
nodejs(三) --- nodejs进程与子进程
 嗯,对于node的学习还远远不够,这里先做一个简单的api的记录,后续深入学习。
嗯,对于node的学习还远远不够,这里先做一个简单的api的记录,后续深入学习。
第一部分:nodejs中的全局对象之process进程对象
在node中的全局对象是global,相当于浏览器中的window,而process进程对象是global的属性。
这一部分主要从 process中的事件、process中的标准流对象、process中的属性、process中的方法这四个方面来介绍,
1、process中的事件
process是EventEmitter的一个实例,所以也具有事件监听器的特征。 process中的事件监听器有 exit、 uncaughtException、一些signal。
(1)退出事件: ‘exit’
exit事件会在进程退出时触发,用来监听进程退出的状态。 在回调函数中会有一个进程退出的状态码。 如下:
process.on('exit', function(code) { // 进程退出后,其后的事件循环将会结束,计时器也不会被执行 setTimeout(function() { console.log('This will not run'); }, 0); console.log('进程退出码是:', code); }); //进程退出 process.exit(); //进程正常退出,其退出码为:0
(2)未处理异常: ‘uncaughtException’
当进程异常退出时,会触发‘uncaughtException’事件,但是这个异常一般并不明确,所以不建议使用。
//异常捕获 process.on('uncaughtException', function(exception) { console.log('捕获到的异常是:', exception); }); //一个未定义的方法,用来制造异常 nonexistentFunc(); //输出 捕获到的异常是: [ReferenceError: nonexistentFunc is not defined]
(3)信号相关事件
如SIGNIT事件,会在使用 ctrl + c的时候触发次信号:
process.stdin.resume(); //使用Control+C键,可以触发SIGINT信号 process.on('SIGINT', function() { console.log('收到SIGINT信号,按Control+D键可以退出进程'); });
2、process中的标准流对象
在Process中有三个标准流的操作,与stream流操作不同的是,Process中刘操作是阻塞的。
(1)标准输出流: process.stdout
这个输出流对象是一个指向标准输出流的可写流 writebal stream。 console.log就是通过 process.stdout 实现的,如下:
console.log = function(d) { process.stdout.write(d + '\n'); };
(2)标准输入流: process.stdin
这是一个指向标准输入流的可读流 readable stream。 标准输入流式暂停的,所以必须调用 process.stdin.resume()来恢复 resume 接受。 使用如下:
process.stdin.on('end', function() { process.stdout.write('end'); }); //一个读取输入流的方法 function gets(cb){ process.stdin.resume(); process.stdin.setEncoding('utf8'); process.stdin.on('data', function(chunk) { process.stdin.pause(); cb(chunk); }); } gets(function(reuslt){ console.log("["+reuslt+"]"); });
(3)标准错误流:process.stderr
标准错误流是一个可写流 writable stream。 console.error 就是通过 process.stderr实现的。
3、process中的属性
(1)进程命令行参数的数组: process.argv
这是一个当前进程折参数组,第一个参数是node,第二个参数是当前执行的.js文件名,之后是执行的参数列表。
例如,当前文件名是 process.js,代码如下:
process.argv.forEach(function(val, index, array) { console.log(index + ': ' + val); });
