
OpenMP初探
OpenMP支持c、cpp、fortran,本文对比使用openmp和未使用openmp的效率差距和外在表现,然后讲解基础知识。
一、举例
1、使用OpenMP与未使用OpenMP的比较。
OpenMP是使用多线程的接口。
以c语言程序举例,即ba.c文件如下:
#include <omp.h> #include <stdio.h> #include <stdlib.h> #include <windows.h> void Test(int n) { int j; for (int i = 0; i < 100000000; ++i) { //do nothing, just waste time j++; } printf("%d, ", n); } int main(int argc, char *argv[]) { int i; #pragma omp parallel for for (i = 0; i < 100; ++i) Test(i); system("pause"); return 1; }
在编译时,参数如下:

编译结果如下:

耗时:9s
注意:我的电脑为双核,所以开启了4个线程分别运行。
接下来,我通过window + R,输入msconfig,并进入boot中的高级设置,将我电脑的设置为单核,然后再运行同样的程序,可以发现结果如下:

于是可以发现,再设置为单核之后,程序会创建两个线程,这样的结果就是从0 50开始划分,这样显然是没有充分利用cpu的,所以将电脑设置为原来的双核。
未优化的如下:
// #include <omp.h> #include <stdio.h> #include <stdlib.h> #include <windows.h> void Test(int n) { int j; for (int i = 0; i < 100000000; ++i) { //do nothing, just waste time j++; } printf("%d, ", n); } int main(int argc, char *argv[]) { int i; // #pragma omp parallel for for (i = 0; i < 100; ++i) Test(i); system("pause"); return 1; }
在编译时,参数如下:
编译结果如下:

耗时: 24s
不难得知,此程序使用的为单核单线程 ,所以运行速度远远低于使用多核多线程的速度。
上面输出了100个数字,时间上来说优化后是未优化的3倍。
然后后续我又输出了1000个数字,未优化的时间为240s,而优化后的时间为84s,可见优化后同样也是优化前的3倍左右。
之所以四个线程的速度仅仅是单线程速度的3倍而不是4倍,这是因为多线程在线程的切换、合作等方面也需要花费一定的时间,所以只是到了3倍的差距,而没有达到4倍的差距。
2、获取当前线程id、获取总的线程数
#include <omp.h> #include <stdio.h> #include <stdlib.h> #include <windows.h> int main(int argc, char *argv[]) { int nthreads,tid; // fork a team of thread #pragma omp parallel private(nthreads,tid) { //obtian and print thread id tid=omp_get_thread_num(); printf("Hello Word from OMP thread %d\n",tid); // only master thread does this; if(tid==0) { nthreads = omp_get_num_threads(); printf("Number of thread: %d\n",nthreads); } } system("pause"); return 1; }
编译条件如下:

运行结果如下:
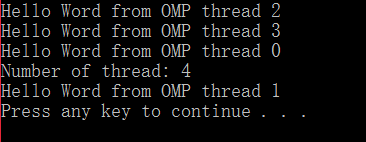
每次运行,可以发现顺序是不同的。但是Number of thread: 4永远是在线程0之后出现,并且tid==0时的这个线程为主线程。
3、之前使用的为c语言,下面改写为c++。
#include <omp.h> #include <iostream> #include <windows.h> using namespace std; void Test(int n) { int j; for (int i = 0; i < 100000000; ++i) { //do nothing, just waste time j++; } cout << n << " "; } int main(int argc, char *argv[]) { int i; #pragma omp parallel for for (i = 0; i < 100; ++i) Test(i); system("pause"); return 1; }
编译条件为 g++ t.cpp -o t -fopenmp,结果如下:

同样地,这里使用四核来生成的。
4、如下所示,也是使用c++语言。
#include <iostream> #include <windows.h> #include <omp.h> using namespace std; void test(int m) { int i = 0; double a = 0.0; double b = 0.0; double c = 0.0; for (i = 0; i < 100000000; i++) { a += 0.1; b += 0.2; c = a + b; } cout << m << " "; } int main() { #pragma omp parallel for for (int i = 0; i < 200; i++) { test(i); } system("pause"); return 0; }
