Python-面向对象的概念
一、面向过程和面向对象的区别
面向过程和面向对象的区别,我们用一个比较直观的例子解释一下。
面向过程是一步步执行的,比如,我们买车上牌照,面向过程的步骤就是:
1、先去4s店,买车;2、去保险公司,上保险;3、去税务局,交置购税;4、去交管局,验车、选号、交钱、上牌。
这个过程必须按顺序进行,要去4个地方。
面向对象是一站式的,我们只需要去买车办事处,然后在这个办事处完成上面的4个过程,不需要来回跑。
二、几个名词解释
类:可以理解为一个模型,比如月饼模具。
对象:指的是具体的东西,模型造出来的东西,比如在这个模型里造出来的月饼。
实例:实例就是对象。
实例化:造东西的过程。
属性:类里面的变量。
方法:类里面的函数。
构造函数:def__init__(),是非必须的,在类实例化的时候自动执行。
析构函数: def __del__(),实例被销毁时执行。
举例:
class Bird:#类名一般首字母大写 def __init__(self,name):#构造函数,非必须 print('self的id是:',id(self)) self.name = name self.wing = 2 def fly(self): print('{}会飞'.format(self.name)) self.eat()#调用类中的函数 def eat(self): print('虫子') # 类在用的时候,必须先实例化 if __name__ == '__main__': xq = Bird(name='喜鹊')#实例化:类名+括号 print('xq的id是:',id(xq)) xq.eat() xq.fly() print(xq.name)
运行结果为:
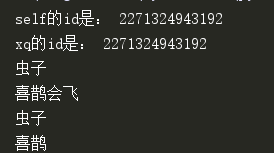
解析:
1、类名一般首字母大写;
2、类中的方法是无序的。例子中eat方法在最后面,仍然可以被其他方法调用;
3、类必须先实例化才可用。
4、self:代表的是本类对象,也可以理解为实例化之后的对象,在整个class都能使用。可以看到,self的id和实例化之后的对象xq是完全一样的。
5、顺便介绍一个和类无关的知识点。if __name_ == 'main':一般调试的时候用,直接运行这个python文件时会执行,如果是导入这个python文件,不执行这部分。
在这个python文件中打印一下__name__,会发现结果是main,所以直接运行时会执行。如果是导入的,打印出来是__main__,因此不会执行这部分代码。
三、一个类的例子
例:要求把请求的数据进行编码。请求数据为:vendorId=1697&posCode=pos006&ip=127.0.0.1&posVersion=2.1.1.1.1&mac=;D4-81-D7-CA-20-29;7C-67-A2-9A-06-05;7C-67-A2-9A-06-06;7C-67-A2-9A-06-09;00-00-00-00-00-0000E0,其中1697是商家编码。
编码规则为:
1、将商家编码(vendorId)1697进行两次MD5加密得到一个字符串 Astr
2、将请求数据
vendorId=1697&posCode=pos006&ip=127.0.0.1&posVersion=2.1.1.1.1&mac=;D4-81-D7-CA-20-29;7C-67-A2-9A-06-05;7C-67-A2-9A-06-06;7C-67-A2-9A-06-09;00-00-00-00-00-0000E0
进行urlDecode处理(编码格式为utf-8)得到一个字符串urlDecodeStr
3、urlDecodeStr + Astr 拼接得到一个待加密的字符串 beforeMD5
4、将 beforeMD5字符串进行加密得到最终的签名
分析:1、获取到数据后,首先我们要提取商家编码;2、将商家编码2次MD5加密;3、将请求数据urlDecode;4、拼接字符串,再MD5加密
首先我们用面向过程的方法来实现,如下:
import hashlib from urllib import parse def my_md5(s): md = hashlib.md5()#实例化 md.update(s.encode()) return md.hexdigest() def GetVendorId(req_data): vendor = req_data.split('&')[0] vendorId = vendor.split('=')[-1] return vendorId def SignRule(req_data): vendorId = GetVendorId(req_data) Astr = my_md5(my_md5(vendorId)) urlDecodeStr = parse.quote_plus(req_data) beforeMD5 = Astr + urlDecodeStr res = my_md5(beforeMD5) return res data = 'vendorId=1697&posCode=pos006&ip=127.0.0.1&posVersion=2.1.1.1.1&mac=;D4-81-D7-CA-20-29;7C-67-A2-9A-06-05;7C-67-A2-9A-06-06;7C-67-A2-9A-06-09;00-00-00-00-00-0000E0' res = SignRule(data) print(res)
my_md5()和GetVendorId()函数必须在SignRule()函数前面,否则会报错。用类则不会出现这个问题,上面说过,类中的方法是无序的。
用类来实现如下:
import hashlib from urllib import parse class SignRule(object): def __init__(self,req_data): self.req_data = req_data #这里写了self的话,在其他函数里面也可以用,因此其他函数不需要再写一次入参 self.GetVendorId() def md5(self,s): md = hashlib.md5() # 实例化 md.update(s.encode()) return md.hexdigest() def GetVendorId(self): vendor = self.req_data.split('&')[0] self.vendorId = vendor.split('=')[-1] return self.vendorId def GetSign(self): Astr = self.md5(self.md5(self.vendorId))#如果函数不调用的话,没办法执行,也就无法获取VendorId。
#不过在构造函数里已经调用了该函数,所以不会报错。
#如果构造函数未调用GetVendorId,则需要在这一句前面加一句 self.GetVendorId
urlDecodeStr = parse.quote_plus(self.req_data) beforeMD5 = Astr + urlDecodeStr self.res = self.md5(beforeMD5) return self.res if __name__ == '__main__': data = 'vendorId=1697&posCode=pos006&ip=127.0.0.1&posVersion=2.1.1.1.1&mac=;D4-81-D7-CA-20-29;7C-67-A2-9A-06-05;7C-67-A2-9A-06-06;7C-67-A2-9A-06-09;00-00-00-00-00-0000E0' a = SignRule(data) print(a.GetSign())
四、类的另一个例子---操作数据库
用面向过程的方法写操作数据库的脚本,有个缺点就是,我执行一次sql语句,就要连接和断开一个数据库。
用类可以解决这个问题,连接数据库的操作可以写在构造函数里,断开数据库的操作写在析构函数里。
代码如下:
import pymysql class MyDb(object): def __init__(self, host,user,passwd,db, port=3306,charset='utf8'): try: self.coon = pymysql.connect( host=host, user=user, passwd=passwd, port=port, charset=charset, db=db, autocommit=True # 自动提交 ) except Exception as e: print('数据库连接失败:{}'.format(e)) else: self.cur = self.coon.cursor(cursor=pymysql.cursors.DictCursor) def ex_sql(self,sql): try: self.cur.execute(sql) except Exception as e: print('sql语句有问题,{}'.format(sql)) else: self.res = self.cur.fetchall() return self.res def __del__(self):#析构函数,实例被销毁的时候执行 self.cur.close() self.coon.close()
比如我要执行2条sql,如下图。在这些都执行结束之后,才会执行__del__()下的代码,因此只需连接一次sql,断开1次sql。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号