
python应用
GUI(图形用户界面)
python是可以创建GUI的,使用第三方库一般是Tk、wxWidgets、Qt、GTK。 而python自带的是支持Tk的Tkinter,我们这里就来用Tkinter来实现GUI。 其中Tkinter内置了访问Tk的接口。Tk是一个图形库,支持多个操作系统,使用Tcl语言开发,Tk会调用本地操作系统提供的GUI接口,完成最终的GUI。
举例如下:
from tkinter import * class Application(Frame): def __init__(self, master=None): Frame.__init__(self, master) self.pack() self.createWidgets() def createWidgets(self): self.helloLabel = Label(self, text='Hello world!') self.helloLabel.pack() self.quitButton = Button(self, text='Quit', command=self.quit) self.quitButton.pack() app = Application() app.master.title('Hello world!') app.mainloop()
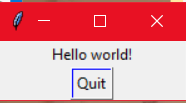
注意,这里我们需要引入tkinter的所有方法,所以是from tkinter import *, 然后创建一个Application类,__init__方法用于创建widgets。而在createWidgets中,我们创建了一个label和一个button,且button的名称是Quit,点击后就会推出程序,运行文件后,效果如下所示:
另外,我们还可以对这个GUI程序改进一下,让用户输入文字,然后点击按钮之后弹出对话框,如下:
from tkinter import * import tkinter.messagebox as messagebox class Application(Frame): def __init__(self, master=None): Frame.__init__(self, master) self.pack() self.createWidgets() def createWidgets(self): self.nameInput = Entry(self) #用户输入内容作为nameInput的值 self.nameInput.pack() #pack是打包的意思,实际上就是绑定、生效 self.alertButton = Button(self, text='Hello', command=self.hello) self.alertButton.pack() #可以看到,每次我们创建一个Lable或者Input或者alertButton时,需要pack def hello(self): name = self.nameInput.get() or 'world' messagebox.showinfo('Message', 'Hello, %s' % name) app = Application() app.master.title('Hello world!') app.mainloop()
如上所示。 下面,我们还可以做一个计算机,计算两数字之和,如下所示:
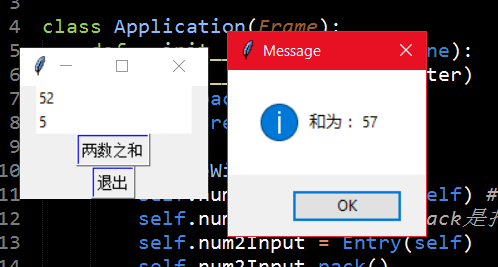
from tkinter import * import tkinter.messagebox as messagebox class Application(Frame): def __init__(self, master=None): Frame.__init__(self, master) self.pack() self.createWidgets() def createWidgets(self): self.num1Input = Entry(self) #用户输入内容作为numInput的值 self.num1Input.pack() #pack是打包的意思,实际上就是绑定、生效 self.num2Input = Entry(self) self.num2Input.pack() self.alertButton = Button(self, text='两数之和', command=self.calc) self.alertButton.pack() #可以看到,每次我们创建一个Lable或者Input或者alertButton时,需要pack self.quitButton = Button(self, text='退出', command=self.quit) self.quitButton.pack() def calc(self): num1 = int(self.num1Input.get()) or 0 num2 = int(self.num2Input.get()) or 0 messagebox.showinfo('Message', '和为: %s' % (num1 + num2)) app = Application() app.master.title('求两数之和') app.mainloop()
from tkinter import * import tkinter.messagebox as messagebox class Application(Frame): def __init__(self, master=None): Frame.__init__(self, master) self.pack() self.createWidgets() def createWidgets(self): self.num1Input = Entry(self) #用户输入内容作为numInput的值 self.num1Input.pack() #pack是打包的意思,实际上就是绑定、生效 self.num2Input = Entry(self) self.num2Input.pack() self.alertButton = Button(self, text='两数之和', command=self.calc) self.alertButton.pack() #可以看到,每次我们创建一个Lable或者Input或者alertButton时,需要pack self.quitButton = Button(self, text='退出', command=self.quit) self.quitButton.pack() def calc(self): num1 = int(self.num1Input.get()) or 0 num2 = int(self.num2Input.get()) or 0 messagebox.showinfo('Message', '和为: %s' % (num1 + num2)) app = Application() app.master.title('求两数之和') app.mainloop()
