Lucene.net提供了很全面的数据搜索操作,你可以利用Lucene.net检索磁盘中的文件,网页,数据库中的数据,但是前提是预先对数据创建索引。
Lucene索引过程分为三个主要的操作阶段:将数据转换成文本、分析文本、并将分析过的文本保存到索引库中。如图所示:
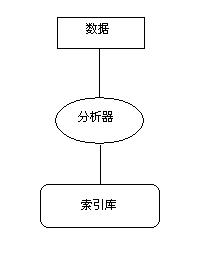
1.数据转成文本:须将数据转换成Lucene能够处理的格式——纯文本字符流。
2.分析文本:完成了针对待索引数据的预处理操作,并创建了带有若干个域的Document对象,就可以调用IndexWriter的addDocument(Document)方法,将数据传递给Lucene来进行索引操作。在对数据进行索引处理时,Lucene会首先分析(analyze)数据使之更加适合被索引。
3.将分析过的文本保存到索引库中:对输入数据分析处理完之后,就可以将结果写入到索引文件中。Lucene将输入数据以一种称为倒排索引(inverted index)的数据结构进行存储。在进行关键字快速查找时,这种数据结构能够有效地利用磁盘空间。
下面介绍下Lucene.net中处理索引的类:
 IndexWriter
IndexWriter
IndexWriter是索引中负责操作的核心,它负责把索引文件写入存储介质,是控制逻辑存储转换为物理存储的纽带。
Document
Document就是一条虚拟记录,可以理解为数据里的一行。正是有了它,才使我们可以很方便并且易于理解地操作索引文件。它一般记录了需要用到的一个文档的属性,当然,这需要和Field联合使用。
Field
Field类就是数据库里的一列。一个文档有标题,内容,作者,创建时间这四个属性的话,那么就需要四个Field保存这些属性,然后把四个Field加入到Document中。
Field的构造函数比较多。其中Store,Index和TermVector是通过内部类指定的。
(1)--Store 有三个选项:
Field.Store.COMPRESS表示被压缩存储;
Field.Store.YES表示储存;
Field.Store.NO表示不被存储。
(2)--Index的选项有四个:
Field.Index.NO表示不建立索引;
Field.Index.TOKENIZED表示分词后索引;
Index.NO_NORMS表示值存储内容;
Field.Index.UN_TOKENIZED表示不分词索引。
(3)--TermVector这个参数也不常用,它有五个选项。
Field.TermVector.NO表示不索引Token的位置属性;
Field.TermVector.WITH_OFFSETS表示额外索引Token的结束点;
Field.TermVector.WITH_POSITIONS表示额外索引Token的当前位置;
Field.TermVector.WITH_POSITIONS_OFFSETS表示额外索引Token的当前和结束位置;
Field.TermVector.YES则表示存储向量。
通过实例生成数据索引:
这里我将数据保存在Access数据库中,对Access数据库中的数据进行索引:
保存数据的表:数据库中保存了1000条数据
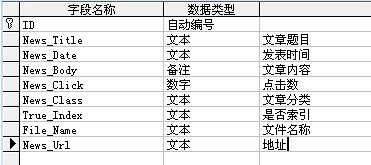
为数据创建索引代码:

