
Producer机制
在使用kafka时,client是最先接触的部分,消息也是从producer产生,故先从producer开始介绍
在分析 Producer 发送模型之前,先通过一个栗子看一下用户是如何使用 Producer 向 Kafka 写数据的。
使用示例
下面是一个关于 Producer 最简单的应用示例。
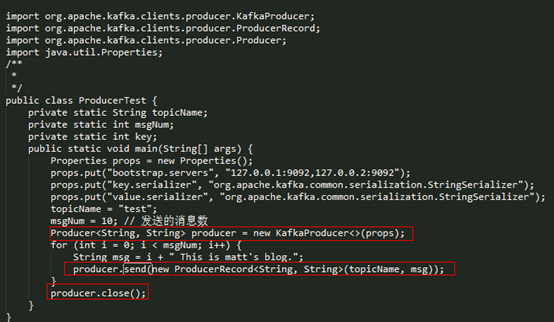
从上面的代码可以看出 Kafka 为用户提供了非常简单的 API,在使用时,只需要如下两步:
l 初始化 KafkaProducer 实例;
l 调用 send 接口发送数据。(也支持异步发送,在传入的参数中),如

Kafka producer发送流程
Kafka的发送流程可以简单如下图所示:
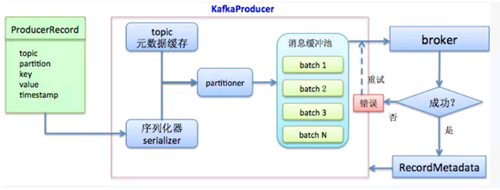
用户是直接使用 producer.send() 发送的数据,先看一下 send() 接口的实现

数据发送的最终实现还是调用了 Producer 的 doSend() 接口。
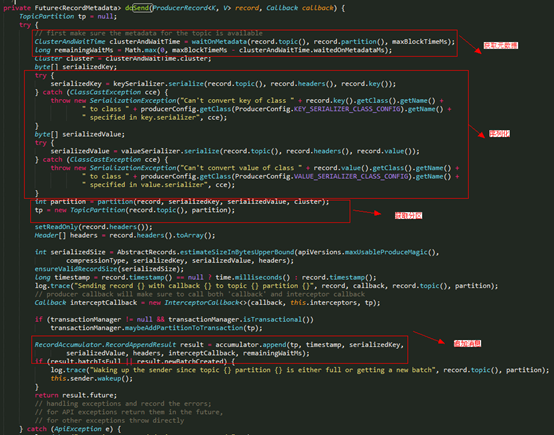
在 dosend() 方法的实现上,一条 Record 数据的发送前,首先需获取集群的信息和加载元数据的时间:
确认数据要发送到的 topic 的 metadata 是可用的(如果该 partition 的 leader 存在则是可用的,如果开启权限时,client 有相应的权限),如果没有 topic 的 metadata 信息,就需要获取相应的 metadata;
内部详细的发送流程如下:
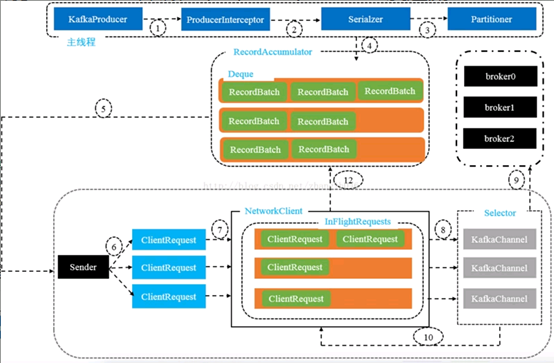
各个步骤的含义
1. ProducerIntercptor对消息进行拦截
Producer拦截器(interceptor)是在Kafka 0.10版本被引入的,主要用于实现clients端的定制化控制逻辑。对于producer而言,interceptor使得用户在消息发送前以及producer回调逻辑前有机会对消息做一些定制化需求,比如修改消息等。同时,producer允许用户指定多个interceptor按序作用于同一条消息从而形成一个拦截链(interceptor chain)。Serialzer对key和value进行序列化,具体可参考如下链接的讲解。
http://www.cnblogs.com/frankdeng/p/9425000.html
2. Serialzer对key和value进行序列化
Producer 端对 record 的 key 和 value 值进行序列化操作,在 Consumer 端再进行相应的反序列化,Kafka 内部提供的序列化和反序列化算法如下图所示:
当然我们也是可以自定义序列化的具体实现,不过一般情况下,Kafka 内部提供的这些方法已经足够使用。
3. Partitioner对消息选择合适的分区
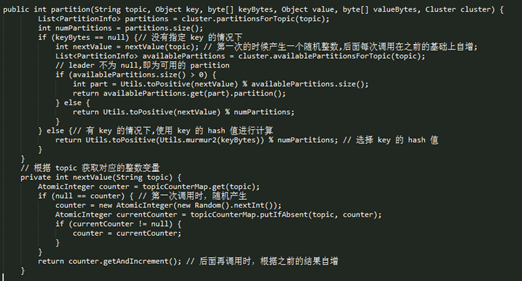
关于 partition 值的计算,分为三种情况:
l 指明 partition 的情况下,直接将指明的值直接作为 partiton 值;
l 没有指明 partition 值但有 key 的情况下,将 key 的 hash 值与 topic 的 partition 数进行取余得到 partition 值;
l 既没有 partition 值又没有 key 值的情况下,第一次调用时随机生成一个整数(后面每次调用在这个整数上自增),将这个值与 topic 可用的 partition 总数取余得到 partition 值,也就是常说的 round-robin 算法。

