indexDB出坑指南(二)
为什么要续写一篇这样的指南?在indexDB中,指南(一)深入介绍了事务,但对于如何用好事务还不够详细。此外,各种事件在事务、请求、DB三者之间传播;objectStore创建时 key的规则定义;indexDB的意外情况等,这些在实际开发中非常重要的知识点,指南(一)也没有介绍。所以续写很有必要。
开始前,还是强烈建议你好好读一下 indexDB出坑指南(一),并且至少通过demo体验过了indexDB,至少尝试过通过事务保持数据的一致性。
再谈indexDB中的事务
在你使用indexDB时,事务绝对是第一等公民,即便是只有一条简单请求的功能实现,你也需要先开启事务。回顾一下,指南一中 删除上传任务:删除任务信息和文件信息,所有请求同时必须成功,或者同时失败,否则就会引起数据不一致、永久性的脏数据等问题。能够保证数据的一致性,这就是事务的特性。
实际开发中,每个场景实际上都对应着一个事务,所以为你的项目写一个事务服务是明智的选择:事务服务的每个方法,都对应一个完整的操作场景。写一个事务服务又有什么要点呢?
事务中的封装
封装抽取可复用代码,避免重复code,在事务这里可能要好好思考一下。
举个例子:数据清理场景下,我们会遍历所有数据,找出过期的并清除掉;数据删除场景下,我们只需要根据传入的关键字删除一条数据。
clearData(){ const trans = DB.transaction(STORE_NAME, 'readwrite') const objectStore = trans.objectStore(STORE_NAME) const rangeReq = objectStore.openCursor() rangeReq.onsuccess = () => { let cursor = rangeReq.result; if (!cursor) { return } let task = cursor.value if (task.lastModify < minTime) { objectStore.delete(task.id) // 重复点:把这想象成有很多行,你非常想复用的那种。 //你也许想直接调用delTask(task),但这会报错,因为两个readwrite事务不能同时开启 } cursor.continue() } } delTask(task){ const trans = DB.transaction(STORE_NAME, 'readwrite') const objectStore = trans.objectStore(STORE_NAME) objectStore.delete(task.id) // 重复点 }
你可以再抽一个下面这样的方法,然后将上面的重复点,换成调用 delOperate(objectStore, task)。
delOperate(objectStore, task){ // 相同部分抽取为函数,函数不会开启事务,但是会使用事务下的objectStore,index等
objectStore.delete(task.id)
}
你还可以改造clearData方法,只是收集需要清理的task,而不做真正的清理。结束后,对收集到的每个task,在调用 delTask 方法。
实现promise的正确方式
indexDB操作都是基于事件的,而前端开发喜欢异步(promise化)。如何将操作封装成异步的呢?指南一 只举了一个失败的例子,其实正确封装很简单。
const trans = db.transaction(['tasks', 'files'], 'readwrite') const tasksStore = trans.objectStore('tasks') const filesStore = trans.objectStore('files') return new Promise((resolve,reject)=>{ tasksStore.delete(processId).onsuccess = () => { filesStore.delete(processId).onsuccess = () => { resolve() } } })
上面的封装很简单,一看就懂。但它有2个问题:
两个请求是串发的了(他们本可以并发的),这无疑影响了性能;
追踪所有请求,是一个巨大的工作量。考虑一下:你需要追踪每个请求的error事件,来实现出错时reject;非常复杂的事务,串发请求肯定就是地狱嵌套了;你也可以让请求并发享受高性能,但要借助类似于 totalRequestCount,successRequestCount 这些辅助变量来控制了。
所幸的是,除了请求,事务本身也有3个事件:complete(所有请求都成功后触发),error(任何一个请求失败后触发),abort(意外或主动终止)
所以最佳封装应该是这样的:
const trans = db.transaction(['tasks', 'files'], 'readwrite') const tasksStore = trans.objectStore('tasks') const filesStore = trans.objectStore('files') // 尽情让你的请求并发起来吧(请求无需追踪,简洁,清晰,高效): tasksStore.delete(processId) filesStore.delete(processId) // 直接在事务上封装:注意事务失败有error和abort两种事件 return new Promise((resolve,reject)=>{ trans.oncomplete = () => { resolve() } trans.onerror = trans.onabort = e => { reject(e) } })
注意避免副作用
数据通过引用传递(什么是引用传递?请自行百度)时,一处改变 所有地方都同步变化,这个特点可能是让你编码更高效的技巧,但也可能会给你带来痛苦的噩梦。在你使用这一技巧时,如果事务失败一定要记得消除副作用。
下方例子注意注释处:
clearArticle(task, article) { const trans = DB.transaction([STORE_NAME], 'readwrite') const objectStore = trans.objectStore(STORE_NAME) const cloneOpLen = article.opLen // 临时缓存 const cloneTime = task.lastModify // 临时缓存 // … … 省略其他代码 article.opLen = 0 // 修改 task.lastModify = Date.now(); // 修改 objectStore.put(article) objectStore.put(task) return new Promise((resolve, reject) => { trans.onerror = trans.onabort = e => { article.opLen = cloneOpLen // 事务失败,回滚对变量的修改,消除副作用 task.lastModify = cloneTime // 事务失败,回滚对变量的修改,消除副作用 // 上面两行尤为重要:事务失败,indexDB中的数据自动回滚,但变量的修改需要你自己控制其回滚了! reject(e) } }) }
事务的其他事项
1、事务只能自动提交,不能手动提交。
2、设计成事务是因为考虑到用户可能打开两个选项卡,用事务保证数据的一致性。采用异步事务,通过事件交互,是为了防止大量数据的读写拖慢网页。
3、一个链接可以同时有多个活动的事务,前提是不与写操作事务的作用域有重叠。(一个store一旦有相关的“可写事务”在活动,那么这个store相关的事务只能有这一个在活动)
作用域:事务涉及到的store,开启事务时第一个参数指明。规范中当传入一个空数组,表示事务涉及到所有的store,但这个特性最好不要用,有歧义且性能不好。
4、事务oncomplete之后,数据就持久化到磁盘中了吗?99.99999...%的情况是。当操作系统被告知去写入数据后 complete 事件便被触发,但此时数据可能还没有真正的写入磁盘。会有极小的机会发生以下情况:如果操作系统崩溃或在数据被写入磁盘前断电,那么整个事务都将丢失。由于这种灾难事件是罕见的,通常并不需要过分担心。
如果极端情况下非要保证100%,可以去了解实验中的模式:readwriteflush,真正写入磁盘后才触发complete
indexDB中的事件系统
在indexDB中三种对象会产生事件,用一张图表示:
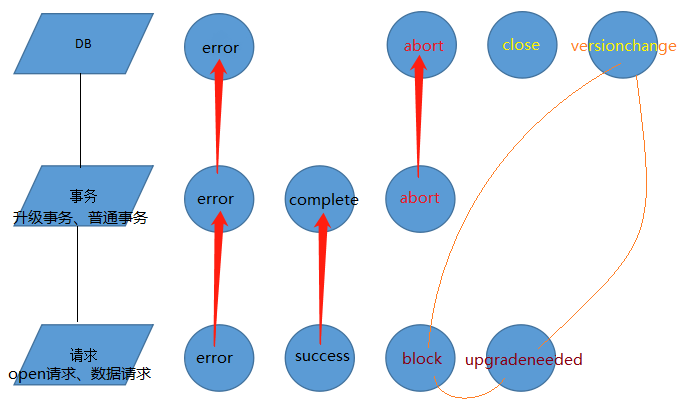
请求都有有两个事件:
error(失败),success(成功)。
IDBOpenRequest开启数据库链接请求:额外多了block事件(其他页面已有其他版本,通常是较低版本的连接时触发)和 upgradeneeded事件。如果成果触发了upgradeneeded事件,Handler处理完成后才会触发success事件。
事务:VersionChange事务和普通事务都三个事件:
error事件:事务下任何一个请求出错会触发
complete事件:事务下所有请求都成功后会触发
abort事件:外界的异常(如关闭应用,磁盘异常等)以及主动调用 transaction.abort() 会触发
DB:
error和abort事件:事务的error和abort事件会冒泡给DB。如果你想全局处理操作异常的话,可以直接监听DB的这两个事件。
versionchange事件:正处于链接状态的DB,如果其他页面要升级数据库会触发当前页面的改事件
close事件:关闭连接后触发。外界异常会导致连接关闭,当然这会先abort所有事务。主动调用 db.close() 也会关闭连接。
上面有个黄色的圈:开启数据库请求的block事件,upgradeneeded事件和数据库的versionchange事件,从上面的描述就可以看出三者相关性很强!