结果如下:
电子邮件
电子邮件的历史比web要久,直到现在,email也是非常常用的。几乎所有的编程语言都支持发送和接受电子邮件。
那么电子邮件如何发送呢?比如我的邮件时me@163.com,对方的时friend@sina.com,我们用Outlook或者Foxmail之类的软件写好邮件,填上对方的Email地址,点“发送”,电子邮件就发送出去了。这些电子邮件是MUA:Mail User Agent --- 邮件用户代理。Email从MUA发送出去,不是直接到达对方电脑,而是发到MTA:Mail Transfer Agent --- 邮件传输代理,就是那些Email服务提供商,比如网易、新浪等。 由于我们自己的电子邮件时163.com,所以Email首先被投递到网易提供的MTA,再由网易的MTA发送到对方的服务商,就是新浪的MTA,这个过程可能还会经过别的MTA,但是我们不关心具体路线,只关心速度。Email到达新浪的MTA后,会把邮件投递到目的地MDA : Mail Delivery Agent --- 邮件投递代理。 email到达MDA后,就会存储在新浪服务器的数据库里,这个长期保存邮件的地方是电子邮件。 同普通邮件类似,Emial不会直接到达对方的电脑,因为对方电脑不一定开机,开机也不一定联网。对方要收到邮件,必须通过MUA从MDA上把邮件取到自己的电脑上。
因此:
发件人 -> MUA -> MTA -> MTA -> 若干个MTA -> MDA <- MUA <- 收件人
有了上述基本概念,所以编写程序来收发邮件,就是:
-
编写MUA把邮件发到MTA;
-
编写MUA从MDA上收邮件
发邮件时,MUA和MTA使用的协议就是SMTP:Simple Mail Transfer Protocol,后面的MTA到另一个MTA也是用SMTP协议。
收邮件时,MUA和MDA使用的协议有两种:POP:Post Office Protocol,目前版本是3,俗称POP3;IMAP:Internet Message Access Protocol,目前版本是4,优点是不但能取邮件,还可以直接操作MDA上存储的邮件,比如从收件箱移到垃圾箱,等等。
在使用Python收发邮件前,请先准备好至少两个电子邮件,如xxx@163.com,xxx@sina.com,xxx@qq.com等,注意两个邮箱不要用同一家邮件服务商。
- MUA,邮件用户代理,这个在写邮件端和收邮件端都要有,代理用户的。
- MTA,邮件传输代理,写好邮件了,传输出去,一定要有MTA。
- MDA,邮件投递代理,写好邮件给对方的MDA,而对方如果要获取邮件,也要从MDA(邮件投递代理)那里去取。
SMTP发送邮件
SMTP是发送邮件的协议,而python内置对SMTP协议的支持,可以发送纯文本邮件、html邮件、附件邮件。
from email.mime.text import MIMEText msg = MIMEText('hello, I am wayne zhu', 'plain', 'utf-8') #邮件正文、MIME的subtype、utf-8 from_addr = input('From:') password = input('Password:') #输入收件人地址 to_addr = input('To: ') #输入SMTP服务器地址: smtp_server = input('SMTP server: ') import smtplib # server -> login -> send -> quit server = smtplib.SMTP(smtp_server, 25) #SMTP协议默认端口是25 server.set_debuglevel(1) #可以打印出和SMTP服务器交互的所有信息 server.login(from_addr, password) #登录SMTP服务器 server.sendmail(from_addr, [to_addr], msg.as_string()) #发送邮件 server.quit()
总之,使用python是可以使用内置的SMTP协议发送邮件的。
POP3收取邮件
POP3收取邮件也是非常容易的,即编写一个MUA作为客户端,然后从MDA把邮件获取到用户的电脑或者手机上。 收取邮件最常用的就是POP协议,目前版本为3,即POP3。
python内置了一个poplib模块,实现了pop3协议,可以直接用来收邮件。而收邮件可以分为两步:
第一: 用poplib把邮件的原始文本下载到本地。
第二: 用email解析原始文本,还原为邮件对象。
import poplib # 输入邮件地址, 口令和POP3服务器地址: email = input('Email: ') password = input('Password: ') pop3_server = input('POP3 server: ') # 连接到POP3服务器: server = poplib.POP3(pop3_server) # 可以打开或关闭调试信息: server.set_debuglevel(1) # 可选:打印POP3服务器的欢迎文字: print(server.getwelcome().decode('utf-8')) # 身份认证: server.user(email) server.pass_(password) # stat()返回邮件数量和占用空间: print('Messages: %s. Size: %s' % server.stat()) # list()返回所有邮件的编号: resp, mails, octets = server.list() # 可以查看返回的列表类似[b'1 82923', b'2 2184', ...] print(mails) # 获取最新一封邮件, 注意索引号从1开始: index = len(mails) resp, lines, octets = server.retr(index) # lines存储了邮件的原始文本的每一行, # 可以获得整个邮件的原始文本: msg_content = b'\r\n'.join(lines).decode('utf-8') # 稍后解析出邮件: msg = Parser().parsestr(msg_content) # 可以根据邮件索引号直接从服务器删除邮件: # server.dele(index) # 关闭连接: server.quit()
