[RoarCTF2019]Polyre | bypass ollvm
代码混淆技术:控制流平坦化
OLLVM(Obfuscator-LLVM) 是瑞士西北应用科技大学安全实验室于2010年6月份发起的一个项目,该项目旨在提供一套开源的针对 LLVM 的代码混淆工具,以增加对逆向工程的难度。
github: https://github.com/obfuscator-llvm/obfuscator
OLLVM 的控制流平坦化是一种常见的代码混淆方式,其基本原理是添加分发器来控制流程的执行。针对这种混淆方式的还原也有了许多研究和工具,大致思路分为动态和静态两种:
-
动态:通过Unicorn模拟执行的方式获取各真实块的关系
-
静态:通过符号执行、中间语言分析等方式获取真实块之间的关系。
简单来说,OLLVM会添加一个用于控制跳转的状态变量和分发器:当一个真实块执行完成后,会把状态变量的值进行更新,回到分发器进行检查,再根据状态变量的值跳转到下一个真实块执行;
如果原本的执行流程中存在条件跳转,则会在各条件下对状态变量设置不同的值,再回到分发器进行检查和跳转。
详见:https://security.tencent.com/index.php/blog/msg/112
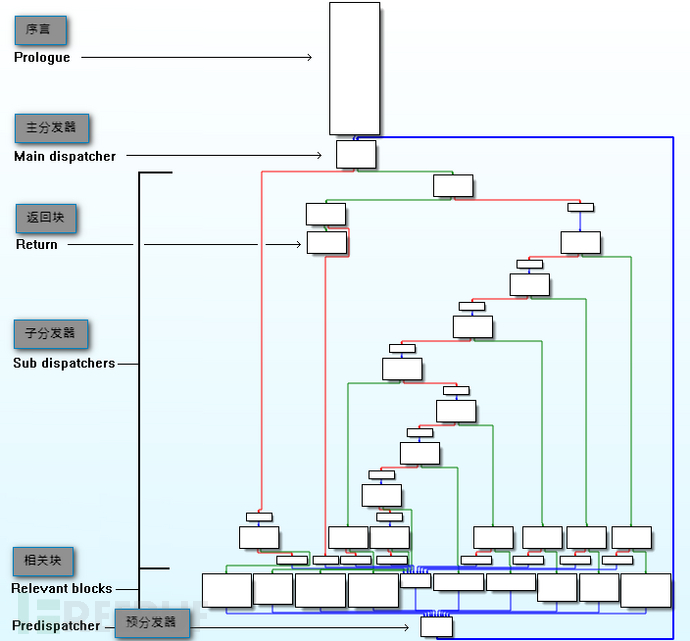
DeFlat
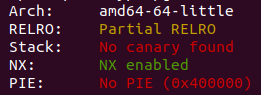
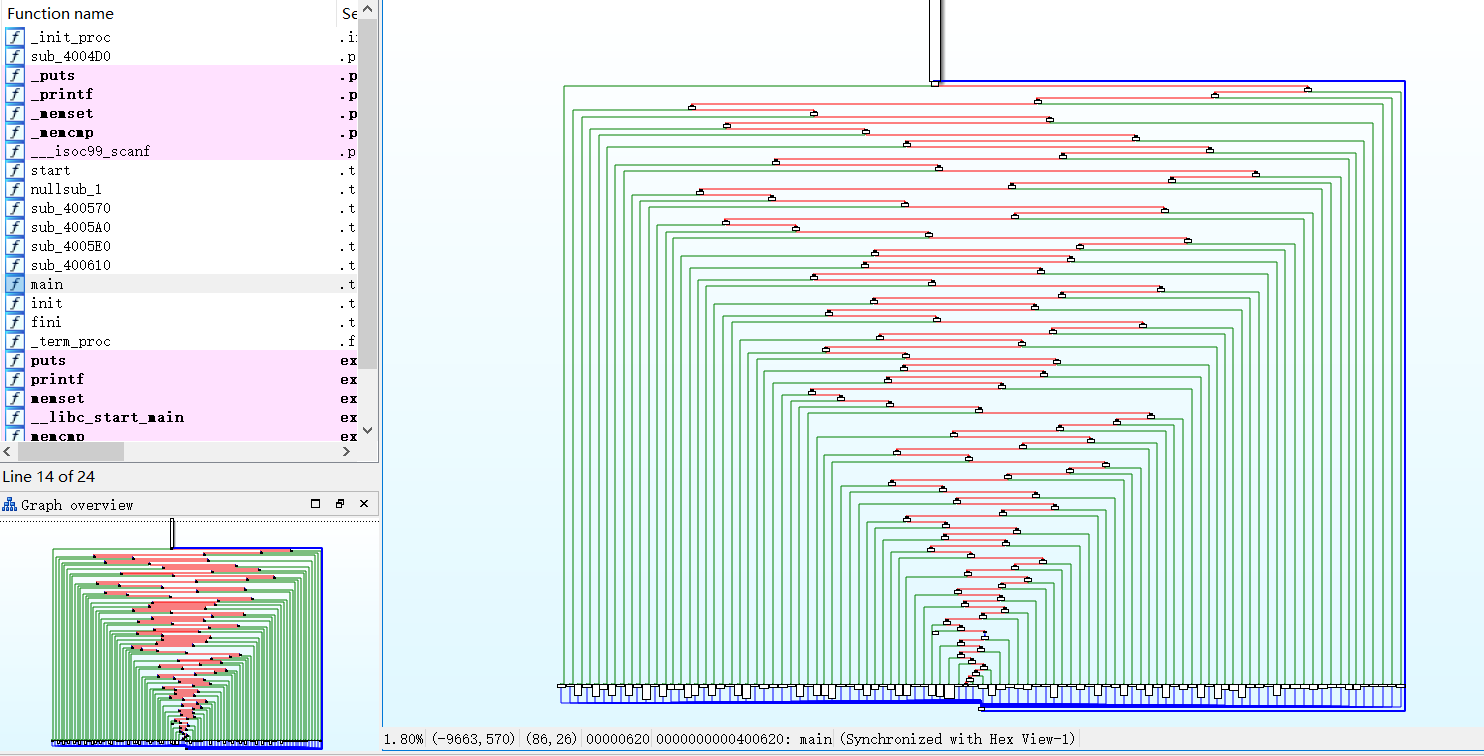
这是 IDA 中 main() 函数的流程图,源程序经过 ollvm 混淆控制流被完全平坦化了
针对 x86 架构下 Obfuscator-LLVM 的控制流平坦化,可以使用作者为 Bird 的 DeFlat 工具反混淆
github: https://github.com/cq674350529/deflat
Usage:
git clone https://github.com/cq674350529/deflat.git
python deflat.py -f ./attachment --addr 0x400620
其中 0x400620 是 main() 的地址,运行时间大概 3 min
基于前文介绍的 deflat 原理,修改后的 ELF 文件的大小并不会改变,再次拖入 IDA 分析
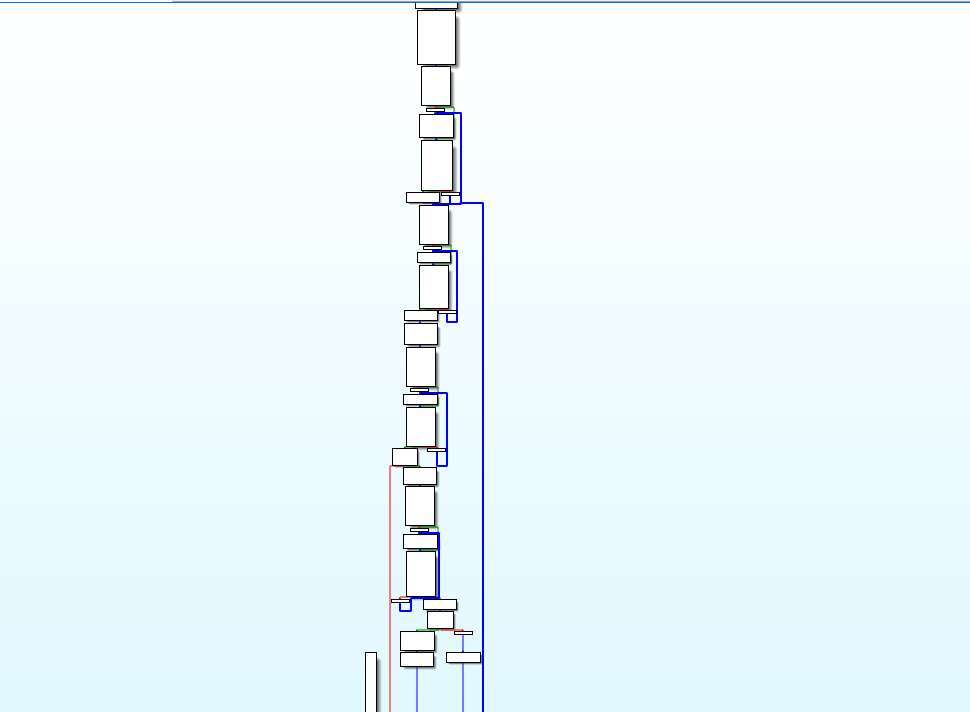
无法完美还原,但是程序控制流已经正常多了~
静态分析
main():
__int64 __fastcall main(__int64 a1, char **a2, char **a3)
{
v10 = 0;
memset(s, 0, 0x30uLL);
memset(s1, 0, 0x30uLL);
printf("Input:", 0LL);
v11 = s;
if ( dword_603058 >= 10 && (((_BYTE)dword_603054 - 1) * (_BYTE)dword_603054 & 1) != 0 )
goto LABEL_43;
while ( 1 )
{
