


GroupCoordinator机制
GroupCoordinator机制
1 介绍:
Kafka 的 Server 端主要有三块内容:GroupCoordinator、Controller 和 ReplicaManager,其中,GroupCoordinator 的内容是与 Consumer 端紧密结合在一起的,简单来说就是,GroupCoordinator 是负责进行 consumer 的 group 成员的rebalance与 offset 管理。GroupCoordinator 处理的 client 端请求类型可以看出来,它处理的请求类型主要有以下几种:
- l ApiKeys.OFFSET_COMMIT;
- l ApiKeys.OFFSET_FETCH;
- l ApiKeys.JOIN_GROUP;
- l ApiKeys.LEAVE_GROUP;
- l ApiKeys.SYNC_GROUP;
- l ApiKeys.DESCRIBE_GROUPS;
- l ApiKeys.LIST_GROUPS;
- l ApiKeys.HEARTBEAT;
而 Kafka Server 端要处理的请求总共有21 种,其中有 8 种是由 GroupCoordinator 来完成的。
2 rebalance机制
我们知道kafka保证同一消费组中的每个consumer能够消费一个或者多个特定的partition数据,一个partition的数据只能被一个consumer消费;因为每个partition里的消息是有序的,这样可以保证partition中的数据被同一个消费者有序消费;同时consumer只需要和自己消费的partition的broker通信就可以,减少开销。
在如下条件下,partition要在consumer中重新分配:
- l 条件1:有新的consumer加入
- l 条件2:旧的consumer挂了
- l 条件3:coordinator挂了,集群选举出新的coordinator
- l 条件4:topic的partition新加
- l 条件5:consumer调用unsubscrible(),取消topic的订阅
在kafka中消费者的分区分配策略默认有两种:range和RoundRobin。
给定一个topic,有4个partition: p0, p1, p2, p3, 一个group有3个consumer: c0, c1, c2。那么,如果按范围分配策略,分配结果是:
c0: p0, c1: p1, c2: p2, p3
如果按轮询分配策略:
c0: p1, p3, c1: p1, c2: p2
2.1基于zk的rebalance
在kafka0.9版本之前,consumer的rebalance是通过在zookeeper上注册watch完成的。每个consumer创建的时候,会在在Zookeeper上的路径为/consumers/[consumer group]/ids/[consumer id]下将自己的id注册到消费组下;然后在/consumers/[consumer group]/ids 和/brokers/ids下注册watch;最后强制自己在消费组启动rebalance。
这种做法很容易带来zk的羊群效应,任何Broker或者Consumer的增减都会触发所有的Consumer的Rebalance,造成集群内大量的调整;同时由于每个consumer单独通过zookeeper判断Broker和consumer宕机,由于zk的脑裂特性,同一时刻不同consumer通过zk看到的表现可能是不一样,这就可能会造成很多不正确的rebalance尝试;除此之外,由于consumer彼此独立,每个consumer都不知道其他consumer是否rebalance成功,可能会导致consumer group消费不正确。
2.2 Coordinator
基于zk的rebalance存在不可避免的羊群效应和脑裂问题,如何不用zk来协调,而是将失败探测和Rebalance的逻辑放到一个高可用的中心,那么上述问题就能得以解决;因此kafka0.9.*的版本重新设计了consumer端,诞生了这样一个高可用中心Coordinator,大大减少了zookeeper负载。
对于每一个Consumer Group,Kafka集群为其从broker集群中选择一个broker作为其coordinator。coordinator主要做两件事:
- 维持group的成员组成。这包括加入新的成员,检测成员的存活性,清除不再存活的成员。
- 协调group成员的行为。
Coordinator有如下几种类型:
- GroupCoordinator:broker端的,每个kafka server都有一个实例,管理部分的consumer group和它们的offset
- WorkerCoordinator:broker端的,管理GroupCoordinator程序,主要管理workers的分配。
- ConsumerCoordinator:consumer端的,和GroupCoordinator通信的媒介。
ConsumerCoordinator是KafkaConsumer的一个成员,只负责与GroupCoordinator通信,所以真正的协调者还是GroupCoordinator。
2.3分区步骤:
Kafka为consumerGroup