下面就解析邮件就可以了。不再赘述。
访问数据库
数据库用于存储数据,这对于任何应用都是不可或缺的。
而数据库一般可以分为关系型数据库(SQL)和非关系型数据库(NoSQL)。注意,本身来说SQL是结构化查询语言的意思,SQL是一种语言,但是很多情况下说SQL是关系型数据库,也可以说是一种语言,根据语境理解。
关系型数据库包括:
- Oracle数据库,付费,这是属于甲骨文公司的关系型数据库。尽管付费,Oracle数据库也是世界上占有率最高的关系型数据库。Oracle公司还是非常强大的,瑞典公司MYSQL创建了MYSQL,之后被sun公司收购,接着2009年Oracle公司又收购了sun公司,所以mySQL和oracle都是oracle的。 另外,sun公司下java的版权现在也是数据Oracle的。
- SQL Server数据库,付费, 是微软推出的关系型数据库,和.net框架配套使用。
- DB2数据库,付费,是IBM公司开发的数据库。
- MySQL数据库。免费。因为是开源的,所以被广泛应用
- PostgreSQL数据库,免费,也非常不错,但是知名度不如MySQL。
- sqlite数据库,免费,嵌入式数据库,适合桌面和移动应用。其他细节会在下面具体说。
非关系型数据库,其实并不是我们字面上理解的非关系型数据库,实际上NoSQL的全称不是not SQL,而是 not only sql,即不仅仅是关系型数据库, 所以nosql的功能一般更为强大一些,效率更高一些。
- mongodb。开源,mognodb是Mongodb公司开发的开源数据库,该公司美国上市,原名叫做10gen,市值在20亿美元左右。
- redis。开源。k-v非关系型数据库。
使用SQLite数据库
SQLite是一种嵌入式数据库,适合桌面和移动应用,他的数据库是一个文件,本身用C写的,体积很小,且python中就内置了SQLite,所以,在python中使用SQLite,不需要安装任何东西,直接使用。
众所周知,微信在后台服务器中不保存聊天记录,微信在移动客户端所有的聊天记录都会存在嵌入式数据库SQLite中,一旦这个数据库损坏,将会丢失用户多年的聊天记录。而腾讯监控到现网的损坏率是0.02%,也就是没1w个数据库就会有2个遇到数据库损坏。考虑到这么庞大的用户基数,如果是10亿,那么就有20万个用户数据库损坏,且之前微信的官方修复方法,修复成功率只有30%,损坏率高,修复率低。 而损坏的主要原因就是空间不足、设备断电、文件sync失败,需要一一优化。
优化空间占用 。 微信朋友圈会自动删除7天前缓存的图片。但是总的来说对文件空间的使用缺乏一个全局把握。所以,业务文件需要先申请后使用、每个业务文件都要申明有效期,过期文件就会被自动清理。而对于微信之外的占用空间,比如相册、视频、其他app的空间占用,微信本身是做不了什么工作的,只能提示用户进行空间清理。
优化文件sync。第一:synchronous = Full, 设置SQLite的文件同步机制为全同步,也要求每个事物的写操作是真的flush到文件里去了。第二:fullfsync = 1,即微信团队与苹果工程师交流之后发现ios平台下还有fullfsync这个选项,可以严格保证吸入顺序和提交顺序一致,设备开发商为了测评数据好看,往往会对提交的数据重排,再统一写入,即写入顺序和app提交顺序不一致。但在某些情况下比如断电会导致不一致。
优化效果。优化之后,微信团队使得损坏率降低了一半多。
但是微信团队在后台是否保留了聊天记录我还是存疑的,但是即使保留,应该也是定期会清理的,比如只保留最近一到两年的。
注意:表是数据库中存放关系数据的集合,一个数据库中包含多个表,表和表之间使用外键链接,要操作关系数据库,首先要连接到数据库,一个数据库链接成为Connection; 链接到数据库之后,需要打开游标,称之为Cursor,通过Cursor执行SQL语句,然后,获得执行结果 。
# 导入SQLite驱动: >>> import sqlite3 # 连接到SQLite数据库 # 数据库文件是test.db # 如果文件不存在,会自动在当前目录创建: >>> conn = sqlite3.connect('test.db') # 创建一个Cursor: >>> cursor = conn.cursor() # 执行一条SQL语句,创建user表: >>> cursor.execute('create table user (id varchar(20) primary key, name varchar(20))') <sqlite3.Cursor object at 0x10f8aa260> # 继续执行一条SQL语句,插入一条记录: >>> cursor.execute('insert into user (id, name) values (\'1\', \'Michael\')') <sqlite3.Cursor object at 0x10f8aa260> # 通过rowcount获得插入的行数: >>> cursor.rowcount 1 # 关闭Cursor: >>> cursor.close() # 提交事务: >>> conn.commit() # 关闭Connection: >>> conn.close()
接下来,我们可以试着查询记录:
>>> conn = sqlite3.connect('test.db') >>> cursor = conn.cursor() # 执行查询语句: >>> cursor.execute('select * from user where id=?', ('1',)) <sqlite3.Cursor object at 0x10f8aa340> # 获得查询结果集: >>> values = cursor.fetchall() >>> values [('1', 'Michael')] >>> cursor.close() >>> conn.close()
- 即首先引入sqlite3,然后connection,接着获取到cursor,最后就可以通过cursor.execute()接受的第一个SQL语句进行数据库操作了,常见的操作有insert、update、delete,或者通过select查询到之后使用fetchall获取,最后一定要记得通过close关闭,先关闭cursor,然后再关闭conn。
- 在使用cursor.execute()的select查询时,我们可以使用?作为占位符,第二个参数是一个tuple即可。
使用MySQL
之前使用的SQLite的特点是轻量级、可嵌入,但是不能承受高并发访问,适合桌面和移动应用。 而MySQL是为服务器端设计的数据库,能承受高并发访问,同时占用的内存也远远大于SQLite。
嵌入式我们听得很多,那嵌入式究竟是什么呢?为什么说SQLite是嵌入式的呢?
