sqlserver2014内存数据库特性介绍
相信大家对内存数据库的概念并不陌生,之前也有多位大牛介绍过SQL内存数据库的创建方法,我曾仔细 拜读过,有了大致了解,不过仍有很多细节不清晰,比如:
(1)内存数据库是把整个数据库放到内存中的吗?
(2)数据都在内存里面,那宕机或者断电了,数据不是没有了吗?
(3)据在内存是怎么存放的,还是按照页的方式吗,一行的大小有限制吗?
(4)内存数据库号称无锁式设计,SQL是如何处理并发冲突的呢?
相信这些疑问也是大家在思考内存数据库时经常遇到的难题,下文将为大家一一揭开这些问题的面纱,如有不对之处,还请各位看官帮我指出。
一、内存数据库是如何存储的,只放在内存吗?是把整个数据库放在内存吗?
答案:不是。
sql server 2014提供了众多激动人心的新功能,但其中我想最让人期待的特性之一就要算内存数据库了。去年我再西雅图参加SQL PASS Summit 2012的开幕式时,微软就宣布了将在下一个SQL Server版本中附带代号为Hekaton的内存数据库引擎。现在随着2014CTP1的到来,我们终于可以一窥其面貌。
内存数据库
在传统的数据库表中,由于磁盘的物理结构限制,表和索引的结构为B-Tree,这就使得该类索引在大并发的OLTP环境中显得非常乏力,虽然有很多办法来解决这类问题,比如说乐观并发控制,应用程序缓存,分布式等。但成本依然会略高。而随着这些年硬件的发展,现在服务器拥有几百G内存并不罕见,此外由于NUMA架构的成熟,也消除了多CPU访问内存的瓶颈问题,因此内存数据库得以出现。
内存的学名叫做Random Access Memory(RAM),因此如其特性一样,是随机访问的,因此对于内存,对应的数据结构也会是Hash-Index,而并发的隔离方式也对应的变成了MVCC,因此内存数据库可以在同样的硬件资源下,Handle更多的并发和请求,并且不会被锁阻塞,而SQL Server 2014集成了这个强大的功能,并不像Oracle的TimesTen需要额外付费,因此结合SSD AS Buffer Pool特性,所产生的效果将会非常值得期待。
SQL Server内存数据库的表现形式
在SQL Server的Hekaton引擎由两部分组成:内存优化表和本地编译存储过程。虽然Hekaton集成进了关系数据库引擎,但访问他们的方法对于客户端是透明的,这也意味着从客户端应用程序的角度来看,并不会知道Hekaton引擎的存在。如图1所示。

图1.客户端APP不会感知Hekaton引擎的存在
首先内存优化表完全不会再存在锁的概念(虽然之前的版本有快照隔离这个乐观并发控制的概念,但快照隔离仍然需要在修改数据的时候加锁),此外内存优化表Hash-Index结构使得随机读写的速度大大提高,另外内存优化表可以设置为非持久内存优化表,从而也就没有了日志(适合于ETL中间结果操作,但存在数据丢失的危险)
在这篇文章中,我想着重引用如下两个信息:
(1)内存数据库其实就是将指定的表放到内存中,而不是整个数据库;
(2)内存数据库用文件流的方式组织磁盘中的数据文件;
我再补充一个信息
(3)内存数据库的数据文件分data file和delta file,而且是成对出现;
1、内存数据库其实就是将指定的表放到内存中,而不是整个数据库;
内存数据库的创建过程其实就是将表存放到内存中,而不是整个数据库。下图展示 了创建内存优化表的语法,红色框标注了内存与传统表创建时语法不相同的地方。
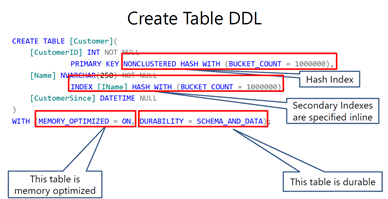
内存优化表不仅仅是把数据存放到内存中,要不然跟传统数据的缓存没有区别。在内存数据库中,内存优化表也叫为" natively compile memory-optimized tables",翻译过来就是本地编译内存优化表,内存优化表在创建的同时被编译成本地机器代码装载到内存中,本地机器代码包含了能被CPU直接执行的机器指令,所以对内存优化表的访问和操作将非常快。

内存优化表分两类,持久性表和非持久性表,对持久性表的改动会记录日志,即使数据库重启,数据也不会丢失;对非持久性表的操作不会记录日志,这些操作结果只保留在内存中,数据库重启后数据会丢失。
上文只是介绍了新建一张表的情况,在正常的业务环境中我们不可能对一个业务系统数据库的每张表都去create,那对于已经存在的表,有没有配置方法呢?答案恐怕不太令人满意,目前SQL暂不支持迁移现有表到内存中,因此要想使用内存数据库,现有的业务数据表必须重新创建。
2、内存数据库用文件流的方式组织磁盘中的数据文件
在内存数据库中,磁盘上存储的数据文件不在是区、页的存储方式,而是基于文件流存储。文件流存储的一个特点之一就是支持快速的读操作,这在数据库重启时将文件流中的数据load到内存中时很能提高效率。