 Code
Code
using System;
using System.Data;
using System.Configuration;
using System.Web;
using System.Web.Security;
using System.Web.UI;
using System.Web.UI.WebControls;
using System.Web.UI.WebControls.WebParts;
using System.Web.UI.HtmlControls;
using System.Collections.Generic;
using System.Text;
using System.IO;
using System.Text.RegularExpressions;
using System.Data.SqlClient;
using Lucene.Net.Analysis;
using Lucene.Net.Documents;
using Lucene.Net.Index;
using Lucene.Net.Analysis.KTDictSeg;
using LuceneSearch;
/// <summary>
/// CreateIndex 的摘要说明
/// </summary>
public class CreateIndex
{
//词库路径
public string wordPath;
public string indexDirectory;
//定义一个IndexWriter
protected IndexWriter writer = null;
//需要导出的数目
public int allNum;
//当前完成的数目
public int completeNum;
//需要生成的表
public DataTable dt;
DAL.OperSql os = new DAL.OperSql();
public CreateIndex()
{
}
public void GetIndex(int inum)
{
//定义分析器
Analyzer KTDAnalyzer = new KTDictSegAnalyzer(wordPath);
//PerFieldAnalyzerWrapper可以对不同的Field进行不同的分析
PerFieldAnalyzerWrapper wrapper = new PerFieldAnalyzerWrapper(KTDAnalyzer);
wrapper.AddAnalyzer("ID", KTDAnalyzer);
wrapper.AddAnalyzer("News_Url", KTDAnalyzer);
wrapper.AddAnalyzer("News_Date", KTDAnalyzer);
//判断是否已有索引
bool isure = !IndexReader.IndexExists(indexDirectory);
//创建索引的数据条数
allNum = dt.Rows.Count;
//创建IndexWriter
writer = new IndexWriter(indexDirectory, wrapper, isure);
writer.SetUseCompoundFile(true); //显式设置索引为复合索引
writer.SetMaxFieldLength(int.MaxValue); //设置域最大长度为最大值
writer.SetMergeFactor(allNum + 100); //设置每100个段合并成一个大段
writer.SetMaxMergeDocs(10000); //设置一个段的最大文档数
writer.SetMaxBufferedDocs(1000); //设置在把索引写入磁盘前内存里文档的缓存个数
//创建IndexReader
IndexReader reader = null;
bool needre = inum == 1;
reader = IndexReader.Open(indexDirectory);
for (int i = 0; i < dt.Rows.Count; i++)
{
completeNum = i + 1;
string body = parseHtml(dt.Rows[i]["News_Body"].ToString());
string title = parseHtml(dt.Rows[i]["News_Title"].ToString());
if (title.Length > 2 && body.Length > 2)
{
if (needre)
{
Term term = new Term("ID", dt.Rows[i]["ID"].ToString());
reader.DeleteDocuments(term);
}
Document document = new Document();
document.Add(new Field("ID", dt.Rows[i]["ID"].ToString() ?? "", Field.Store.YES, Field.Index.UN_TOKENIZED));
document.Add(new Field("News_Title", title, Field.Store.NO, Field.Index.TOKENIZED));
document.Add(new Field("News_Body", body, Field.Store.NO, Field.Index.TOKENIZED));
document.Add(new Field("News_Url", dt.Rows[i]["News_Url"].ToString() ?? "", Field.Store.YES, Field.Index.UN_TOKENIZED));
document.Add(new Field("News_Date", DateField.DateToString(Convert.ToDateTime(dt.Rows[i]["News_Date"].ToString())) ?? "", Field.Store.YES, Field.Index.UN_TOKENIZED));
writer.AddDocument(document);;
}
}
reader.Close();
writer.Optimize();
writer.Close();
}
}传入参数,生成索引文件:
Code
try
{
ci.wordPath = Server.MapPath("App_Data") + @"\"; //词库路径;
ci.indexDirectory = Server.MapPath("index") + @"\"; //词库路径;
ci.dt = dt;
ci.GetIndex(1);
}
其中dt是保存数据的DataTable,wordpath是分词器的词库文件chsstopwords.txt,engstopwords.txt,dict.dct的路径,indexDirectory是生成索引文件的路径。
生成索引成功后,我们会在index文件夹下看到生成的文件:
这样,我们就创建好了数据的索引。检索数据的时候,我们就可以利用它快速的对数据进行检索。

 Search Engine,
Search Engine, 

【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 地球OL攻略 —— 某应届生求职总结
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· .NET周刊【3月第1期 2025-03-02】
· [AI/GPT/综述] AI Agent的设计模式综述