因为嵌入式值得是把软件(代码)直接烧录在硬件里(不需要从外部获取),而不是安装在外部存储介质上。比如SQLite就是把数据库文件直接存在本地,而不是从服务器端获取,所以是嵌入式的。
由于MySQL服务器以独立的进程运行,并通过网络对外服务,所以,需要支持python的MySQL驱动来链接到MySQL服务器。 MySQL官方提供了mysql-connector-python驱动,但是安装的时候需要给pip命令加上参数 --allow-external:
pip install mysql-connector-python --allow-external mysql-connector-python
下面,我们就可以连接到MySQL服务器的test数据库:
# 导入MySQL驱动: >>> import mysql.connector # 注意把password设为你的root口令: >>> conn = mysql.connector.connect(user='root', password='password', database='test') >>> cursor = conn.cursor() # 创建user表: >>> cursor.execute('create table user (id varchar(20) primary key, name varchar(20))') # 插入一行记录,注意MySQL的占位符是%s: >>> cursor.execute('insert into user (id, name) values (%s, %s)', ['1', 'Michael']) >>> cursor.rowcount 1 # 提交事务: >>> conn.commit() >>> cursor.close() # 运行查询: >>> cursor = conn.cursor() >>> cursor.execute('select * from user where id = %s', ('1',)) >>> values = cursor.fetchall() >>> values [('1', 'Michael')] # 关闭Cursor和Connection: >>> cursor.close() True >>> conn.close()
可以看到,对于MySQL的链接还是和SQLite是类似的,引入mysql.connector之后,就可以使用用户名、密码连接到到指定的数据库,然后获得cursor,最后就可以使用cursor.execute来执行相关的SQL语句了。
注意:在执行insert操作之后要使用commit()提交事务。
使用SQLAlchemy
数据库是一个二维表,如下所示:
[ ('1', 'Michael'), ('2', 'Bob'), ('3', 'Adam') ]
我们还可以通过下面的class实例很容易的看出结构:
class User(object): def __init__(self, id, name): self.id = id self.name = name [ User('1', 'Michael'), User('2', 'Bob'), User('3', 'Adam') ]
这就是ORM技术了,即Object-Relational Mapping,对象关系映射,可以把关系数据库的表结构映射到对象上,即ORM将数据库中的表与面向对象语言中的类建立了一种对应关系。
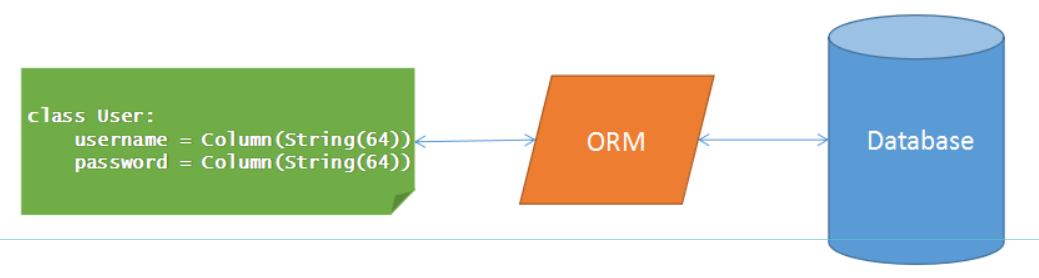
SQLAlchemy是python社区最为知名的ORM工具之一,为高效和高性能的数据库访问设计,实现了完整的企业级持久模型。
首先,我们通过pip安装:
pip install sqlalchemy
然后,利用上次我们在MySQL上的test数据库中创建的user表,用SQLAlchemy来试一试:
第一步,导入SQLAlchemy,并初始化DBSession:
# 导入: from sqlalchemy import Column, String, create_engine from sqlalchemy.orm import sessionmaker from sqlalchemy.ext.declarative import declarative_base # 创建对象的基类: Base = declarative_base() # 定义User对象: class User(Base): # 表的名字: __tablename__ = 'user' # 表的结构: id = Column(String(20), primary_key=True) name = Column(String(20)) # 初始化数据库连接: engine = create_engine('mysql+mysqlconnector://root:password@localhost:3306/test') # 创建DBSession类型: DBSession = sessionmaker(bind=engine)
以上代码完成SQLAlchemy的初始化和具体每个表的class定义。如果有多个表,就继续定义其他class,例如School:
class School(Base): __tablename__ = 'school' id = ... name = ...
。。。。
ORM框架的作用就是把数据库表的一行记录与一个对象互相做自动转换。 而正确使用ORM的前提是了解关系数据库的原理。
WEB开发
最早的软件是运行在大型机上的,软件使用者通过哑终端登录到大型机上去运行软件,后来PC机的兴起,软件开始运行在桌面上,而数据库这样的软件运行在服务器上,这种Clinet/Server模式成为C/S架构。
随着互联网的兴起,人们发现,CS架构不适合Web,最大的原因是桌面app的升级非常麻烦,需要用户重新下载,而浏览器上的web应用程序只要服务器端改变就改变了,升级非常迅速,因此,Browser/Server模式开始流行,简称为B/S架构。
python的诞生历史比web还要早,且由于python是一种解释型的脚本原因,开发效率高,所以非常适合做web开发。
WSGI接口
因为BS架构的实质就是浏览器发送一个http请求,然后用一个现成的HTTP服务器来接受用户请求,从文件中读取html并返回,Apache、Nginx、Lighttpd等这些常见的静态服务器就是干这件事的。
而我们使用python怎么办呢?难道要自己封装http请求、TCP链接等这些基础的任务吗? 不是的! 为了我们专心使用python编写web业务,python内置了接口: WSGI --- web server gateway interface。通过这个接口,我们就可以很容易的使用python做后台编写web业务了。
定义如下所示:
def application(environ, start_response): start_response('200 OK', [('Content-Type', 'text/html')]) return [b'<h1>Hello, web!</h1>']
如上所示的application就是一个web处理函数,它接受两个参数:
- environ: 一个包含所有HTTP请求的dict对象;
- start_response:一个发送HTTP响应的函数。
当然,一个web处理函数,当然要先接受http请求的相关信息,然后再进行http响应,有了请求和响应,就可以构成一个服务器的web处理函数了。
而application中start_response函数的调用也接受了两个参数:
- 第一个参数是一个字符串:HTTP响应码
- 第二个参数是一个list,list中有tuple,这个tuple是HTTP header,而这里的Content-Type是非常常用的header,当然还有其他的header需要传入。
最后,return了一个字符串,这个就做为了http响应的body发送给了浏览器。
