HBase | 入门部署
HBase 简介理解
- HBase是一个NoSQL数据库,一般我们用它来存储海量的数据(它基于HDFS分布式文件系统构建)
- HBase的一行记录由一个RowKey和一个或多个的列以及它的值所组成(先有列族后有列,列可以随意添加)
- HBase的增删改记录都有「版本」,默认以时间戳的方式实现
- RowKey的设计如果没有特殊的业务性,最好设计为散列的,避免热点数据分布在同一个HRegionServer中 (也可以手动指定划分region个数)
- HBase的读写都经过Zookeeper去拉取meta数据,定位到对应的HRegion,然后找到HRegionServer
HBase 入门
- HBase 列式存储
- HBase数据模型
- 表、行、列
- 表: 可以理解为表格样的表 数据存储方式不同了
- 行: 一行数据由一个行键和一个或多个相关的列以及它的值所组成
HBase里定位一行数据需要一个唯一的值,这个叫做
行键(RowKey)- 列: HBase
列(Column)都得归属到列族(Column Family)中。在HBase中用列修饰符(Column Qualifier)来标识每个列,先有列族,后有列
- 列族: 可以简单理解为,列的属性类别
- 列表示,在列族下用列修饰符来表示一列
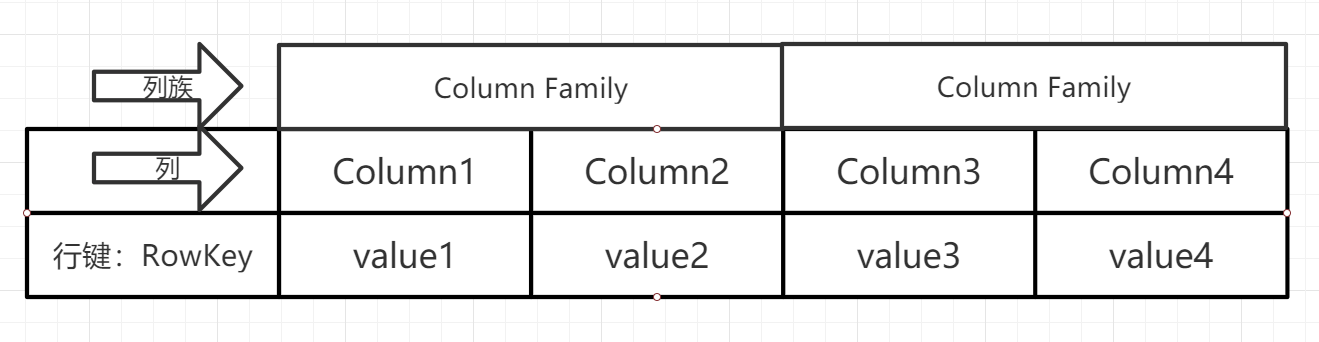
- 进一步可以理解为
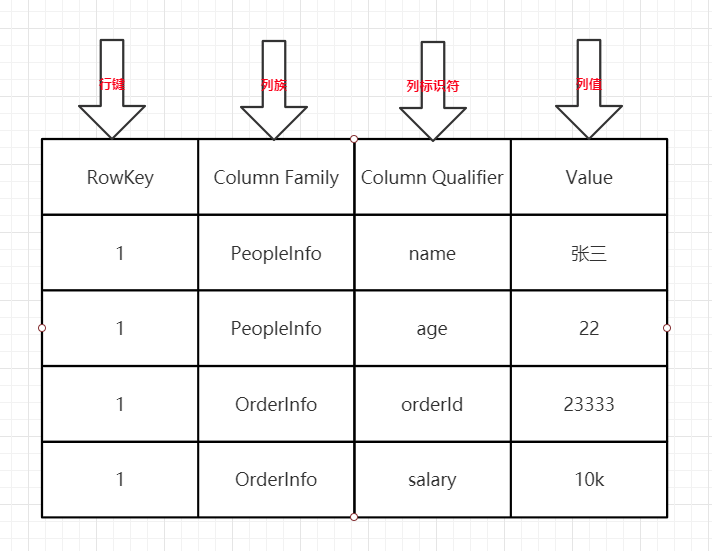
- 架构
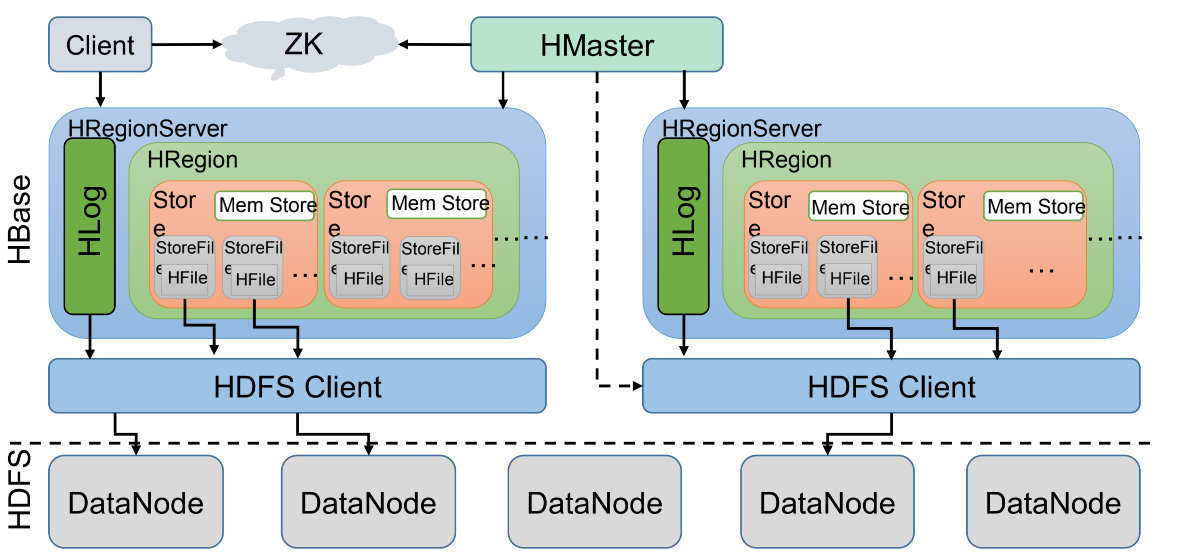
- Client客户端,它提供了访问HBase的接口,并且维护了对应的cache来加速HBase的访问。
- Zookeeper存储HBase的元数据(meta表),无论是读还是写数据,都是去Zookeeper里边拿到meta元数据告诉给客户端去哪台机器读写数据
- HRegionServer它是处理客户端的读写请求,负责与HDFS底层交互,是真正干活的节点
- 总结: client请求到Zookeeper,然后Zookeeper返回HRegionServer地址给client,client得到Zookeeper返回的地址去请求HRegionServer,HRegionServer读写数据后返回给client。
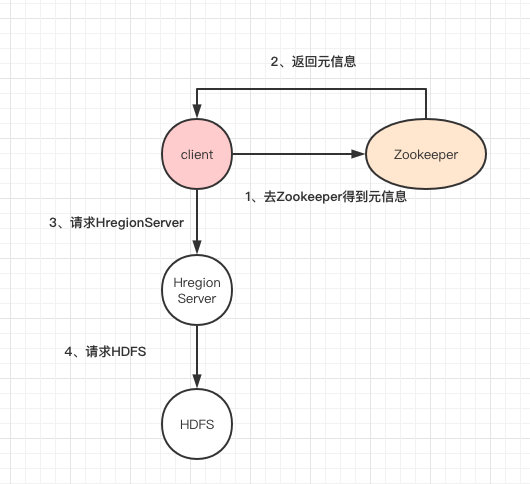
- 表、行、列
以上部分参考
HBase | 部署使用
- 启动Zookeeper
bin/zkServer.sh start
- 启动Hadoop
##hadoop102启动dfs
sbin/start-dfs.sh
##Hadoop103启动yarn
sbin/start-yarn.sh
- 解压、部署、改名
tar -zxvf hbase-1.3.1-bin.tar.gz -C/opt/moudle