相信你已经豁然开朗了。
创建ObjectStore时的Key
objectStore中存放的每一条数据,总会关联一个key,类似于SQL数据库中的主键。
数据的增删改查中,add(增)、put(改或增)返回的结果就是key,delete(删)传入的参数都是一个key。不用索引,直接objectStore.get(查)传入的参数也是key。
key是在创建objectStore时定义的:
// 'keyPath' 或 'autoIncrement'(即所谓的keyGenerator) 两两组合有以下四种定义key的方法: const objStore = db.createObjectStore("storeName"); const objStore = db.createObjectStore("storeName", { autoIncrement : true }); const objStore = db.createObjectStore("storeName", { keyPath : 'id' }); const objStore = db.createObjectStore("storeName", { keyPath : 'id', autoIncrement : true });
- 没有配置autoIncrement时,新增和修改数据时必须指明key(如果配置了keyPath,对应的字段必须存在);
- 配置autoIncrement时,新增和修改时可以不指明key(如果配置了keyPath,对应的字段可以没有);
这时会自动生成一个数值类型的key:自动生成从1开始,不断递增;即使删除数据,甚至清空store,也不会影响key的递增,除非事务回滚;如果新增数据时显式指明了一个很大的数值类型key,超过了最后一次的递增结果,那么接下来会以这个数值为基础来递增。当然你还是可以显式指明一个(任意类型的)key。 - 配置keyPath时,顾名思义就是以存放到store中的数据中的属性值来作为key,比如上面第三种情况,每次新增或修改的数据都必须有id字段,字段值就是对应的key值(第四种情况可以没有id字段,这时会自动生成一个key,并为数据追加一个id字段,值就是这个key)。
- 配置keyPath时,你存放的数据就只能是js对象了。不配置keyPath时,可以存放任何数据。
- 不配做keyPath时,store中存放的数据本身是没有key的信息的,这种store一般是作为其他store的附属的。
- 显示指明key时,key可以是任何类型,甚至二进制类型。
没有keyPath时,新整修改数据指明key的示例:
objectStore.add(data, 'fkey1') objectStore.put(data, 'fkey1') objectStore.delete('fkey1')
索引
说到key就不得不说索引。
key是主键,每个store都有key,每条数据都有唯一的key与之关联,很多操作(如删除一条数据)就是通过key来进行的。key就是一个身份标识,是数据的“代表”。
索引是对数据的属性而言的,在indexDB中如果数据没有包含索引的字段,那么这个数据仍然能添加成功,只是不会出现在这个索引中,这是indexDB相对于MySQL这样的数据库的又一个区别,也是索引与key的一个区别!
索引可以是唯一的,也可以不是。key必须是唯一。
可以有复合索引,集合索引(multiEntry配置)等高级用法。【参考】
很多文章都将二者混为一谈,简单的认为主键就是一个唯一索引,但这时错误的。记住key是数据的代表,索引只是数据的属性相关,明白这一点你才能更好的设计!
indexDB的异常
异常一:indexDB权限被异常阻止。
用户可以选择禁用indexDB,这么有用的科技为什么要禁用?
One of the main design goals of IndexedDB is to allow large amounts of data to be stored for offline use. Obviously, browsers do not want to allow some advertising network or malicious( [məˈlɪʃəs] 恶意的) website to pollute(污染) your computer, so browsers used to prompt the user the first time any given web app attempts to open an IndexedDB for storage.
异常二:浏览器被关闭(异常的或认为的):
浏览器随时可能被关闭,所以理论上任何事务都是没法保证其完成,任何事务都有可能被abort!
有些很坑的产品经理,经常提一些在浏览器关闭前做一些事的需求。在浏览器关闭前做一些事是不可取的,官方也表明onbeforeunload、onunload这类事件仅仅建议给出提示而已。
对于这样的需求,也许需要你更好的去理解需求本质。比如“页面关闭前,保存表单”,你可以将其做成“一旦用户修改表单,就缓存起来”!总之,在浏览器关闭前去操作数据库是不可取的!
异常三:存放数据的磁盘文件不可用
磁盘文件被异常删除,数据过多导致超出上限无法继续添加数据。
参考:indexDB存储规范
当以上三种异常发生时,就会进行以下处理:
1,所有受影响的事务都会产生AbortError,就和调用IDBTransaction.abort() 相同。
2,所有事务完成或abort后,连接关闭(相当于db.close())
3,DB就会收到一个onclose事件,你可以通过监听它,来提示用户。
为了识别出这些异常,监听db的close事件,是非常重要的