__isoc99_scanf("%s", v11);
v6 = 0;
if ( dword_603058 < 10 || (((_BYTE)dword_603054 - 1) * (_BYTE)dword_603054 & 1) == 0 )
break;
LABEL_43:
__isoc99_scanf("%s", v11);
}
while ( 1 )
{
do
v12 = v6;
while ( dword_603058 >= 10 && (((_BYTE)dword_603054 - 1) * (_BYTE)dword_603054 & 1) != 0 );
v13 = v12 < 64;
while ( dword_603058 >= 10 && (((_BYTE)dword_603054 - 1) * (_BYTE)dword_603054 & 1) != 0 )
;
if ( !v13 )
break;
v14 = s[v6];
do
v15 = v14;
while ( dword_603058 >= 10 && (((_BYTE)dword_603054 - 1) * (_BYTE)dword_603054 & 1) != 0 );
if ( v15 == 10 )
{
v16 = &s[v6];
*v16 = 0;
break;
}
v17 = v6 + 1;
do
v6 = v17;
while ( dword_603058 >= 10 && (((_BYTE)dword_603054 - 1) * (_BYTE)dword_603054 & 1) != 0 );
}
for ( i = 0; ; ++i )
{
do
v18 = i;
while ( dword_603058 >= 10 && (((_BYTE)dword_603054 - 1) * (_BYTE)dword_603054 & 1) != 0 );
do
v19 = v18 < 6;
while ( dword_603058 >= 10 && (((_BYTE)dword_603054 - 1) * (_BYTE)dword_603054 & 1) != 0 );
if ( !v19 )
break;
do
v20 = s;
while ( dword_603058 >= 10 && (((_BYTE)dword_603054 - 1) * (_BYTE)dword_603054 & 1) != 0 );
v4 = *(_QWORD *)&v20[8 * i];
v7 = 0;
while ( 1 )
{
v21 = v7;
do
v22 = v21 < 64;
while ( dword_603058 >= 10 && (((_BYTE)dword_603054 - 1) * (_BYTE)dword_603054 & 1) != 0 );
if ( !v22 )
break;
v23 = v4;
v24 = v4 < 0;
if ( v4 >= 0 )
{
v27 = v4;
do
v28 = 2 * v27;
while ( dword_603058 >= 10 && (((_BYTE)dword_603054 - 1) * (_BYTE)dword_603054 & 1) != 0 );
