Hadoop Archives(HDFS文件归档)
Hadoop Archives Guide (HDFS文件归档)
一.简介:
Hadoop Archives 是特殊的归档格式,一个 Hadoop archives对应一个文件系统目录。
hadoop Archives 的扩展名是*.har。
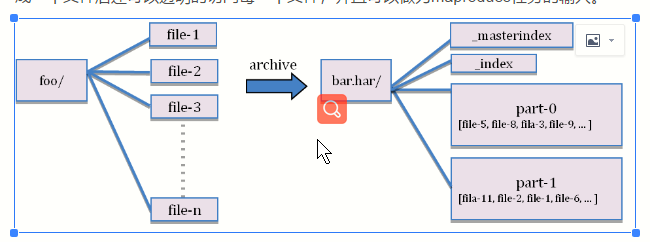
Hadoop Archives 包含元数据(形式是_index和_masterindex)和数据(part-*)文件。
index 文件包含了归档文件的文件名和位置信息。
二.应用场景:
HDFS可能保存大量小文件,NameNode占用大量内存。需要把小文件合并。
hdfs中可能保存大量小文件(当然不产生小文件是最佳实践),这样会把namenode 的namespace搞的很大。namespace保存着hdfs文件的inode信息,文件越多需要的namenode内存越大,但内存毕竟是有限的(这个是目前hadoop的硬伤)。
三.下面图片展示了,har文档的结构。har文件是通过mapreduce生成的,job结束后源文件不会删除。
hdfs并不擅长存储小文件,因为每个文件最少占用一个block,每个block的元数据都会在namenode节点占用内存,如果存在这样大量的小文件,它们会吃掉namenode节点的大量内存。
hadoop Archives可以有效的处理以上问题,他可以把多个文件归档成为一个文件,归档成一个文件后还可以透明的访问每一个文件,并且可以做为mapreduce任务的输入
四.优缺点分析
Hadoop archive 唯一的优势可能就是将众多的小文件打包成一个har 文件了,那这个文件就会按照dfs.block.size 的大小进行分块,因为hdfs为每个块的元数据大小大约为150个字节,如果众多小文件的存在(什么是小文件内,就是小于dfs.block.size 大小的文件,这样每个文件就是一个block)占用大量的namenode 堆内存空间,打成har 文件可以大大降低namenode 守护节点的内存压力。但对于MapReduce 来说起不到任何作用,因为har文件就相当一个目录,仍然不能讲小文件合并到一个split中去,一个小文件一个split ,任然是低效的,这里要说一点<<hadoop 权威指南 中文版>>对这个翻译有问题,上面说可以分配到一个split中去,但是低效的。
五.删除与恢复:
hdfs文件被归档后,系统不会自动删除源文件,需要手动删除。
hadoop fs -rmr /user/hadoop/xxx/201310/*.*.* 正则表达式来删除的,大家根据自己的需求删除原始文件
有人说了,我删了,归档文件存在,源文件不在了,如果要恢复怎么办,其实这也很简单,直接从har 文件中 cp出来就可以了。
hadoop fs -cp /user/xxx/201310/201310.har/* /user/hadoop/xxx/201310/
六.如何创建:
英文:
Usage: hadoop archive -archiveName name -p <parent> <src>* <dest>
-archiveName is the name of the archive you would like to create. An example would be foo.har. The name should have a *.har extension. The parent argument is to specify the relative path to which the files should be archived to. Example would be :
-p /foo/bar a/b/c e/f/g
Here /foo/bar is the parent path and a/b/c, e/f/g are relative paths to parent. Note that this is a Map/Reduce job that creates the archives. You would need a map reduce cluster to run this. For a detailed example the later sections.