步骤1:对于每1个consumer group,Kafka集群为其从broker集群中选择一个broker作为其coordinator。因此,第1步就是找到这个coordinator。

2.4 group 如何选择相应的 GroupCoordinator
要说这个,就必须介绍一下这个 __consumer_offsets topic 了,它是 Kafka 内部使用的一个 topic,专门用来存储 group 消费的情况,默认情况下有50个 partition,每个 partition 默认有三个副本,而具体的一个 group 的消费情况要存储到哪一个 partition 上,是根据 abs(GroupId.hashCode()) % NumPartitions来计算的(其中,NumPartitions 是 __consumer_offsets 的 partition 数,默认是50个)。
对于 consumer group 而言,是根据其 group.id 进行 hash 并计算得到其具对应的 partition 值,该 partition leader 所在 Broker 即为该 Group 所对应的 GroupCoordinator,GroupCoordinator 会存储与该 group 相关的所有的 Meta 信息。
此外,每一个分区,其实是4个offset:
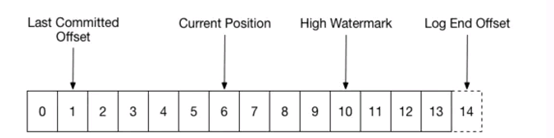
Leo:代表了producer提交的message set的最后一个offset
HW:代表了最大可以供Consumer消费的message set的offset
Current Position:代表了某个Consumer Group消费到的位置
Last Committed Offset:代表了某个Consumer Group Commit的offset。
其中leo,hw都不必说了,他们是存在于recovery-point-offset-checkpoint, replication-checkpoint 两个文件中的它两个都是针对于分区来说的。
Current position 是有Consumer自身知道的。
Last Committed Offset则是记录了Partition在某个Consumer Group的消费情况。
步骤2:找到coordinator之后,发送JoinGroup请求
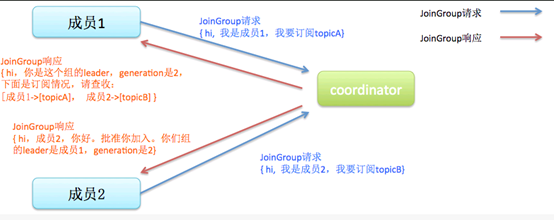

步骤3:JoinGroup返回之后,发送SyncGroup,得到自己所分配到的partition
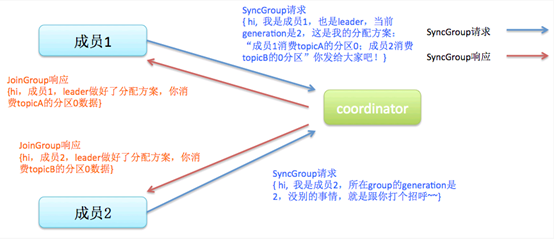

partition的分配策略和分配结果其实是由client决定的,而不是由coordinator决定的。在第2步,所有consumer都往coordinator发送JoinGroup消息之后,coordinator会指定其中一个consumer作为leader,其他consumer作为follower。
然后由这个leader进行partition分配。然后在第3步,leader通过SyncGroup消息,把分配结果发给coordinator,其他consumer也发送SyncGroup消息,获得这个分配结果。
为什么要在consumer中选一个leader出来,进行分配,而不是由coordinator直接分配呢?关于这个, Kafka的官方文档有详细的分析。其中一个重要原因是为了灵活性:如果让server分配,一旦需要新的分配策略,server集群要重新部署,这对于已经在线上运行的集群来说,代价是很大的;而让client分配,server集群就不需要重新部署了。
Rebalance Generation
它表示了rebalance之后的一届成员,主要是用于保护consumer group,隔离无效offset提交的。比如上一届的consumer成员是无法提交位移到新一届的consumer group中。每次group进行rebalance之后,generation号都会加1,表示group进入到了一个新的版本,如下图所示: Generation 1时group有3个成员,随后成员2退出组,coordinator触发rebalance,consumer group进入Generation 2,之后成员4加入,再次触发rebalance,group进入Generation 3.