v4 = v28;
}
else
{
v25 = 2 * v4;
do
v26 = v25;
while ( dword_603058 >= 10 && (((_BYTE)dword_603054 - 1) * (_BYTE)dword_603054 & 1) != 0 );
v4 = v26 ^ 0xB0004B7679FA26B3LL;
}
v29 = v7;
do
v7 = v29 + 1;
while ( dword_603058 >= 10 && (((_BYTE)dword_603054 - 1) * (_BYTE)dword_603054 & 1) != 0 );
}
v30 = 8 * i;
v31 = &s1[8 * i];
if ( dword_603058 >= 10 && (((_BYTE)dword_603054 - 1) * (_BYTE)dword_603054 & 1) != 0 )
LABEL_55:
*(_QWORD *)v31 = v4;
*(_QWORD *)v31 = v4;
if ( dword_603058 >= 10 && (((_BYTE)dword_603054 - 1) * (_BYTE)dword_603054 & 1) != 0 )
goto LABEL_55;
v32 = i + 1;
}
do
v33 = memcmp(s1, &unk_402170, 0x30uLL);
while ( dword_603058 >= 10 && (((_BYTE)dword_603054 - 1) * (_BYTE)dword_603054 & 1) != 0 );
v34 = v33 != 0;
while ( dword_603058 >= 10 && (((_BYTE)dword_603054 - 1) * (_BYTE)dword_603054 & 1) != 0 )
;
if ( v34 )
puts("Wrong!");
else
puts("Correct!");
return v10;
}
显然 word_603058 >= 10 && (((_BYTE)dword_603054 - 1) * (_BYTE)dword_603054 & 1) != 0 恒为 False,
所以可以把相应的 do-while 结构删掉
相应地,dword_603058 < 10 || (((_BYTE)dword_603054 - 1) * (_BYTE)dword_603054 & 1) == 0 恒 True
人工调整后可以复现出加密的代码,如下:
#include <bits/stdc++.h>
using namespace std;
unsigned char in[1007],flag[1007];
int len;
int main() {
// in flag: len == 48
memset(in,0,sizeof(in));
memset(flag,0,sizeof(flag));
scanf("%s",in),len=3;
for (int i=0; i<len; i++)