If you just want to archive a single directory /foo/bar then you can just use
hadoop archive -archiveName zoo.har -p /foo/bar /outputdir
译文:由-archiveName选项指定你要创建的archive的名字。比如foo.har。archive的名字的扩展名应该是*.har。输入是文件系统的路径名,路径名的格式和平时的表达方式一样。创建的archive会保存到目标目录下。注意创建archives是一个Map/Reduce job。你应该在map reduce集群上运行这个命令。下面是一个例子:
hadoop archive -archiveName test_save_foo.har -p /foo/bar a/b/c e/f/g /user/outputdir/
以上是将/foo/bar文件夹下面的a/b/c和e/f/g两个目录的内容压缩归档到/user/outputdir/文件夹下,并且源文件不会被更改或者删除。注意,路径a/b/c 和e/f/g都是/foo/bar 的子文件夹
以下写法是错误的。
hadoop archive -archiveName test_save_foo.har -p /foo/bar/a/b/c /foo/bar/e/f/g /user/outputdir/
报错如下:
source path /foo/bar/a/b/c is not relative to /foo/bar/e/f/g
生成HAR文件:
har命令说明
参数“-p”为src path的前缀,src可以写多个path
archive -archiveName NAME -p <parent path> <src>* <dest>
1)、单个src文件夹
hadoop archive -archiveName test_save_foo.har -p /foo/bar/ 419 /user/outputdir/
2)、多个src文件夹
hadoop archive -archiveName test_save_foo.har -p /foo/bar/ 419 510 /user/outputdir/
3)、不指定src path,直接归档parent path(本例为“ /foo/bar/20120116/ ”, “ /user/outputdir ”仍然为输出path),这招是从源码里翻出来的。
hadoop archive -archiveName test_save_foo.har -p /foo/bar/ /user/outputdir/
4)、 使用模式匹配的src path,下面的示例归档10、11、12月文件夹的数据。这招也是从源码发出来的。
hadoop archive -archiveName combine.har -p /foo/bar/2011 1[0-2] /user/outputdir/
七、如何查看
英文:
The archive exposes itself as a file system layer. So all the fs shell commands in the archives work but with a different URI. Also, note that archives are immutable. So, rename's, deletes and creates return an error. URI for Hadoop Archives is
har://scheme-hostname:port/archivepath/fileinarchive
If no scheme is provided it assumes the underlying filesystem. In that case the URI would look like
har:///archivepath/fileinarchive
译文:
archive作为文件系统层暴露给外界。所以所有的fs shell命令都能在archive上运行,但是要使用不同的URI。 另外,archive是不可改变的。所以重命名,删除和创建都会返回错误。Hadoop Archives 的URI是
har://scheme-hostname:port/archivepath/fileinarchive
如果没提供scheme-hostname,它会使用默认的文件系统。这种情况下URI是这种形式
har:///archivepath/fileinarchive
这是一个archive的例子。archive的输入是/dir。这个dir目录包含文件filea,fileb。 把/dir归档到/user/hadoop/foo.bar的命令是
hadoop archive -archiveName foo.har /dir /user/hadoop
获得创建的archive中的文件列表,使用命令
hadoop dfs -lsr har:///user/hadoop/foo.har
查看archive中的filea文件的命令-
hadoop dfs -cat har:///user/hadoop/foo.har/dir/filea
八、如何在MapReduce程序中使用Hadoop Archives(归档)文件
英文:Using Hadoop Archives in MapReduce is as easy as specifying a different input filesystem than the default file system. If you have a hadoop archive stored in HDFS in /user/zoo/foo.har then for using this archive for MapReduce input, all you need to specify the input directory as har:///user/zoo/foo.har. Since Hadoop Archives is exposed as a file system MapReduce will be able to use all the logical input files in Hadoop Archives as input.
译文:在MapReduce中,与输入数据 使用默认文件系统一样,也可以使用Hadoop Archives(归档)文件作为输入文件系统。如果你有存储在HDFS目录下/user/zoo/foo.har的Hadoop Archives(归档)文件 ,然后你在MapReduce程序中就可以使用如下路径har:///user/zoo/foo.har作为输入文件。
由于Hadoop Archives(归档)文件是作为一种文件类型,MapReduce将能够使用Hadoop Archives(归档)文件中的所有逻辑输入文件作为输入源。
九、给出示例
1)原文示例:
英文:
@1)Creating an Archive
hadoop archive -archiveName foo.har -p /user/hadoop dir1 dir2 /user/zoo
The above example is creating an archive using /user/hadoop as the relative archive directory. The directories /user/hadoop/dir1 and /user/hadoop/dir2 will be archived in the following file system directory -- /user/zoo/foo.har. Archiving does not delete the input files. If you want to delete the input files after creating the archives (to reduce namespace), you will have to do it on your own.
