 zk 获取所有的 topic 列表,记录到 allTopic 中;
- l 从 zk 获取所有 Partition 的 replica 信息,更新到 partitionReplicaAssignment 中;
- l 从 zk 获取所有 Partition 的 LeaderAndIsr 信息,更新到 partitionLeadershipInfo 中;
- l 调用 startChannelManager() 启动 Controller 的 Channel Manager;
- l 通过 initializePreferredReplicaElection() 初始化需要最优 leader 选举的 Partition 列表,记录到 partitionsUndergoingPreferredReplicaElection 中;
- l 通过 initializePartitionReassignment() 方法初始化需要进行副本迁移的 Partition 列表,记录到 partitionsBeingReassigned 中;
- l 通过 initializeTopicDeletion() 方法初始化需要删除的 topic 列表及 TopicDeletionManager 对象;
最优 leader 选举:就是默认选择 Replica 分配中第一个 replica 作为 leader,为什么叫做最优 leader 选举呢?因为 Kafka 在给每个 Partition 分配副本时,它会保证分区的主副本会均匀分布在所有的 broker 上,这样的话只要保证第一个 replica 被选举为 leader,读写流量就会均匀分布在所有的 Broker 上,当然这是有一个前提的,那就是每个 Partition 的读写流量相差不多,但是在实际的生产环境,这是不太可能的,所以一般情况下,大集群是不建议开自动 leader 均衡的,可以通过额外的算法计算、手动去触发最优 leader 选举。
2.5 Controller Channel Manager
initializeControllerContext() 方法会通过 startChannelManager() 方法初始化 ControllerChannelManager 对象,如下所示:

ControllerChannelManager在初始化时,会为集群中的每个节点初始化一个 ControllerBrokerStateInfo 对象,该对象包含四个部分:
- l NetworkClient:网络连接对象;
- l Node:节点信息;
- l BlockingQueue:请求队列;
- l RequestSendThread:请求的发送线程。
其具体实现如下所示:

清楚了上面的逻辑,再来看 KafkaController 部分是如何向 Broker 发送请求的

KafkaController 实际上是调用的 ControllerChannelManager 的 sendRequest() 方法向 Broker 发送请求信息,其实现如下所示:
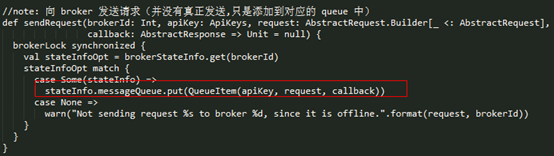
它实际上只是把对应的请求添加到该 Broker 对应的 MessageQueue 中,并没有真正的去发送请求,请求的的发送是在 每台 Broker 对应的 RequestSendThread 中处理的。
2.6 Controller 原生的四种 leader 选举机制
四种 leader 选举实现类及对应触发条件如下所示
|
实现 |
触发条件 |
|
OfflinePartitionLeaderSelector |
leader 掉线时触发 |
|
ReassignedPartitionLeaderSelector |
分区的副本重新分配数据同步完成后触发的 |
|
PreferredReplicaPartitionLeaderSelector |
最优 leader 选举,手动触发或自动 leader 均衡调度时触发 |
|
ControlledShutdownLeaderSelector |
broker 发送 ShutDown 请求主动关闭服务时触发 |
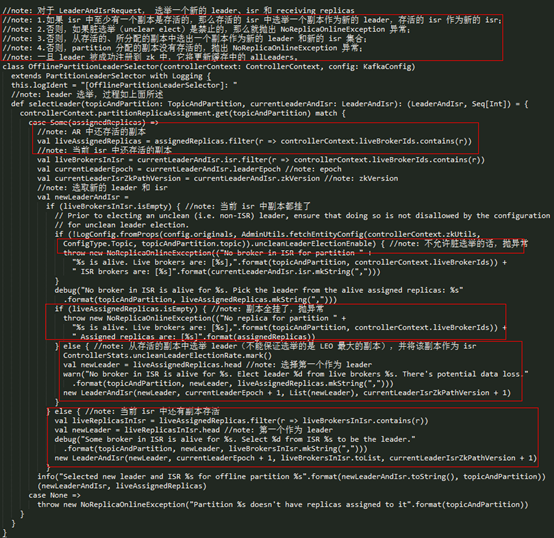
OfflinePartitionLeaderSelector
选举的逻辑是:
- l 如果 isr 中至少有一个副本是存活的,那么从该 Partition 存活的 isr 中选举第一个副本作为新的 leader,存活的 isr 作为新的 isr;
- l 否则,如果脏选举(unclear elect)是禁止的,那么就抛出 NoReplicaOnlineException 异常;
- l 否则,即允许脏选举的情况下,从存活的、所分配的副本(不在 isr 中的副本)中选出一个副本作为新的 leader 和新的 isr 集合;
- l 否则,即是 Partition 分配的副本没有存活的,抛出 NoReplicaOnlineException 异常;
一旦 leader 被成功注册到 zk 中,它将会更新到 KafkaController 缓存中的 allLeaders 中。
ReassignedPartitionLeaderSelector
ReassignedPartitionLeaderSelector 是在 Partition 副本迁移后,副本同步完成(RAR 都处在 isr 中,RAR 指的是该 Partition 新分配的副本)后触发的,其 leader 选举逻辑如下:
- l leader 选择存活的 RAR 中的第一个副本,此时 RAR 都在 isr 中了;
- l new isr 是所有存活的 RAR 副本列表;

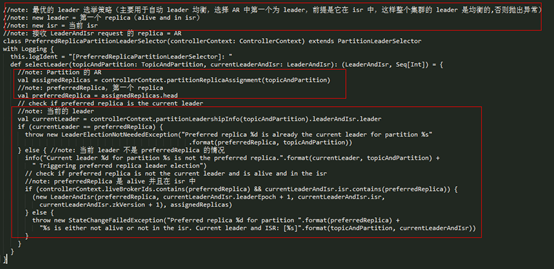
PreferredReplicaPartitionLeaderSelector
PreferredReplicaPartitionLeaderSelector 是最优 leader 选举,选择 AR(assign replica)中的第一个副本作为 leader,前提是该 replica 在是存活的、并且在 isr 中,否则会抛出 StateChangeFailedException 的异常。
ControlledShutdownLeaderSelector
ControlledShutdownLeaderSelector 是在处理 broker 下线时调用的 leader 选举方法,它会选举 isr 中第一个没有正在关闭的 replica 作为 leader,否则抛出 StateChangeFailedException 异常。

参考资料:
https://blog.csdn.net/zg_hover/article/details/81672997
https://blog.csdn.net/c395318621/article/details/52463854
https://github.com/wangzzu/awesome/issues/7