if (in[i]=='\n') in[i]=0;
for (int i=0; i<6; i++) {
cout<<(&in+i*8)<<endl;
__int64 p = *((__int64 *)&in[i*8]);
cout<<p<<endl;
for (int j=0; j<64; j++) {
//encode x64
if (p>=0) p*=2; // p<<=1
else p=p*2^0xB0004B7679FA26B3LL; //p=p<<1^0xB000...
}
*(__int64 *)(&flag[i*8])=p;
}
if (memcmp(flag,encode,48)) puts("Wrong!");
else puts("Correct!");
return 0;
}
加密过程
-
输入一串长度为 48 的字符串,8 个字符(字节)为一组,拆分成 6 组
-
每组以小端序赋值给一个 __int64 (long long) 类型的变量
-
将改变量进行 64 轮变换,变换规则见代码
-
按字节还原至 flag 数组中,与加密后的原文进行比较,判断正误
EXP
看懂了加密算法,不难写出逆向解密的脚本
需要注意的是一个有符号数右移之后,负数会变成正数,所以需要再异或一个 0x8000000000000000
这样就能实现负数的除法了
#include <bits/stdc++.h>
using namespace std;
unsigned char encode[48] = { 0x96, 0x62, 0x53, 0x43, 0x6D, 0xF2, 0x8F, 0xBC,
0x16, 0xEE, 0x30, 0x05, 0x78, 0x00, 0x01, 0x52,
0xEC, 0x08, 0x5F, 0x93, 0xEA, 0xB5, 0xC0, 0x4D,
0x50, 0xF4, 0x53, 0xD8, 0xAF, 0x90, 0x2B, 0x34,
0x81, 0x36, 0x2C, 0xAA, 0xBC, 0x0E, 0x25, 0x8B,
0xE4, 0x8A, 0xC6, 0xA2, 0x81, 0x9F, 0x75, 0x55
};
unsigned char flag[48];
int main() {
for (int i=0;i<6;i++) {
__int64 p = *((__int64 *)&encode[i*8]);
for (int j=0;j<64;j++) {
// check the last bit
if (p&1) {
p=((unsigned __int64)p^0xB0004B7679FA26B3LL)/2; // p=(p^0xB000...)>>1
p|=0x8000000000000000; // avoid - to +
}
else p=(unsigned __int64)p/2; // p>>=1;
}
for (int j=0;j<8;j++) printf("%c",(char)p&0xff),p>>=8;
}
return 0;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号