LSTM容易混淆的地方
1 如果只是学习怎么用LSTM,那么可以这么理解LSTM
LSTM可以看成一个仓库,而这个仓库有三个门卫,他们的功能分别是
-
遗忘门。决定什么样的物品需要从仓库中丢弃。
-
输入门。决定输入的什么物品用来存放在仓库。
-
输出门。根据输入的物品和当前仓库的状态决定输出什么。
但这三个门外怎么判断遗忘什么,输入什么和输出什么呢?这需要他们通过从历史的数据中学习,这样当未来输入货物时,就知道如何处理。
这就是为什么LSTM能够从历史数据中学习并记住知识的原因,就是有了这三个门。
我在学习LSTM过程中一直混淆的几个概念是
1 多时间步长
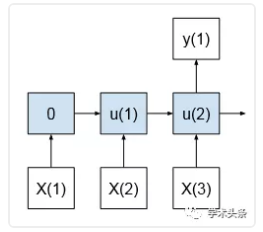
图片来自:https://www.jiqizhixin.com/articles/2019-04-01-8?from=synced&keyword=LSTM
也就是使用t-2,t-1,t 的去预测 t+1时刻的值
2 多变量
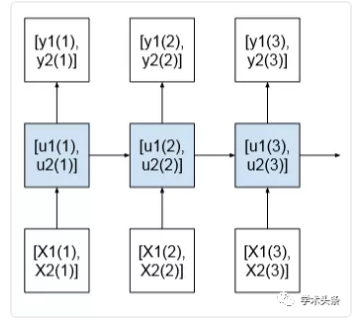
也就是使用多个特征去预测,上图没有用到多时间步长
https://machinelearningmastery.com/multivariate-time-series-forecasting-lstms-keras/
这里有一片的博客,或许对你有帮助,其中需要注意的地方是:
他分别用多变量单步时长 和 多变量多步时长(Multiple Lag Timesteps)。
它们最大的不同点在于:
下图是单步时长:1
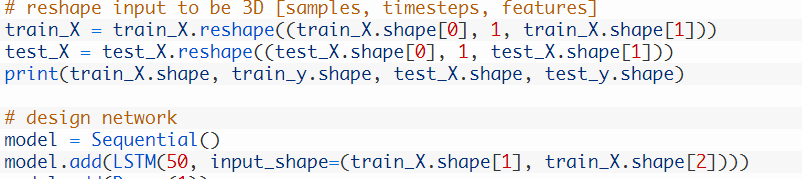
下面是多步时长:n_hours = 3 (可以设置为任何时长)

经过实践,发现多步时长的训练时间要长于单步的,准确率相比也有提高。相当于手动设置了要预测的值和之前多长时间中的值相关。有中上下文相关的意味。
3 预测未来多个时长
以上不管是多时步长还是单时步长,预测是输出值只有一个,如果我想输入当前值,预测未来多个值呢?