2.5 heartbeat的实现原理
前面介绍了rebalance的条件,这些条件主要是通过heartbeat感知,每一个consumer都会定期的往coordinator发送heartbeat消息,一旦coordinator返回了某个特定的error code:ILLEGAL_GENERATION, 就说明之前的group无效了(解散了),要重新进行JoinGroup + SyncGroup操作。
那这个定期发送如何实现呢?一个直观的想法就是开一个后台线程,定时发送heartbeat消息,但维护一个后台线程,很显然会增大实现的复杂性。上面也说了, consumer是单线程程序。在这里是通过DelayedQueue来实现的。
DelayedQueue与HeartBeatTask
其基本思路是把HeartBeatRequest放入一个DelayedQueue中,然后在while循环的poll中,每次从DelayedQueue中把请求拿出来发送出去(只有时间到了,Task才能从Queue中拿出来)。

HeartbeatRequest消息体比较简单,包含group_id(String),group_generation_id(int),member_id(String)三个字段。HeartbeatResponse消息体只包含short类型的error_code。
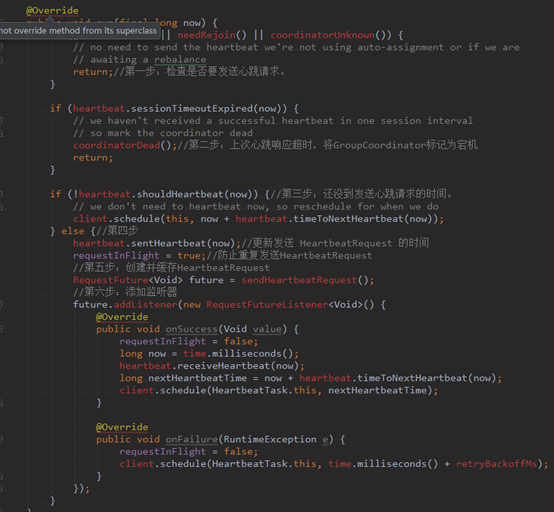
HeartbeatTask是一个实现DelayedTask接口的定时任务,负责定时发送HeartbeatRequest并处理其响应,实现逻辑都在run()方法中实现,HeartbeatTask.run()的具体流程:

(1)首先检查是否需要发送HeartbeatRequest,条件有三个,一个不满足就不能发送心跳:
- GroupCoordinator 已经确定且已连接。
- 不处于正在等待Partition分配结果的状态。
- 之前的HeartbeatRequest请求正常收到响应且没有过期。
如果不符合条件,就不会再执行HeartbeatTask,等待后续调用reset()方法重启HeartbeatTask任务。
(2)调用Heartbeat.sessionTimeoutExpired(now),判断HeartbeatResponse是否超时,如果超时,则认为GroupCoordinator宕机,调用coordinatorDead()清空其unsent集合中对应的请求队列并将这些请求标记为异常后结束,将coordinator字段设置为Null,表示将重新选举GroupCoordinator。同时停止HeartbeatTask的执行。 coordinatorDead()代码:

(3)检测HeartbeatTask是否到期,如果不到期则更新到期时间,将HeartbeatTask对象重新添加到DelayedTaskQueue中,等待其到期后执行;如果已经到期就发送HeartbeatRequest请求。
(4)更新最近一次发送HeartbeatRequest请求的时间,将requestInFlignt设置为true,表示有未响应的HeartbeatRequest请求,防止重复发送。
(5)创建HeartbeatRequest请求,并调用ConsumerNetworkClient.send()方法,将请求放入unsent集合中缓存并返回RequestFuture<Void>。然后ConsumerNetworkClient.poll()会将HeartbeatRequest请求发送给GroupCoordinator。
(6)在RequestFuture<Void>对象上添加RequestFutureListener。
HeartbeatTask.run()具体实现:
sendHeartbeatRequest()
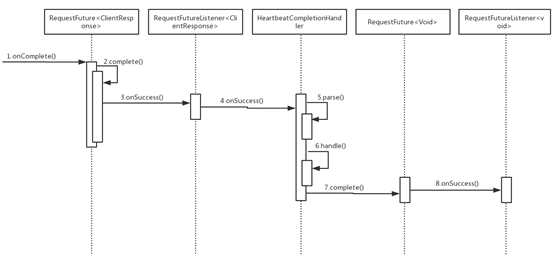
使用HeartbeatCompletionHandler将client.send()方法返回的RequestFuture<ClientResponse>适配成RequestFuture<Void>后返回