如上所示,application函数接受了http请求作为参数,解析之后,可以发出http响应,即包含响应头和body。这样,使用python的wsgi就可以轻易的完成http请求和响应了,而不需要接触底层的代码。
但是,这个application()函数如何调用呢? 还要传入environ参数和start_response函数,这个我们怎么写呢?一般应该是服务器调用的啊。 好消息是python内置了一个wsgi服务器,这个模块叫做wsgiref,它是纯python编写的wsgi服务器的参考实现,所谓‘参考实现’是指完全符合wsgi标准,但是不考虑任何运行效率,进攻开发和测试使用。
运行wsgi服务
ok,我们先编写foo.py,如下:
def application(environ, start_response): start_response('200 OK', [('Content-Type', 'text/html')]) return [b'<h1>Hello, web!</h1>']
接下来就是引入wsgi服务器模块,然后着手搭建一个服务器并调用上面的处理函数,如下为server.py:
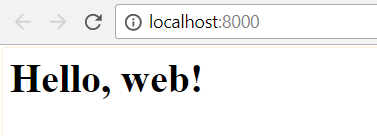
# server.py # 从wsgiref模块导入 from wsgiref.simple_server import make_server #导入之前编写的application函数 from foo import application #创建http服务器,ip地址为空(通过localhost访问),端口是8000,处理函数是application http = make_server('', 8000, application) print('Serving HTTP on port 8000...') #开始监听HTTP请求 http.serve_forever()
如上,运行这个server.py文件之后,我们就可以在浏览器localhost:8000打开了,如下:
注意:但我们在命令行中输入 python server.py时,只是打开了服务器,因为没有请求,所以application函数没有调用,而一旦在浏览器中输入localhost:8000,这个application函数才会处理http请求,然后做出响应。
当然,如果我们还可以从environ中读取到更多的信息,比如,我们将foo.py中的application函数中添加代码如下:
for i,j in environ.items(): print(i,j)
这样,在启动服务器然后进行请求之后,就会打印出environ这个请求dict的具体条目,如下我选取了一些常用的:
SERVER_PORT 8000 SERVER_PROTOCOL HTTP/1.1 REQUEST_METHOD GET PATH_INFO / QUERY_STRING REMOTE_ADDR 127.0.0.1 CONTENT_TYPE text/plain HTTP_HOST localhost:8000 HTTP_CONNECTION keep-alive HTTP_CACHE_CONTROL max-age=0 HTTP_USER_AGENT Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36 HTTP_ACCEPT text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8 HTTP_ACCEPT_ENCODING gzip, deflate, br HTTP_ACCEPT_LANGUAGE zh-CN,zh;q=0.9,en;q=0.8 HTTP_COOKIE _ga=GA1.1.239236614.1512745292 wsgi.run_once False
如上,包括服务器端口号8000、http协议使用的版本1.1、请求方法get、PATH_INFO /(即loacalhost之后的path)、QUERY_STRING查询字符串、远程地址、CONTENT_TYPE、HTTP_HOST等等都是请求中非常重要的参数。
所以,对于application,我们也可以写的更为复杂一些:
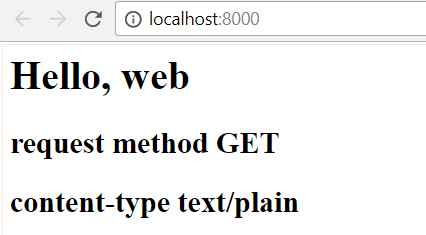
def application(environ, start_response): start_response('200 OK', [('Content-Type', 'text/html')]) body = '<h1>Hello, %s</h1>' % (environ['PATH_INFO'][1:] or 'web') body = body + '<h2> request method %s </h2>' % (environ['REQUEST_METHOD'] or 'get') body = body + '<h2> content-type %s' % (environ['CONTENT_TYPE']) return [body.encode('utf-8')]
如上所示,字符串可以使用 + 来进行拼接,最后的结果如下:
使用web框架
使用web框架比使用wsgi更抽象,写起来逻辑更清楚,效率更高,而Flask框架就是这样的框架,它比较简单、轻量,我们首先安装Flask:
pip install flask
然后,写一个app.py,处理三个URL,分别是:
- GET /: 首页,返回Home
- GET /signin: 登录页,显示登录表单
- POST /signin: 处理登录表单,显示登录结果
代码如下所示:
from flask import Flask from flask import request app = Flask(__name__) @app.route('/', methods=['GET', 'POST']) def home(): return '<h1>Home</h1>' @app.route('/signin', methods=['GET']) def signin_form(): return '''<form action="/signin" method="post"> <p><input name="username"></p> <p><input name="password" type="password"></p> <p><button type="submit">Sign In</button></p> </form>''' @app.route('/signin', methods=['POST']) def signin(): if request.form['username'] == 'admin' and request.form['password'] == 'password': return '<h3>Hello, admin!</h3>' return '<h3>Bad username or password.</h3>' if __name__ == '__main__': app.run()
运行如下:
C:\Users\Administrator\Desktop>python app.py * Restarting with stat * Debugger is active! * Debugger PIN: 211-799-158 * Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)
然后我们在浏览器打开http://127.0.0.1:5000/即可,可以看到,使用flask框架之后,我们这里使用了装饰器,即高级函数,这样,我们使用route接受两个参数,第一个是PATH,第二个指定方法即可,接下来定义一个返回值。