3、内存数据库的数据文件分data file和delta file,而且是成对出现;
内存数据库中插入、更新的数据和删除的数据物理分开存储的,分别用data file和delta file保存。
(1)Data file
Data file用来保存"插入"或者"更新"的数据行,data file中数据行的存储顺序严格按照事务执行的顺序组织,比如data file中第一行的数据来自于事务1,第二行数据来自于事务2,这两行可以是同一个表的数据,也可以是不同表的数据,取决于这两个连续的事务操作的内存优化表是否相同。 这种方式的好处是保证了磁盘IO的连续性,避免随机IO。
Data file的大小是固定的,为128MB,当一个data file被写满了后,SQL会自动新建一个data file。因为数据在data file中保存的顺序是按照事务的执行顺序进行的,所以一张表的数据行(来自多个事务)可能跨越了多个data file,当对多行进行更新操作时,写操作可以分配到多个文件上,并且同时进行,这样就可以加快更新的效率。(下文介绍delta file时会介绍)
如下图,一共有4个data files(浅蓝色),第一个data file的事务范围为100-200,第二个data file的事务范围为200-300……(100、200表示时间戳)
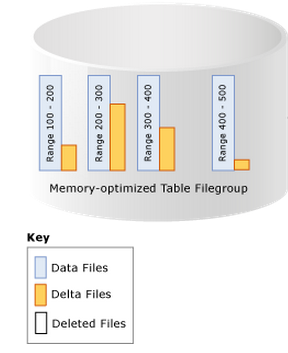
在Data file中,如果一行被删除或者更新了,这行不会从data file中移除,而是通过delta file(上图黄色框)来标记删除的行,(update的本质是delete和insert的集合,所以执行update时也会有删除的动作),这样可以消除不必要的磁盘IO。
如果data file的数据永不删除,那文件岂不是无限制的增大,以后备份不是得用很大的磁盘才行?当然不是,SQL在处理这个问题用到方法其实很简单——"合并",根据合并策略,将多个data file和delta file合并起来,依据delta file的内容删除data file中的多余记录,然后将多个data file合并成一个文件,从而减小数据文件占用的磁盘空间大小。
(2) Delta file
每个data file都有一个与之匹配的Delta File,这个匹配是指事务范围上的匹配,两者记录的是同一段事务(包括一个或者多个事务)上的数据,Delta File中记录了data file中被删除行的标记,这个标记其实就是一个关联信息{inserting_tx_id, row_id, deleting_tx_id }。它跟data file一样,也是严格按照事务操作的顺序来保存删除的行的信息。
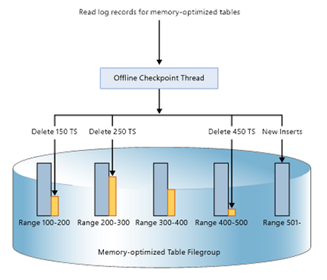
如上图,该内存数据库有5个data file,分别存放了事务范围在100-200、200-300、300-400、400-500及500的数据。如果有一个时间戳为501的事务需要删除时间戳为150、250、450的事务所产生的数据和增加一些新数据时,相应的IO请求就会被分配到第1、2、4的 delta file上和第5的data file上。删除操作可以分配到多个文件上,并且同时进行,这样就可以加快删除的效率。
二、数据都在内存里面,那宕机或者断电了,数据不是没有了吗?
答案:不是。
内存数据库通过两种方式保证数据的持久性:事务日志和chcekpoint。
(1)事务日志
内存数据库的"写日志"和"写数据"在一个事务中进行,在事务执行期间,SQL会先"写数据"然后在才"写日志",这点与传统数据库不同,在传统数据库中,不管是在内存中还是磁盘中,"写数据"总是在"写日志"之后,也就是通常所说的WAL(Write-Ahead Transaction Log)。但是,在事务提交时,内存数据库和传统数据库在"写日志"上没有什么区别:日志会先于数据写入到磁盘中。
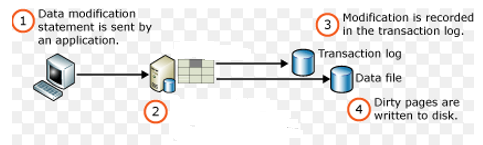
因此,即使服务器发生了宕机或者断电,下次数据库重启时会按照已经保存在磁盘中事务日志将业务redo(重做),所以不要担心数据会丢失。
另外,需要补充的是,内存数据库只会对持久性表将已提交的事物日志保存到磁盘中。这样做的好处可以减少写磁盘的次数。内存数据库支持频繁、快速的增、删、改等操作,这个强度远远高于传统数据库,数据库需要为每笔操作写日志,这样就会产生大量磁盘IO,写日志操作将有可能成为性能瓶颈,不记录未提交的事务日志就减少写日志的数量,从而可以提高数据库的性能。
有同学会想,不记录未提交事务的日志会不会导致数据不一致呢?