使用HeartbeatCompletionHandler中实现的是HeartbeatResponse的核心逻辑:
CoordinatorResponseHandler是一个抽象类,其中有parse()和handle()两个抽象方法,parse()方法对ClientResponse进行解析,得到指定类型的响应;handle()对解析后的响应进行处理。CoordinatorResponseHandler实现了RequestFuture抽象类的onSuccess()方法和onFailure方法
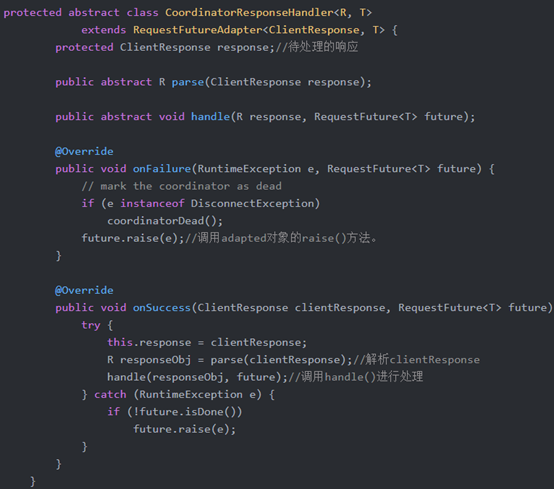
RequestFuture<ClientResponse>和RequestFutureListener<ClientResponse>
实现了配适器的功能。当ClientResponse传递到HeartbeatCompletionHandler时,会通过parse()方法解析成HeartbeatResponse,然后进入handle()方法处理。
在HeartbeatCompletionHandler.handle()方法中,判断HeartbeatResponse中是否包含错误码,如果不包含,则调用RequestFuture<Void>的complete(null)方法,将HeartbeatResponse成功的事件传播下去,否则,根据错误码分类处理,并调用raise()设置对应的异常。如:
错误码是Errors.ILLEGAL_GENERATION,表示HeartbeatRequest中携带的generationId过期,GroupCoordinator已经开始新一轮的Rebalance操作,则将rejoinNeeded设置为true,这样会重新发送JoinGroupRequest请求尝试加入Consumer Group,也会导致HeartbeatTask任务停止。如果错误码是UNKNOWN_MEMBER_ID,表示GroupCoordinator识别不了此Consumer,则清空memberId,尝试重新加入Consumer Group。
分析handle()方法的具体实现代码:
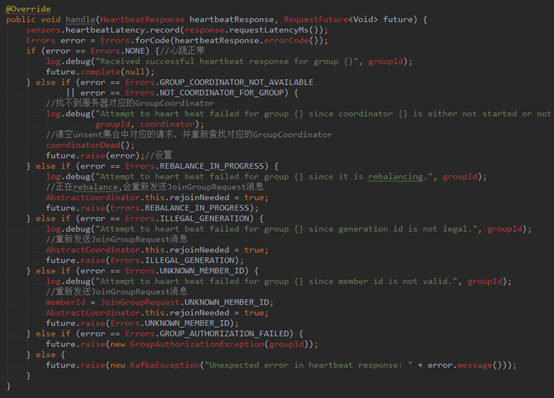
HeartbeatCompletionHandler.handle()方法中会调用RequestFuture<Void>的complete()方法或raise()方法,这两个方法中没有处理逻辑,但是会触发其上的RequestFutureListener<Void>(在HeartbeatTask.run()方法中注册),此监听器会将requestInFlight设置为false,表示所有HeartbeatRequest都已经完成,并将HeartbeatTask重新放入定时任务队列,等待下一次到期执行。
2.6 consumer group状态机
和很多kafka组件一样,group也做了个状态机来表明组状态的流转。coordinator根据这个状态机会对consumer group做不同的处理,如下图所示