在这里也没有什么很大的区别,总之,我们就是需要将void test这个函数写的复杂一些,然后就会耗时,这样才能看出来变化。
另外,在这里,我们可以看到结果中,是对for循环进行等量的划分,比如对于i从0到200的for循环里,会根据我电脑的2核划分为0 - 50、 51-100、 101-150、 151-200这几个区间,然后使用多核cpu进行运算,这个优化的效果我想是非常惊人的。
5、三层循环
#include <iostream> #include <windows.h> #include <omp.h> using namespace std; void test(int m, int n, int l) { int i = 0; double a = 0.0; double b = 0.0; double c = 0.0; for (i = 0; i < 100000000; i++) { a += 0.1; b += 0.2; c = a + b; } cout << m << " " << n << " " << l << endl; } int main() { cout << "first" << endl; #pragma omp parallel for for (int i = 0; i < 5; i++) { for (int j = 0; j < 5; j++) { for (int k = 0; k < 5; k++) { test(i, j, k); } } } cout << "over hah" << endl; cout << "over hah" << endl; cout << "over hah" << endl; cout << "over hah" << endl; cout << "over hah" << endl; cout << "over hah" << endl; cout << "over hah" << endl; cout << "over hah" << endl; cout << "over hah" << endl; cout << "over hah" << endl; cout << "over hah" << endl; cout << "over hah" << endl; cout << "over hah" << endl; cout << "second" << endl; #pragma omp parallel for for (int i = 0; i < 5; i++) { for (int j = 0; j < 5; j++) { for (int k = 0; k < 5; k++) { test(i, j, k); } } } system("pause"); return 0; }
结果,
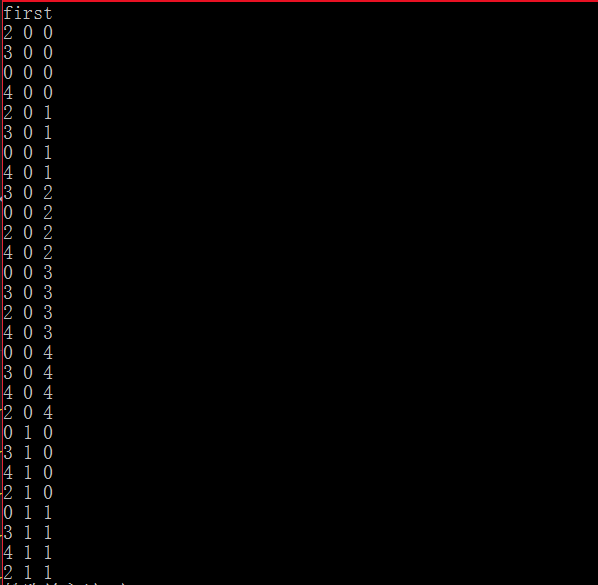
可以看到,还是最外层的循环进行转化。
耗时: 45s。
如果我们将上面的两个#pragma openmp parallel for去掉,再进行试验。注意#pragma是预编译指令,比如这里告诉编译器要进行并行运算。
则需要100s左右。虽然没有特别明显的提高,但是还是快了很多,优势是非常明显的。
上面的举例都是一些简单的例子,而对于具体的项目还会遇到问题,需要灵活应变。
二、基础
需要使用openmp就需要引入omp.h库文件。然后在编译时添加参数 -fopenmp即可。 在具体需要进行并行运算的部分,使用 #pragma omp 指令[子句] 来告诉编译器如何并行执行对应的语句。 常用的指令如下:
- parallel - 即#pragma omp parallel 后面需要有一个代码片段,使用{}括起来,表示会被并行执行。
- parallel for - 这里后面跟for语句即可,不需要有额外的代码块。
- sections
- parallel sections
- single - 表示只能单线程执行
- critical - 临界区,表示每次只能有一个openmp线程进入
- barrier - 用于并行域内代码的线程同步,线程执行到barrier时停下来 ,直到所有线程都执行到barrier时才继续。
常用的子句如下:
- num_threads - 指定并行域内线程的数目
- shared - 指定一个或者多个变量为多个线程的共享变量
- private - 指定一个变量或者多个变量在每个线程中都有它的副本
另外,openmp还提供了一些列的api函数来获取并行线程的状态或控制并行线程的行为,常用api如下:
- omp_in_parallel - 判断当前是否在并行域中。
- omp_get_thread_num - 获取线程号
- omp_set_num_threads - 设置并行域中线程格式
- omp_get_num_threads - 返回并行域中线程数
- omp_get_dynamic - 判断是否支持动态改变线程数目
- omp_get_max_threads - 获取并行域中可用的最大的并行线程数目
- omp_get_num_procs - 返回系统中处理器的个数
1、如下使用parallel,会根据电脑配置并行执行多次。
#include <iostream> #include <windows.h> #include <omp.h> using namespace std; int main() { #pragma omp parallel { cout << "this is in parallel" << endl; } system("pause"); return 0; }
2、使用parallel num_threads(3),限制并行的线程数为3。
