Elasticsearch | 深入理解(一)
Elasticsearch | 深入理解(一)
- 简介:Elasticsearch是一个基于Apache Lucene(TM)的开源搜索引擎。Elasticsearch使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的 RESTfulAPI 来隐藏Lucene的复杂性,从而让全文搜索变得简单
- 特性:
- 分布式的实时文件存储,每个字段都被索引并可被搜索
- 分布式的实时分析搜索引擎
- 可以扩展到上百台服务器,处理PB级结构化或非结构化数据
- 安装(单节点安装)
-
要求 java环境
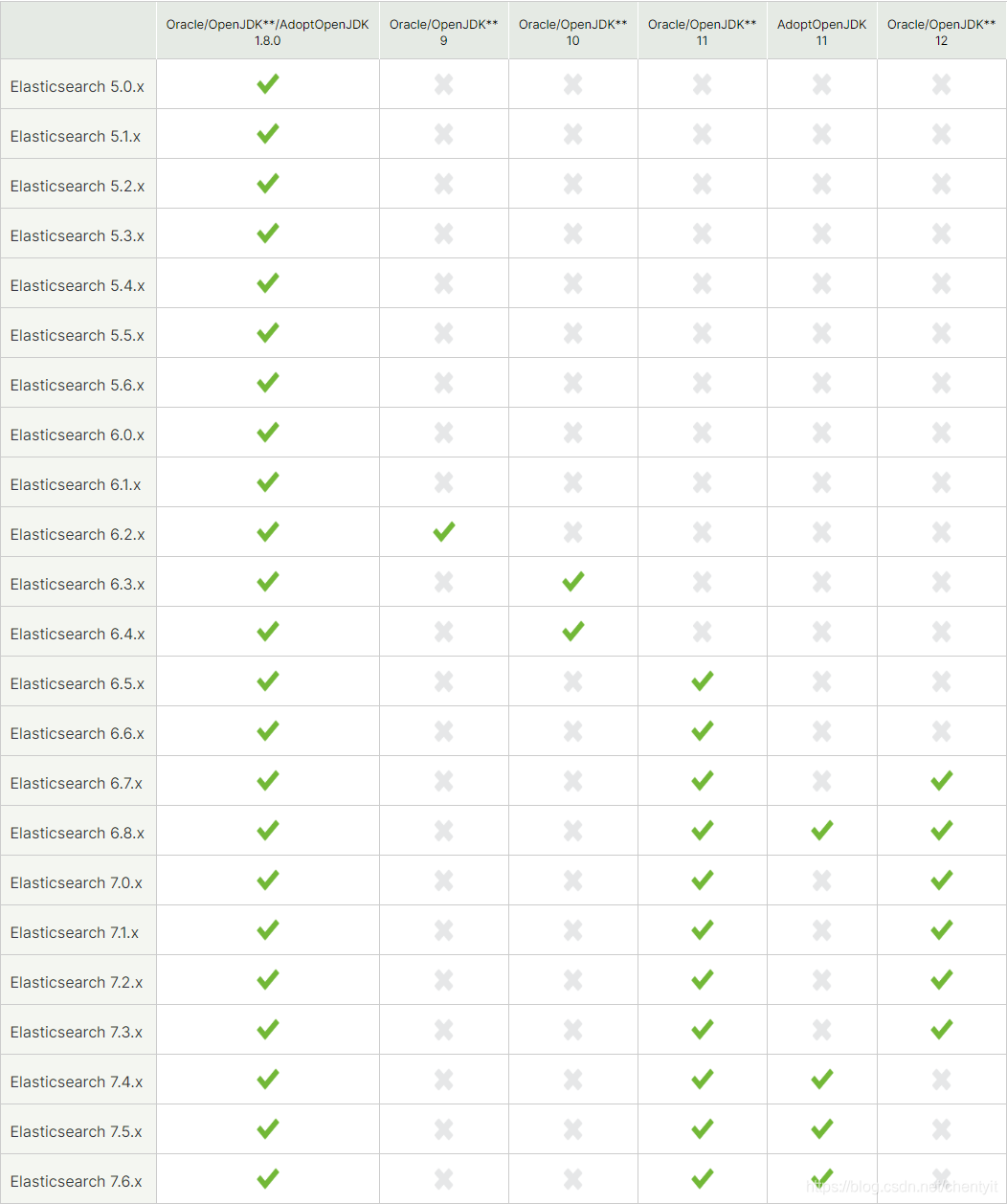
-
你可以从 es 下载最新版本的Elasticsearch
-
安装Marvel
Marvel是Elasticsearch的管理和监控工具,在开发环境下免费使用(可选) -
安装es需要新建es用户不能直接用root用户启动
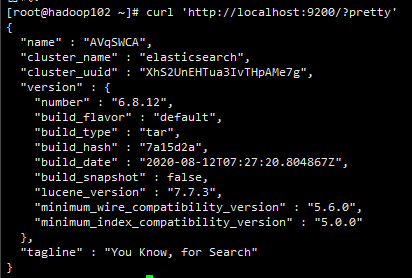
adduser elasticsearchpasswd elasticsearchchown -R elasticsearch elasticsearch-6.8.12su elasticsearch./elasticsearch -d守护进程启动curl 'http://localhost:9200/?pretty'测试
-
es2.x版本删除了_shutdown api
- 关闭
- 前台模式 直接ctrl+c
- 守护进程 查找pid + kill -9
- 安装(多节点集群安装)
- 准备环境 3台Linux机器
- 安装jdk
- 安装es
rpm -ivh elasticsearch-6.5.4.rpm或者解压包自己安装 - 系统安装配置es路径 自己安装在目录
conf下
/etc/elasticsearch/elasticsearch.yml # els的配置文件 /etc/elasticsearch/jvm.options # JVM相关的配置,内存大小等等 /etc/elasticsearch/log4j2.properties # 日志系统定义 /usr/share/elasticsearch # elasticsearch 默认安装目录 /var/lib/elasticsearch # 数据的默认存放位置- 创建用于存放数据与日志的目录
- 数据文件会随着系统的运行飞速增长,所以默认的日志文件与数据文件的路径不能满足我们的需求,那么手动创建日志与数据文件路径,可以使用NFS、可以使用Raid等等方便以后的管理与扩展
mkdir -p /opt/elasticsearch/data mkdir -p /opt/elasticsearch/log chown -R elasticsearch.elasticsearch /opt/elasticsearch/* - 集群配置