@2)Looking Up Files
Looking up files in hadoop archives is as easy as doing an ls on the filesystem. After you have archived the directories /user/hadoop/dir1 and /user/hadoop/dir2 as in the example above, to see all the files in the archives you can just run:
hadoop dfs -lsr har:///user/zoo/foo.har/
To understand the significance of the -p argument, lets go through the above example again. If you just do an ls (not lsr) on the hadoop archive using
hadoop dfs -ls har:///user/zoo/foo.har
The output should be:
har:///user/zoo/foo.har/dir1 har:///user/zoo/foo.har/dir2
As you can recall the archives were created with the following command
hadoop archive -archiveName foo.har -p /user/hadoop dir1 dir2 /user/zoo
If we were to change the command to:
hadoop archive -archiveName foo.har -p /user/ hadoop/dir1 hadoop/dir2 /user/zoo
then a ls on the hadoop archive using
hadoop dfs -ls har:///user/zoo/foo.har
would give you
har:///user/zoo/foo.har/hadoop/dir1 har:///user/zoo/foo.har/hadoop/dir2
Notice that the archived files have been archived relative to /user/ rather than /user/hadoop
十. 实际操作
(1)开始归档
[pluto@hadoop01 tools]$ hadoop archive -archiveName /hartest1.har -p /hartext /hartext1
21/03/18 21:19:56 INFO mapreduce.JobSubmitter: number of splits:1
21/03/18 21:19:56 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1616033470495_0002
21/03/18 21:19:57 INFO impl.YarnClientImpl: Submitted application application_1616033470495_0002
21/03/18 21:19:57 INFO mapreduce.Job: The url to track the job: http://hadoop01:8088/proxy/application_1616033470495_0002/
21/03/18 21:19:57 INFO mapreduce.Job: Running job: job_1616033470495_0002
21/03/18 21:20:34 INFO mapreduce.Job: Job job_1616033470495_0002 running in uber mode : false
21/03/18 21:20:34 INFO mapreduce.Job: map 0% reduce 0%
21/03/18 21:21:10 INFO mapreduce.Job: map 100% reduce 0%
21/03/18 21:21:23 INFO mapreduce.Job: map 100% reduce 100%
21/03/18 21:21:24 INFO mapreduce.Job: Job job_1616033470495_0002 completed successfully
21/03/18 21:21:24 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=280
FILE: Number of bytes written=244529
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=453
HDFS: Number of bytes written=288
HDFS: Number of read operations=19
HDFS: Number of large read operations=0
HDFS: Number of write operations=7
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Other local map tasks=1
Total time spent by all maps in occupied slots (ms)=33564
Total time spent by all reduces in occupied slots (ms)=20786
Total time spent by all map tasks (ms)=33564
Total time spent by all reduce tasks (ms)=10393
Total vcore-seconds taken by all map tasks=33564
Total vcore-seconds taken by all reduce tasks=10393
Total megabyte-seconds taken by all map tasks=51554304
Total megabyte-seconds taken by all reduce tasks=31927296
Map-Reduce Framework
Map input records=4
Map output records=4
Map output bytes=266
Map output materialized bytes=280
Input split bytes=117
Combine input records=0
Combine output records=0
Reduce input groups=4
Reduce shuffle bytes=280
Reduce input records=4
Reduce output records=0
Spilled Records=8
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=1112
CPU time spent (ms)=4740
Physical memory (bytes) snapshot=461152256
Virtual memory (bytes) snapshot=7755964416
Total committed heap usage (bytes)=343932928
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=321
File Output Format Counters
Bytes Written=0
(2)查看压缩文件的组成结构:
[pluto@hadoop01 tools]$ hdfs dfs -ls /hartest1.har
Found 4 items
-rw-r--r-- 3 pluto supergroup 0 2021-03-18 21:21 /hartest1.har/_SUCCESS
-rw-r--r-- 5 pluto supergroup 250 2021-03-18 21:21 /hartest1.har/_index
-rw-r--r-- 5 pluto supergroup 23 2021-03-18 21:21 /hartest1.har/_masterindex
-rw-r--r-- 3 pluto supergroup 15 2021-03-18 21:21 /hartest1.har/part-0
[pluto@hadoop01 tools]$ hdfs dfs -cat /hartest1.har/part-0
dd
dsd
das
asf
(3)使用hdfs文件系统查看har文件目录内容
[pluto@hadoop01 tools]$ hadoop dfs -ls har:///hartest1.har/*
DEPRECATED: Use of this script to execute hdfs command is deprecated.
Instead use the hdfs command for it.
21/03/18 21:47:14 WARN hdfs.DFSClient: DFSInputStream has been closed already
-rw-r--r-- 3 pluto supergroup 7 2021-03-18 21:16 har:///hartest1.har/a.txt
-rw-r--r-- 3 pluto supergroup 4 2021-03-18 21:16 har:///hartest1.har/b.txt
-rw-r--r-- 3 pluto supergroup 4 2021-03-18 21:16 har:///hartest1.har/c.txt
(4)使用hdfs文件系统查看har文件具体的内容
[pluto@hadoop01 tools]$ hadoop dfs -cat har:///hartest1.har/*
DEPRECATED: Use of this script to execute hdfs command is deprecated.