#include <iostream> #include <windows.h> #include <omp.h> using namespace std; int main() { #pragma omp parallel num_threads(3) { cout << "this is in parallel" << endl; } system("pause"); return 0; }
这样,最终会输出3个语句,因为语句被并行运行了3次。结果如下:
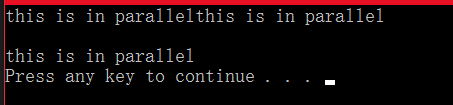
但是上面的结果不是固定的,这里可以很明显的表示出程序是并行运行的,因为第一个输出还没来得及换行,第二个又继续输出了,所以它们是独立地并行地运算的。
3、下面我们使用 #pragma parallel for num_threads(4),并且在并行域中,我们还通过 omp_get_thread_num()来获取线程号,如下:
#include <iostream> #include <windows.h> #include <omp.h> using namespace std; int main() { #pragma omp parallel for num_threads(4) for (int i = 0; i < 20; i++) { cout << omp_get_thread_num() << endl; } system("pause"); return 0; }
这里就是对这个for循环使用4个线程来并行。 注意 #pragma omp parallel for num_threads(4) 与 #pragma omp parallel num_threads(4) 不同,可自行体会。
结果如下,出现空行是因为多线程并行运算,导致换行符没来得及输出另外一个线程号就被输出了。

4、对比单线程、2线程、4线程、...... 、12线程效率。
#include <iostream> #include <windows.h> #include <omp.h> using namespace std; void test() { int j = 0; for (int i = 0; i < 100000; i++) { // do something to kill time... j++; } }; int main() { double startTime; double endTime; // 不使用openMp startTime = omp_get_wtime(); for (int i = 0; i < 100000; i++) { test(); } endTime = omp_get_wtime(); cout << "single thread cost time: " << endTime - startTime << endl; // 2个线程 startTime = omp_get_wtime(); #pragma omp parallel for num_threads(2) for (int i = 0; i < 100000; i++) { test(); } endTime = omp_get_wtime(); cout << "2 threads cost time: " << endTime - startTime << endl; // 4个线程 startTime = omp_get_wtime(); #pragma omp parallel for num_threads(4) for (int i = 0; i < 100000; i++) { test(); } endTime = omp_get_wtime(); cout << "4 threads cost time: " << endTime - startTime << endl; // 6个线程 startTime = omp_get_wtime(); #pragma omp parallel for num_threads(6) for (int i = 0; i < 100000; i++) { test(); } endTime = omp_get_wtime(); cout << "6 threads cost time: " << endTime - startTime << endl; // 8个线程 startTime = omp_get_wtime(); #pragma omp parallel for num_threads(8) for (int i = 0; i < 100000; i++) { test(); } endTime = omp_get_wtime(); cout << "8 threads cost time: " << endTime - startTime << endl; // 10个线程 startTime = omp_get_wtime(); #pragma omp parallel for num_threads(10) for (int i = 0; i < 100000; i++) { test(); } endTime = omp_get_wtime(); cout << "10 threads cost time: " << endTime - startTime << endl; // 12个线程 startTime = omp_get_wtime(); #pragma omp parallel for num_threads(12) for (int i = 0; i < 100000; i++) { test(); } endTime = omp_get_wtime(); cout << "12 threads cost time: " << endTime - startTime << endl; system("pause"); return 0; }
结果如下:
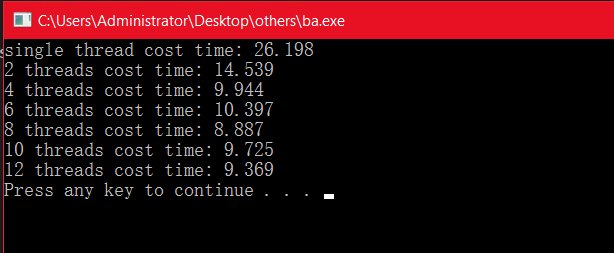