4.RecordAccumulator收集消息,实现批量发送
Producer 会先将 record 写入到 buffer 中,当达到一个 batch.size 的大小时,再唤起 sender 线程去发送 RecordBatch,这里先详细分析一下 Producer 是如何向 buffer 中写入数据的。
Producer 是通过 RecordAccumulator 实例追加数据,

RecordAccumulator 模型如下图所示,一个重要的变量就是 ConcurrentMap<TopicPartition, Deque<RecordBatch>> batches,每个 TopicPartition 都会对应一个 Deque<RecordBatch>,当添加数据时,会向其 topic-partition 对应的这个 queue 最新创建的一个 RecordBatch 中添加 record,而发送数据时,则会先从 queue 中最老的那个 RecordBatch 开始发送。
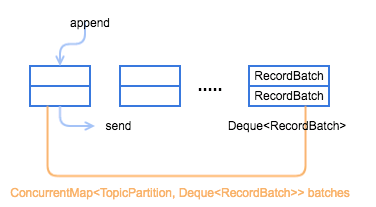
首先需要注意的是,RecordAccumulator 至少有一个业务线程和一个 Sender 线程并发操作,所以必须是线程安全的。
具体发送流程如下:
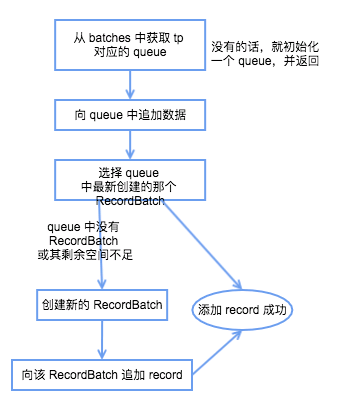
l 获取该 topic-partition 对应的 queue,没有的话会创建一个空的 queue;
l 向 queue 中追加数据,先获取 queue 中最新加入的那个 RecordBatch,如果不存在或者存在但剩余空余不足以添加本条 record 则返回 null,成功写入的话直接返回结果,写入成功;
l 创建一个新的 RecordBatch,初始化内存大小根据 max(batch.size, Records.LOG_OVERHEAD + Record.recordSize(key, value)) 来确定(防止单条 record 过大的情况);
l 向新建的 RecordBatch 写入 record,并将 RecordBatch 添加到 queue 中,返回结果,写入成功。
5. Sender从RecordAccumulator获取消息
当 record 写入成功后,如果发现 RecordBatch 已满足发送的条件(通常是 queue 中有多个 batch,那么最先添加的那些 batch 肯定是可以发送了),那么就会唤醒 sender 线程,发送 RecordBatch
6.构造ClientRequest
7. 将ClientRequest交给Network,准备发送
8. Network将请求放入KafkaChannel的缓存
9. 发送请求
10. 收到响应,调用ClientResponse
11. 调用RecordBatch的回调函数,最终调用到每一个消息上注册的回调函数
参考资料:
http://matt33.com/2017/06/25/kafka-producer-send-module/
https://segmentfault.com/a/1190000015270081
https://segmentfault.com/a/1190000015282836
http://cxy7.com/articles/2018/06/24/1529818465073.html
https://blog.csdn.net/szwandcj/article/details/76796459
https://www.jianshu.com/p/46cb44c6b96c