Instead use the hdfs command for it.
21/03/18 21:48:12 WARN hdfs.DFSClient: DFSInputStream has been closed already
dd
dsd
das
asf
(5)Hadoop Archive解档
既然归档了就需要有解档的操作,可以使用hadoop distcp命令完成,具体操作如下:
[pluto@hadoop01 tools]$ hadoop distcp har:/hartest1.har /hartext
har:/hartest1:.har har的文件位置
/hartext : 到哪里去
21/03/18 22:06:54 INFO tools.DistCp: Input Options: DistCpOptions{atomicCommit=false, syncFolder=false, deleteMissing=false, ignoreFailures=false, maxMaps=20, sslConfigurationFile='null', copyStrategy='uniformsize', sourceFileListing=null, sourcePaths=[har:/hartest1.har], targetPath=/hartext, targetPathExists=true, preserveRawXattrs=false}
21/03/18 22:06:54 WARN hdfs.DFSClient: DFSInputStream has been closed already
21/03/18 22:06:55 INFO Configuration.deprecation: io.sort.mb is deprecated. Instead, use mapreduce.task.io.sort.mb
21/03/18 22:06:55 INFO Configuration.deprecation: io.sort.factor is deprecated. Instead, use mapreduce.task.io.sort.factor
21/03/18 22:06:55 INFO mapreduce.JobSubmitter: number of splits:4
21/03/18 22:06:55 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1616033470495_0003
21/03/18 22:06:55 INFO impl.YarnClientImpl: Submitted application application_1616033470495_0003
21/03/18 22:06:55 INFO mapreduce.Job: The url to track the job: http://hadoop01:8088/proxy/application_1616033470495_0003/
21/03/18 22:06:55 INFO tools.DistCp: DistCp job-id: job_1616033470495_0003
21/03/18 22:06:55 INFO mapreduce.Job: Running job: job_1616033470495_0003
21/03/18 22:07:41 INFO mapreduce.Job: Job job_1616033470495_0003 running in uber mode : false
21/03/18 22:07:41 INFO mapreduce.Job: map 0% reduce 0%
21/03/18 22:08:34 INFO mapreduce.Job: map 25% reduce 0%
21/03/18 22:08:37 INFO mapreduce.Job: map 50% reduce 0%
21/03/18 22:08:39 INFO mapreduce.Job: map 100% reduce 0%
21/03/18 22:08:39 INFO mapreduce.Job: Job job_1616033470495_0003 completed successfully
21/03/18 22:08:40 INFO mapreduce.Job: Counters: 33
File System Counters
FILE: Number of bytes read=0
FILE: Number of bytes written=492708
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=2999
HDFS: Number of bytes written=15
HDFS: Number of read operations=124
HDFS: Number of large read operations=0
HDFS: Number of write operations=16
Job Counters
Launched map tasks=4
Other local map tasks=4
Total time spent by all maps in occupied slots (ms)=215959
Total time spent by all reduces in occupied slots (ms)=0
Total time spent by all map tasks (ms)=215959
Total vcore-seconds taken by all map tasks=215959
Total megabyte-seconds taken by all map tasks=221142016
Map-Reduce Framework
Map input records=4
Map output records=0
Input split bytes=540
Spilled Records=0
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=3577
CPU time spent (ms)=3350
Physical memory (bytes) snapshot=760733696
Virtual memory (bytes) snapshot=12149698560
Total committed heap usage (bytes)=597164032
File Input Format Counters
Bytes Read=1352
File Output Format Counters
Bytes Written=0
org.apache.hadoop.tools.mapred.CopyMapper$Counter
BYTESCOPIED=15
BYTESEXPECTED=15
COPY=4
[pluto@hadoop01 tools]$ hdfs dfs -ls /hartext
Found 1 items
drwxr-xr-x - pluto supergroup 0 2021-03-18 22:08 /hartext/hartest1.har
[pluto@hadoop01 tools]$ hdfs dfs -ls /hartext/hartest1.har
Found 3 items
-rw-r--r-- 3 pluto supergroup 7 2021-03-18 22:08 /hartext/hartest1.har/a.txt
-rw-r--r-- 3 pluto supergroup 4 2021-03-18 22:08 /hartext/hartest1.har/b.txt
-rw-r--r-- 3 pluto supergroup 4 2021-03-18 22:08 /hartext/hartest1.har/c.txt
参考:https://blog.csdn.net/helloxiaozhe/article/details/79159799
本文来自博客园,作者:zhuzhu&you,转载请注明原文链接:https://www.cnblogs.com/zhuzhu-you/p/14556319.html