并且,对于wsgi我们在修改代码之后需要重启服务器,而使用了flask框架之后,我们在修改代码之后服务器会自动重启更新。且flask制定了域名和端口,而不需要我们自行设定。
另外,flask将response的内容又进行了封装,而我们只需要写一些核心的函数即可。
另外,request即用户的请求对象,我们可以打印其中的一些结果:
@app.route('/', methods=['GET', 'POST']) def home(): print(request.method) print(request.host) print(request.headers) print(request.data) print(request.values) print(request.url) return '<h1>waynezhu</h1>'
在后台可以看到数据如下:
GET 127.0.0.1:5000 Host: 127.0.0.1:5000 Connection: keep-alive Cache-Control: max-age=0 Upgrade-Insecure-Requests: 1 User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8 Accept-Encoding: gzip, deflate, br Accept-Language: zh-CN,zh;q=0.9,en;q=0.8 b'' CombinedMultiDict([ImmutableMultiDict([]), ImmutableMultiDict([])]) http://127.0.0.1:5000/
注意:python是敏捷开发很好的语言,而java的开发就做不到python如此敏捷,因为java的开发量会比较大,难以做出迅速的改变,而python开发迅速,你可以在一两个小时就做出一个功能,这样对于创业型公司来说,需求更改频繁,使用python也可以很好的应付过来。
当然,Flask是非常流行,对初学者也是很友好的,但是还有其他的框架使用的也非常广泛,如下:
- Django:和Flask一样非常流行,但是Flask的特点是轻,Django的特点是重,比如自带了模板引擎等,所以Flask开发小项目比较合适,如果开发大项目也可以,但需要额外寻找一些功能库。而Django是自身就已经很完善了,学好之后我们就可以很好的运用在大型项目中。 就像vue和angular的区别。所以Django有很好的学习价值,只是不适合初学者学习,因为有太多的东西需要学习,一下子难以吸收。
- Tornado:传说中性能很高的框架。支持异步处理的功能,这是他的特点,其他框架没有。Tornado的设计更注重RESTful URL;数据库操作需要自己扩展,不支持ORM,快速开发比较吃力,如果要ORM支持,需要自己写一层将SQLlchemy和Tornado联系起来,知乎是使用Tornado开发的,而Quora也是。
- web.py:一个小巧的web框架。使用不多,不做更多介绍。
- Quixote:著名的豆瓣就是基于Quixote开发的,他的路由有些特别,但性能非常不错。
- Pyramid:在豆瓣的某些产品线上也是用了Pyramid框架,国内还有《码农周刊》在用这个框架,它是一个非常成熟的企业级别的web框架。其轻重适宜,在Django和Flask之间。
- Bottle:Bottle和Flask都属于轻量级的web框架,但是Bottle似乎没落了,也许跟他的api设计有关系,用起来也不是很顺手。
使用模板
HTML在大型网站中还是非常复杂的,如果都像之前的flask程序中那样返回html是不可取的,况且一般我们还需要大量的css和js,显然我们需要换一种方式来返回HTML文件。于是,模板就出现了。
使用模板,我们需要预先准备一个HTML文档,这个HTML文档不是普通HTML,而是嵌入了一些变量和命令,然后,根据我们传入的数据,替换后,就得到了最终的HTML,发送给用户:

这就是MVC的设计模式了,M就是model,即数据,比如这里替换的name就是数据; V是view,然后这个html模板就是view了,即展示在用户面前的;而C是controller,是控制器,即检查用户名是否存在、取出用户信息等。
那么使用了模板之后,我们就可以将之前的app.py加以修改了,下面使用到的render_template函数就是渲染模板,即将模板渲染为html文件并将其中的变量等加以替换。
from flask import Flask,request,render_template app = Flask(__name__) @app.route('/', methods=['GET', 'POST']) def home(): return render_template('home.html') @app.route('/signin', methods=['GET']) def signin_form(): return render_template('form.html') @app.route('/signin', methods=['POST']) def signin(): username = request.form['username'] password = request.form['password'] if username == 'admin' and password == 'password': return render_template('signin-ok.html', username=username) return render_template('form.html', message='Bad username or password', username=username) if __name__ == '__main__': app.run()
如上所示,我们就完成了改写,下面我们就要开始写模板了,在python中内置了jinja2模板,我们直接pip install jinja2即可,注意安装之后是不需要引入的,然后编写下面的模板。
home.html如下
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Home</title> </head> <body> <h1 style="font-style: italic">Home</h1> </body> </html>
form.html如下:
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Please Sign in</title> </head> <body> {% if message %} <p style="color: red">{{ message }}</p> {% endif %} <form action="/signin" method="post"> <legend>Please sign in:</legend> <p><input name="username" placeholder="username" value="{{ username }}" type="text"></p> <p><input name="password" placeholder="password" type="password"></p> <p><button type="submit">Sign In</button></p> </form> </body> </html>
可以看到jinja2的语法是使用{{}}来包含变量,并且其中的python代码使用{% %}来包含。
signin-ok.html如下:
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>success</title> </head> <body> <p>Welcome, {{ username }}</p> </body> </html>
这样,我们就可以python app.py运行并访问了!