mv /opt/moudle/hbase-1.3.1-bin /opt/moudle/hbase
- 配置
##hbase-env.sh 修改内容:
export JAVA_HOME=/opt/module/jdk1.6.0_144
export HBASE_MANAGES_ZK=false
##hbase-site.xml 修改内容:
<configuration>
<!--hdfs地址 namenode-->
<property>
<name>hbase.rootdir</name>
<value>hdfs://hadoop102:8020/HBase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- 0.98 后的新变动,之前版本没有.port,默认端口为 60000 -->
<property>
<name>hbase.master.port</name>
<value>16000</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop102,hadoop103,hadoop104</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/opt/module/zookeeper-3.4.10/zkData</value>
</property>
</configuration>
### regionservers 添加需要启动`region server`(真正做事的任务) 的ip
hadoop102
hadoop103
hadoop104
- 软连接 hadoop 配置文件到 HBase
##软连接讲hadoop部分配置文件到HBase(core-site.xml和hdfs-site.xml)
ln -s /opt/module/hadoop-2.7.2/etc/hadoop/core-site.xml /opt/module/hbase/conf/core-site.xml
ln -s /opt/module/hadoop- 2.7.2/etc/hadoop/hdfs-site.xml /opt/module/hbase/conf/hdfs-site.xml
- 一定要同步时间
- 最简单的方法(所有机器执行)
yum install ntpdate -yntpdate 0.cn.pool.ntp.org
- 把配置好的文件 分发到所有集群
xsync脚本自写 (往期有) - 启动/停止 集群
- 启动 方式 1
bin/hbase-daemon.sh start masterbin/hbase-daemon.sh start regionserver
- 启动/停止方式 2
- bin/start-hbase.sh
- bin/stop-hbase.sh
- 检查
- (http://linux01:16010/) 显示页面则成功 否则到 logs 文件夹下检查日志