下图中的各个状态:
- l Dead:组内已经没有任何成员的最终状态,组的元数据也已经被coordinator移除了。这种状态响应各种请求都是一个response: UNKNOWN_MEMBER_ID
- l Empty:组内无成员,但是位移信息还没有过期。这种状态只能响应JoinGroup请求
- l PreparingRebalance:组准备开启新的rebalance,等待成员加入
- l AwaitingSync:正在等待leader consumer将分配方案传给各个成员
- l Stable:rebalance完成!可以开始消费了
新成员加入:
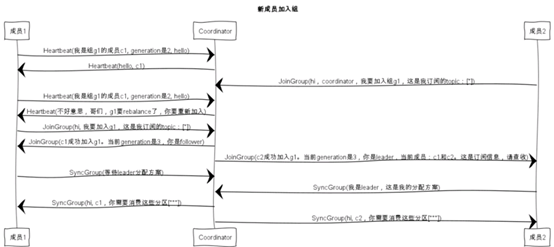
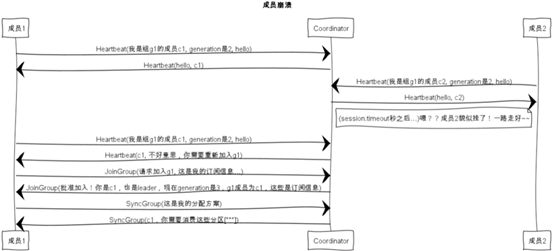
成员崩溃:
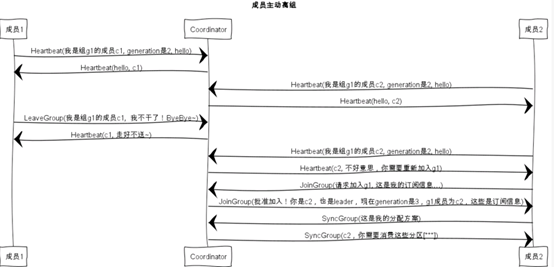
成员主动离组:
提交offset:

3 offset管理
老版本的位移是提交到zookeeper中的,目录结构是:/consumers/<group.id>/offsets/<topic>/<partitionId>,但是zookeeper其实并不适合进行大批量的读写操作,尤其是写操作。

因此kafka提供了另一种解决方案:增加__consumeroffsets topic,将offset信息写入这个topic,摆脱对zookeeper的依赖(指保存offset这件事情)。__consumer_offsets中的消息保存了每个consumer group某一时刻提交的offset信息。依然以上图中的consumer group为例,格式大概如下:


__consumers_offsets topic配置了compact策略,使得它总是能够保存最新的位移信息,既控制了该topic总体的日志容量,也能实现保存最新offset的目的。

3.1 offset的管理过程
offset提交消息会根据消费组的key(消费组名称)进行分区. 对于一个给定的消费组,它的所有消息都会发送到唯一的broker(即Coordinator)
Coordinator上负责管理offset的组件是Offset
manager。负责存储,抓取,和维护消费者的offsets. 每个broker都有一个offset manager实例. 有两种具体的实现:
ZookeeperOffsetManager: 调用zookeeper来存储和接收offset(老版本的位移管理)。
DefaultOffsetManager: 提供消费者offsets内置的offset管理。
通过在config/server.properties中的offset.storage参数选择。
DefaultOffsetManager
除了将offset作为logs保存到磁盘上,DefaultOffsetManager维护了一张能快速服务于offset抓取请求的consumer offsets表。这个表作为缓存,包含的含仅仅是”offsets
topic”的partitions中属于leader
partition对应的条目(存储的是offset)。
对于DefaultOffsetManager还有两个其他属性:
“offsets.topic.replication.factor和”offsets.topic.num.partitions”,默认值都是1。这两个属性会用来自动地创建”offsets topic”。
offset manager接口的概要:

3.2 Offset Commit提交过程:
消费端
一条offset提交消息会作为生产请求.当消费者启动时,会为”offsets topic”创建一个消费者。下面是内置的生产者的一些属性:
可以使用异步.但是使用同步可以避免延迟的生产请求(因为是批量消息),并且我们需要立即知道offset消息是否被broker成功接收
|request.required.acks|-1|确保所有的replicas和leader是同步的,并且能看到所有的offset消息
|key.serializer.class|StringEncoder|key和payload都是strings
注意我们没有对提交的offset消息进行压缩,因为每条消息本身大小是很小的,如果压缩了反而适得其反.
目前key和offset的值通过纯文本方式传递. 我们可以转换为更加紧凑的二进制协议,而不是把Long类型的offset和Int类型的partition作为字符串. 当然在不断演进时还要考虑版本和格式协议.
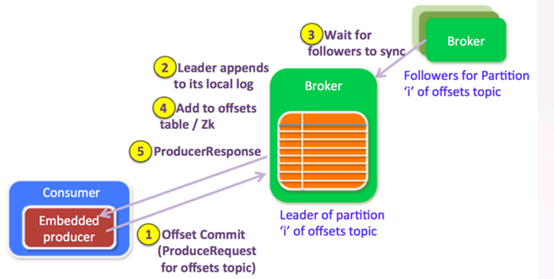
broker端
broker把接收到的offset提交信息当做一个正常的生产请求,对offset请求的处理和正常的生产者请求处理方式是一样的.一旦将数据追加到leader的本地日志中,并且所有的replicas都赶上leader.leader检查生产请求是”offsets topic”,(因为broker端的处理逻辑针对offset请求和普通生产请求是一样的,如果是offset请求,还需要有不同的处理分支)它就会要求offset manager添加这个offset(对于延迟的生产请求,更新操作会在延迟的生产请求被完成的时候).
因为设置了acks=-1,只有当这些offsets成功地复制到ISR中的所有brokers,才会被提交给offset manager.
3.3 Offset Fetch获取过程:
消费端
消费者启动时,会首先创建到任意一个存活的brokers的通道.因此消费者会发送它所有”OffsetFetchRequest”到这个随机选中的broker.。如果出现错误,这个通道就会被关闭,并重新创建一个随机的通道。
broker端
一个Offset抓取请求包含了多个topic-partitions. 接收请求的broker可能有也可能没有请求的partitions的offset信息。因此接收请求的brokers也会和其他broker通信. 一个通道连接池会用来转发请求给partition的leader broker.
下面是一个broker在接收到一个offset抓取请求后的步骤:
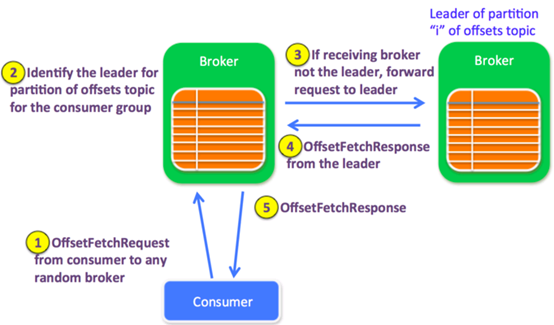
接收请求的broker首先决定”offset topic”的哪个partition负责这个请求从broker的leader cache中找出对应partition的leader(会在controller的每次metadata更新请求中更新缓存)
如果接收请求的broker就是leader,它会从自己的offset manager中读取出offset,并添加到响应中如果offset不存在,返回UnknownTopicOrPartitionCode如果broker正在加载offsets table,返回OffsetLoadingCode.消费者受到这个状态码会在之后重试。如果接收请求的broker不是指定topic-partition的leader,它会将OffsetFetchRequest转发给这个partition的当前leader,如果”offsets topic”这个时候不存在,它会尝试自动创建,在创建成果后,会返回offset=-1
4 参考资料:
https://blog.csdn.net/chunlongyu/article/details/52791874
http://www.clouder.top/2018/03/12/kafka-consumer1/
https://segmentfault.com/a/1190000011441747
http://matt33.com/2018/01/28/server-group-coordinator/
https://www.jianshu.com/p/7e99830b1236
https://www.jianshu.com/p/5aa8776868bb
https://blog.csdn.net/qq_26222859/article/details/55101973