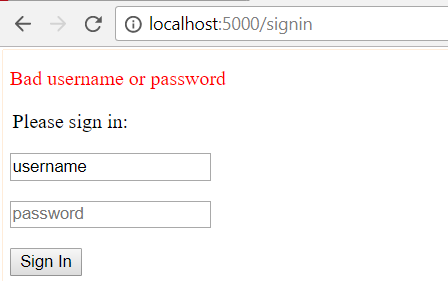
如上,如果登录失败,会提示登录失败,并且将之前的用户名保留,这是非常符合我们使用网站登录的习惯的。
异步IO
这个还是很好理解的,js、node中有很多异步io的例子。那么异步IO出现的原因是什么呢?
程序执行的过程中,往往会遇到IO的情况,比如网络请求、硬盘文件读取,而这些都是非常耗时的,在处理网络、文件读取这些IO操作的时候,CPU只能处于空闲状态,这样后面的代码也是无法执行的,只有等到IO结束,才能执行后面的代码。 为了解决这个问题,就有两种解决方式了:
- 第一:对于python、java这种可以设置多进程多线程的高级语言,就让某些线程专门去处理速度慢的IO,然后让一部分进程或线程去处理后续代码的计算。 这样,IO就不会阻塞了。但是如果进程或者线程多了,CPU在不同进程线程之间的切换也是非常耗时的,甚至得不偿失。于是,就有了下面这种方法。
- 第二:异步IO。 即进行IO操作时,我们不让CPU继续等待,而是直接执行后面的代码,但是要设置一个event_loop,当IO返回结果时通知cpu,cpu再去处理这个结果,这就是异步IO了,它可以很好地解决阻塞的问题。
协程
协程的概念早就出来了,英文名是Coroutine,只是最近几年才在Lua中得到广泛应用而被提起。
而在JavaScript中我们也是有协程的概念的,我的文章就有介绍。比如一个A函数和一个B函数,执行A函数到某个语句时,可能会突然停止,转向去执行B,然后B又执行了一段时间,又转向去执行A,但是A和B函数是独立的,并不是A中调用了B或者B中调用A,这就是协程,有有些像多线程,但协程不是多线程,因为协程的特点就是只有一个线程执行。
而协程优点:执行效率高于多线程,因为没有线程切换的开销,且与之比较的线程数量越多,协程的性能优势越明显。另外,协程是一个线程执行,所以不需要多线程的锁机制,不存在变量冲突的问题,只判断状态就好,所以执行效率比较高。
和JavaScript相同,Python中协程的实现也是通过generator实现的,在generator中,我们不但可以通过for循环来迭代,还可以不断调用next()函数获取由yield语句返回的下一个值。
def consumer(): r = '' while True: n = yield r if not n: return print('[CONSUMER] Consuming %s...' % n) r = '200 OK' def produce(c): c.send(None) n = 0 while n < 5: n = n + 1 print('[PRODUCER] Producing %s...' % n) r = c.send(n) print('[PRODUCER] Consumer return: %s' % r) c.close() c = consumer() produce(c)
如上所示,就是一个协程的例子,执行结果如下:
[PRODUCER] Producing 1... [CONSUMER] Consuming 1... [PRODUCER] Consumer return: 200 OK [PRODUCER] Producing 2... [CONSUMER] Consuming 2... [PRODUCER] Consumer return: 200 OK [PRODUCER] Producing 3... [CONSUMER] Consuming 3... [PRODUCER] Consumer return: 200 OK [PRODUCER] Producing 4... [CONSUMER] Consuming 4... [PRODUCER] Consumer return: 200 OK [PRODUCER] Producing 5... [CONSUMER] Consuming 5... [PRODUCER] Consumer return: 200 OK
这里的consumer函数是一个generator,把一个consumer传入produce之后:
-
首先调用
c.send(None)启动生成器;注意: send函数和next函数的作用是类似的。 -
然后,一旦生产了东西,通过
c.send(n)切换到consumer执行; -
consumer通过yield拿到消息,处理,又通过yield把结果传回; -
produce拿到consumer处理的结果,继续生产下一条消息; -
produce决定不生产了,通过c.close()关闭consumer,整个过程结束。
可以看到,一般,我们使用generator就可以轻易的实现一个协程了,并且,协程的执行过程也是非常容易理解的,就是在generator中的yield中断,到另外一个函数执行,另外一个函数执行到send的时候,就会再回到generator执行了,如此循环往复即可。
整个流程无锁,由一个线程执行,produce和consumer协作完成任务,所以称为“协程”,而非线程的抢占式多任务。
asyncio
asyncio是Python 3.4版本引入的,直接内置了对异步IO的支持,他的编程模型是一个消息循环,我们从asyncio模块中直接获取一个EventLoop的引用,然后把需要执行的协程扔到EventLoop中执行,就实现了异步IO。
import asyncio @asyncio.coroutine def hello(): print("Hello world!") # 异步调用asyncio.sleep(1): r = yield from asyncio.sleep(1) print("Hello again!") # 获取EventLoop: loop = asyncio.get_event_loop() # 执行coroutine loop.run_until_complete(hello()) loop.close()
@asyncio.coroutine把一个generator标记为coroutine类型,然后,我们就把这个coroutine扔到EventLoop中执行了,首先hello()打印出了Hello world!,然后yield from拿到返回值,然后接着执行下一句,asyncio.sleep(1)可以看成是一个耗时1秒的IO操作,这个过程中,主线程并没有等待,而是去执行EventLoop中其他可以执行的coroutine了,因此可以实现并发执行。
下面,我们可以用Task封装两个coroutine试一试:
import threading import asyncio @asyncio.coroutine def hello(num): print(num, 'Hello world! (%s)' % threading.currentThread()) #打印当前线程名称 yield from asyncio.sleep(1) print(num, 'Hello again! (%s)' % threading.currentThread()) loop = asyncio.get_event_loop() tasks = [hello(1), hello(2)] loop.run_until_complete(asyncio.wait(tasks)) loop.close() #注意:最后一定要关闭这个EventLoop