于是,我们可以看到,单线程(不使用openMP)时消耗时间最长,2线程约为单线程的一半,4个线程(本电脑为4个逻辑内核)约为1/3时间,6个线程的时候时间甚至更长,12个线程在时间上也没有明显额减少,所以,线程数的制定可以根据电脑的核心数来做出选择。
更多例子:
#include <iostream> #include <windows.h> #include <omp.h> using namespace std; void test(int i) { int j = 0; for (int i = 0; i < 100000000; i++) { // do something to kill time... j++; } cout << i << endl; }; int main() { // 此程序中使用到的openmp不可简单地理解为一个封装起来的库,实际上应该理解为一个框架。这个框架是由硬件开发商和软件开发商共同开发的,即通过协商api,来使得多核并行运算更容易上手、使用 // 主要参考文章:https://wdxtub.com/2016/03/20/openmp-guide/ // #pragma omp parallel for // for (int i = 0; i != 10; i++) { // test(i); // } // #pragma omp parallel // { // #pragma omp for // for (int i = 0; i < 10; i++) { // test(i); // } // } // XXX 错误,对于并行运算,不支持 != 的形式 // #pragma omp parallel for // for (int i = 0; i != 10; i++) { // test(i); // } // 在并行区域内声明了一个变量private_a,那么在多线程执行时,每个线程都会创建这么一个private_a变量。 // 最终输出结果为668/668/669/669,说明2个线程加了两次,2个线程加了3次。 // #pragma omp parallel // { // int private_a = 666; // #pragma omp for // for (int i = 0; i < 10; i++) { // test(i); // private_a++; // } // cout << private_a << endl; // } // 在并行区域之外定义的变量是共享的,即使下面有多个线程并行执行for循环,但是不会为每个线程创建share_a变量,所以最终每个线程访问的都是同一个内存,输出的结果为4个676 // int share_a = 666; // #pragma omp parallel // { // #pragma omp for // for (int i = 0; i < 10; i++) { // test(i); // share_a++; // } // cout << share_a << endl; // } // 注意:这种循环是普通的循环,其中的sum是共享的,然后sum是累加的,所以从结果中也可以看出sum一定是非递减的,最终结果为45。 // int sum = 0; // cout << "Before: " << sum << endl; // #pragma omp parallel for // for (int i = 0; i < 10; i++) { // sum = sum + i; // cout << sum << endl; // } // cout << "After: " << sum << endl; // 注意:这里采用了reduction(+:sum),所以每个线程根据reduction(+:sum)的声明计算出自己的sum(注意:在每个线程计算之初,sum均为在并行域之外规定的0,即对于4个线程而言,4个线程都会有一个初始值为0的sum,然后再叠加),然后再将各个线程的sum添加起来,所以从结果来看,sum是不存在某种特定规律的。 // int sum = 0; // cout << "Before: " << sum << endl; // #pragma omp parallel for reduction(+:sum) // for (int i = 0; i < 10; i++) { // sum = sum + i; // cout << sum << endl; // } // cout << "After: " << sum << endl; // 下面的减法是类似的,对比上面的两个例子即可。 // int sum = 100; // cout << "Before: " << sum << endl; // #pragma omp parallel for // for (int i = 0; i < 10; i++) { // sum = sum - i; // cout << sum << endl; // } // cout << "After: " << sum << endl; // int sum = 100; // cout << "Before: " << sum << endl; // #pragma omp parallel for reduction(-:sum) // for (int i = 0; i < 10; i++) { // sum = sum - i; // cout << sum << endl; // } // cout << "After: " << sum << endl; // 下面的两个例子中一个使用了原子操作,一个没有使用原子操作。 // 使用原子操作的最后结果正确且稳定,而没有使用原子操作最终的结果是不稳定的。 // int sum = 0; // cout << "Before: " << sum << endl; // #pragma omp parallel for // for (int i = 0; i < 20000; i++) { // #pragma omp atomic // sum++; // } // cout << "Atomic-After: " << sum << endl; // int sum = 0; // #pragma omp parallel for // for (int i = 0; i < 20000; i++) { // sum++; // } // cout << "None-atomic-After: " << sum << endl; // 线程同步之critical // 使用critical得到的结果是稳定的,而不使用critical得到的结果是不稳定的。 // 值得注意的是:critical与atomic的区别在于 - atomic仅仅使用自增(++、--等)或者简化(+=、-=等)两种方式, // 并且只能表示下一句,而critical却没有限制,且可以通过{}代码块来表示多句同时只能有一个线程来访问。 // int sum = 0; // cout << "Before: " << sum << endl; // #pragma omp parallel for // for (int i = 0; i < 100; i++) { // #pragma omp critical(a) // { // sum = sum + i; // sum = sum + i * 2; // } // } // cout << "After: " << sum << endl; // 同时运行下面的两个程序,可以发现有些许不同。 // 这个程序中的第一个for循环会多线程执行,并且如果一个线程执行完,如果有的线程没有执行完, // 那么就会等到所有线程执行完了再继续向下执行。所以结果中 - 和 + 区分清晰。 // #pragma omp parallel // { // #pragma omp for // for (int j = 666; j < 1000; j++) { // cout << "-" << endl; // } // #pragma omp for nowait // for (int i = 0; i < 100; i++) { // cout << "+" << endl; // } // } // 这个程序中的第一个for循环同样会有多个线程同时执行,只是其中某个线程最先执行完了之后, // 不会等其他的线程,而是直接进入了下一个for循环,所以结果中的 - 和 + 在中间部分是混杂的。 // #pragma omp parallel // { // #pragma omp for nowait // for (int i = 0; i < 100; i++) { // cout << "+" << endl; // } // #pragma omp for // for (int j = 666; j < 1000; j++) { // cout << "-" << endl; // } // } // // 可知,barrier为隐式栅障,即并行区域中所有线程执行完毕之后,主线程才继续执行。 // 而nowait的声明即可取消栅障,这样,即使并行区域内即使所有的线程还没有执行完, // 但是执行完了的线程也不必等待所有线程执行结束,而可自动向下执行。 // 如下所示正常来说应该是第一个for循环中的一个线程执行完之后nowait进入下一个for循环, // 但是我们通过 #pragma omp barrier 来作为显示同步栅障,即让这个先执行完的线程等待所有线程执行完毕再进行下面的运算 // #pragma omp parallel // { // #pragma omp for nowait // for (int i = 0; i < 100; i++) { // cout << "+" << endl; // } // #pragma omp barrier // #pragma omp for // for (int j = 666; j < 1000; j++) { // cout << "-" << endl; // } // } // 这里我们通过#pragma omp master来让主线程执行for循环,然后其他的线程执行后面的cout语句, // 所以,cout的内容会出现在for循环多次(这取决于你电脑的性能),最后,主线程执行完for语句后,也会执行一次cout // #pragma omp parallel // { // #pragma omp master // { // for (int i = 0; i < 10; i++) { // cout << i << endl; // } // } // cout << "This will be shown two or more times" << endl; // } // 使用section可以指定不同的线程来执行不同的部分 // 如下所示,通过#pragma omp parallel sections来指定不同的section由不同的线程执行 // 最后得到的结果是多个for循环是混杂在一起的 // #pragma omp parallel sections // { // #pragma omp section // for (int i = 0; i < 10; i++) { // cout << "+"; // } // #pragma omp section // for (int j = 0; j < 10; j++) { // cout << "-"; // } // #pragma omp section // for (int k = 0; k < 10; k++) { // cout << "*"; // } // } system("pause"); return 0; }
通过上面的例子,我们就可以对OpenMP有一个基本的入门过程了。