肯定不会,因为日志在写入磁盘前不可能发生先把"脏数据"写入到磁盘的现象(下面介绍checkpoint的时候会介绍原因)。
(2)CheckPoint
在内存数据库中,CheckPoint的主要目的就是将内存中的"数据"写入到磁盘中,从而在数据库崩溃或者重启时减少数据恢复的时间。不需要数据库逐条读取所有的日志来恢复数据。默认情况下Checkpoint是周期性进行的,当日志至上次checkpoint后增加了512M时会触发新一轮CheckPoint。
在传统数据库这种,Checkpoint可以将未提交的数据flush到磁盘的mdf文件中,这个现象在内存数据库中不会发生,因为内存数据库只将已提交事务的日志,而在写日志(到磁盘)之前不可能将数据先写到磁盘中,因此可以保证写到磁盘中的数据一定是已提交事务的数据。
三、数据在内存是怎么存放的,还是按照页的方式吗,一行的大小有限制吗?
答案:不是按照页的方式,一行的限制大小为8060Bytes。
内存优化表是基于行版本存储的,同一行在内存中会有多个版本,可以将内存优化表的存储结构看作是该表中 所有行的多个行版本的集合。
内存优化表中的行跟传统数据库的行结构是不一样的,下图描述了内存优化表中一行的数据结构:

在内存优化表中,一行有两个大部分组成:Row header和Row body,
Row header记录这个行的有效期(开始时间戳和结束时间戳)和索引指针
Row body记录了一行的实际数据。
在内存优化表中,行版本的数量是由针对该行的操作次数决定的,比如:每更新一次,就会新产生一行,增加一个行版本,新行有新的开始时间戳,新行产生后,原来的数据行会自动填充结束时间戳,意味这行已经过期。

备注:上图实际上只有3行,第1行有3个行版本,第2行有2个行版本,第3行有4个行版本。
既然同一行在内存中存在这么多的行版本,那数据库在访问时是怎么控制的呢?
在传统数据库中,表中每一行都是唯一的,一个事务如想找到一行,通过文件号、页号、槽位就可以了。
在内存数据库中,每一行有多个行版本,一个事务不可能对将每个行版本都操作一遍,实际上,一个事物只能操作同一行的一个行版本,至于它能对哪个行版本进行操作,取决于事务执行时间是否在这行的两个时间戳之间。除此之外的其他行版本对该事务而言是不可见的。
由于一行可能存在多个行版本,大家可能会提出这样一个疑问:每行都有这么多行版本,一张上百万行的表,内存哪够呀。不用担心,前文介绍过了,每个行实际上是有时间戳的,对于已经打上结束时间戳且没有活动事务访问的行,SQL Server会通过garbage collection机制回收它占用的内存,从而节省内存。所以不要担心内存不够。
四、内存数据库号称无锁式设计,那如果发生了并发冲突怎么办,SQL是如何处理冲突的呢?
答案:内存数据库用行版本来处理冲突。
锁的一个重要作用就是避免多个进程同时修改数据,从而造成数据不一致。常见的冲突现象包括读写互锁和写写互锁。那内存数据库是如何通过行版本来解决这两种锁定现象的呢?
(1)读写互锁
在内存数据库中,所有对内存优化表的事务隔离都是基于快照的,准确的说是基于行的快照。从上文行的 结构可以知道,每行的行头包括开始时间戳和结束时间戳的,一个事务能不能访问到这行关键在于事务的启动时间是不是在这行的两个时间戳内。
如果某个事务正在修改一行(快照),但还未提交到内存优化表中,也就是说"新行"还没有结束时间戳,对"读事务"而言,它读还是是原来行(快照),因此不会存在脏读的现象。
(2)写写互锁
两个事务同时更新一行时,就会发生写写互锁。
内存数据库冲突发生的概率比传统数据库小很多,但如果实在遇到了冲突,只能调整应用程序,在应用程序中加入"重试逻辑"(等待一会,然后再重新发起事务)来解决。
或许有同学觉得这种方式好像也没有什么大的性能改变。其实不然,举个例子,在传统数据库中一个锁可能将整个表都管住了,在表锁期间只能等待这个事务做完才能执行其他事务,而实际上这个事务可能只是修改了小部分行,因为表锁的存在,其他行那些不需要被这个事务操作的行。但内存数据库中写写冲突总是发生在行级别的,这个粒度小多了,影响没这么大。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号