如上所示,我们引入了threading模块用来打印当前线程,用asyncio来方便实现协程并交由EventLoop,接着我们创建了一个tasks,最后开始执行,执行完毕,我们就需要关闭这个EventLoop,结果如下:
2 Hello world! (<_MainThread(MainThread, started 6536)>) 1 Hello world! (<_MainThread(MainThread, started 6536)>) 2 Hello again! (<_MainThread(MainThread, started 6536)>) 1 Hello again! (<_MainThread(MainThread, started 6536)>)
可以看到,我们传入的时1和2,但是在执行的时候却先执行的2后执行的1,然后2执行到yield的时候有一个IO操作,所以这时cpu并没有停下来,而是在EventLoop中找到了另外一个去执行,等到IO返回的时候,又回到了2去执行,之后又去执行1。 并且由于这是协程来实现的并发执行,所以可以看到两个 coroutine 都是由同一个进程并发执行的。所以,即使是把asyncio.sleep()替换成真正的IO操作,则多个coroutine就可以由一个线程并发执行了。
所以,我们可以看到asyncio提供了完善的异步IO支持; 异步操作需要在coroutine中通过yield from完成(即这个yield from 后面应当是一个IO操作,这个操作是费时的,且无需CPU),那么这时CPU就会去tasks中的其他任务使用,而使得CPU的利用更充分。当然,多个coroutine可以封装成一组Tasks然后并发执行。
async/await
用asyncio提供的@asyncio.coroutine可以把一个generator标记为coroutine(协程)类型,然后在coroutine内部用yield from低啊用另外一个coroutine实现异步操作。
而为了更好的标识异步IO,从python 3.5开始引入了新的语法async和await,可以让coroutine的代码更简洁易读。 注意: async和await是针对oroutine的新语法,本质没有变,要使用这个语法,需要做如下替换:
- 把@asyncio.couroutine换成async
- 把yield from换成await
而剩下的完全不变,我们对上面的例子做出修改,如下:
import threading import asyncio
async def hello(num): print(num, 'Hello world! (%s)' % threading.currentThread()) #打印当前线程名称 await asyncio.sleep(1) print(num, 'Hello again! (%s)' % threading.currentThread()) loop = asyncio.get_event_loop() tasks = [hello(1), hello(2)] loop.run_until_complete(asyncio.wait(tasks)) loop.close() #注意:最后一定要关闭这个EventLoop
如上所示,我们可以发现,使用了async/await之后代码更加简洁,最终的结果也是一致的。所以说,这里的async/await函数也是可以理解为协程了。另外,这个await的返回值是存在的,左边也可以有一个变量接受返回值,当然如果后面的式子没有指定返回值,那么返回值就是None了。
aiohttp (一种基于async的http框架)
asyncio可以实现单线程并发IO操作,如果仅仅用在客户端,发挥的威力不大,但把asyncio用在服务器端,例如web服务器,由于HTTP链接就是IO操作,因此可以用单线程+coroutine实现多用户的高并发支持。
asyncio实现了TCP、UDP、SSL等协议,aiohttp则是基于asyncio实现的http框架, aio 解释为 asyncio 的简称,http表示这是一种http框架。
如下,我们首先安装aiohttp:
pip install aiohttp
然后编写一个HTTP服务器,分别处理以下URL:
-
/- 首页返回b'<h1>Index</h1>'; -
/hello/{name}- 根据URL参数返回文本hello, %s!。
代码如下所示:
import asyncio from aiohttp import web async def index(request): await asyncio.sleep(0.5) return web.Response(body=b'<h1>Index</h1>') async def hello(request): await asyncio.sleep(0.5) text = '<h1>hello, %s!</h1>' % request.match_info['name'] return web.Response(body=text.encode('utf-8')) async def init(loop): app = web.Application(loop=loop) app.router.add_route('GET', '/', index) app.router.add_route('GET', '/hello/{name}', hello) srv = await loop.create_server(app.make_handler(), '127.0.0.1', 8000) print('Server started at http://127.0.0.1:8000...') return srv loop = asyncio.get_event_loop() loop.run_until_complete(init(loop)) loop.run_forever()
注意aiohttp的初始化函数init()也是一个coroutine,loop.create_server()则利用asyncio创建TCP服务。
可以看到,这就是web后台处理网络请求的代码了,对于IO来说,接收到一个请求,我们往往需要进入数据库,读取某些文件,然后再返回给前台,但是打开数据库,读取文件的这个过程是比较缓慢的,所以,这里使用了异步IO之后,我们就可以在打开数据库、读取文件的过程中使得这个线程处理其他程序,即把此时空闲的cpu交给其他程序使用,然后等到IO操作结束之后,我们就可以使得CPU继续在原来的程序工作,这样的异步IO操作就使得CPU的利用率很高,并且不会出现阻塞的情况了,同样的Nodejs的优点也是异步IO,这样也就解决了高并发的问题。