- 集群配置中最重要的两项是
node.name与network.host,每个节点都必须不同。其中node.name是节点名称主要是在Elasticsearch自己的日志加以区分每一个节点信息。
discovery.zen.ping.unicast.hosts是集群中的节点信息,可以使用IP地址、可以使用主机名(必须可以解析)
vim /etc/elasticsearch/elasticsearch.yml cluster.name: my-els # 集群名称 node.name: els-node1 # 节点名称,仅仅是描述名称,用于在日志中区分 path.data: /opt/elasticsearch/data # 数据的默认存放路径 path.logs: /opt/elasticsearch/log # 日志的默认存放路径 network.host: 192.168.60.201 # 当前节点的IP地址 http.port: 9200 # 对外提供服务的端口,9300为集群服务的端口 #添加如下内容 #culster transport port transport.tcp.port: 9300 transport.tcp.compress: true discovery.zen.ping.unicast.hosts: ["192.168.60.201", "192.168.60.202","192.168.60.203"] # 集群个节点IP地址,也可以使用els、els.shuaiguoxia.com等名称,需要各节点能够解析 discovery.zen.minimum_master_nodes: 2 # 为了避免脑裂,集群节点数最少为 半数+1 - 集群配置中最重要的两项是
- JVM配置
- 由于Elasticsearch是Java开发的,所以可以通过
/etc/elasticsearch/jvm.options配置文件来设定JVM的相关设定。如果没有特殊需求按默认即可
不过其中还是有两项最重要的-Xmx1g与-Xms1gJVM的最大最小内存。如果太小会导致Elasticsearch刚刚启动就立刻停止。太大会拖慢系统本身
vim /etc/elasticsearch/jvm.options -Xms1g # JVM最大、最小使用内存 -Xmx1g - 由于Elasticsearch是Java开发的,所以可以通过
- 创建用于存放数据与日志的目录
- 数据文件会随着系统的运行飞速增长,所以默认的日志文件与数据文件的路径不能满足我们的需求,那么手动创建日志与数据文件路径,可以使用NFS、可以使用Raid等等方便以后的管理与扩展
mkdir -p /opt/elasticsearch/data mkdir -p /opt/elasticsearch/log chown -R elasticsearch.elasticsearch /opt/elasticsearch/*
bash bin/elasticsearch