那么执行了 node process.js 之后,输出如下;
0: node 1: /Users/liuht/code/itbilu/demo/process.js
增加两个参数 node process.js arg1 arg2执行后,输出如下:
0: node 1: /Users/liuht/code/itbilu/demo/process.js 2: arg1 3: arg2
(2)启动进程程序的路径: process.execPath
中文意思就是process的执行路径。 这个属性会返回启动进程程序的路径,例如 node process.js会返回,/user/local/bin/node, 即node的安装路径。 process.js 的代码如下:
console.log(process.execPath);
(3)node的命令行参数: process.execArgv
process.argv不仅仅是命令行参数,还包括其他参数,而这里的process.execArgv就是Node的命令行参数数组。代码如下:
$ node --harmony script.js --version
那么 process.execArgv 返回:
['--harmony']
而 process.argv 返回:
['/usr/local/bin/node', 'script.js', '--version']
(4)node的运行环境对象: process.env
这个属性会返回用户的运行环境对象,如下所示:
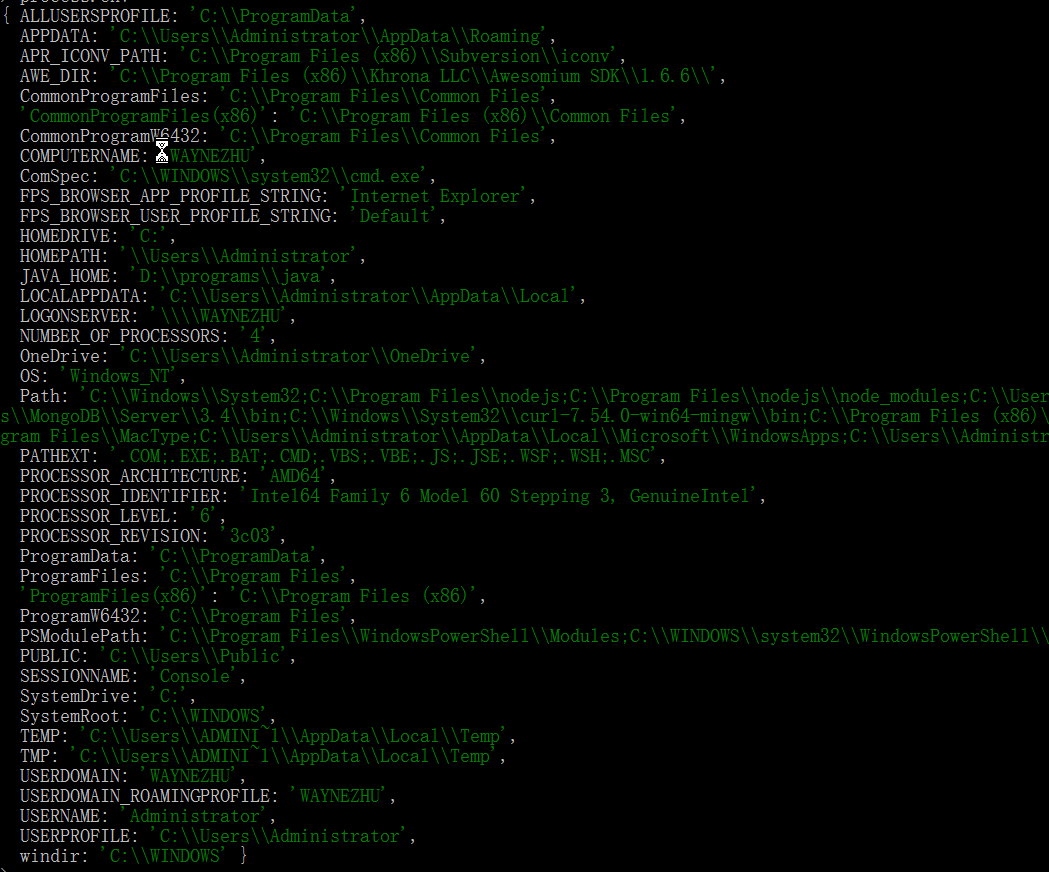
(5)进程退出码:process.exitCode
这个属性会返回进程默认的退出码, 或者process.exit(code)指定的退出码。
(6)node编译时的版本:process.version
这个属性会返回node编译时的版本号。
(7)node以及其依赖包版本信息: process.versions
这个属性返回node以及它所依赖的版本信息,如下:
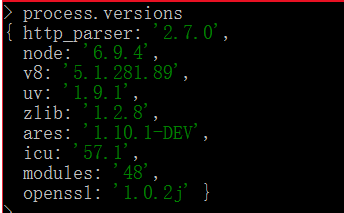
即node是基于v8的,这里也返回了v8引擎的信息,还有node本身、http_parser、uv、zlib、ares、icu、modules、openssl。
(8)node编译时的配置信息:process.config
即这个属性会返回配置信息,与运行./configure脚本生成的config.gypi文件相同。
(9)指向启动脚本的模块: process.mainModule
这个属性会返回指向启动脚本的模块,与require.mian类似。
(10)当前的进程ID:process.pid
返回当前node的进程id。
(11)ps中显示的进程名: process.title
process.title属性会返回‘ps’中显示的进程名。 实际上就是node的路径。
(12)当前CPU的架构: process.arch
如我的电脑显示 X64
(13)当前进程的运行平台: process.platform
该属性返回执行当前进程的运行平台信息。 如我的电脑返回的是win32。
4、process中的方法
(1)触发abort事件: process.abort()
该方法会使得当前node进程abort。
(2)终止当前进程: process.exit([code])
该方法会终止当前进程,可以接受一个退出状态的可选参数 code, 不传入时, 会返回表示成功的状态码 0 , 如下:
process.on('exit', function(code) { console.log('进程退出码是:%d', code); // 进程退出码是:1 }); process.exit(1);
(3)获取/设置进程的GID:process.getgid()、process.setuid(id)
有些系统不适用,不做讲解。
(4)获取/设置进程的UID:process.getuid()、process.setuid(id)
不做过多讲解。
GID为GroupId,即组ID,用来标识用户组的唯一标识符
UID为UserId,即用户ID,用来标识每个用户的唯一标示符
扩展:
用户组:将同一类用户设置为同一个组,如可将所有的系统管理员设置为admin组,便于分配权限,将某些重要的文件设置为所有admin组用户可以读写,这样可以进行权限分配。
每个用户都有一个唯一的用户id,每个用户组都有一个唯一的组id
(5)获取/设置单钱进程有操作权限的GID数组:process.getgroups()、process.setgroups(groups)
(6)初始化group分组访问列表: process.initgroups(user, extra_group)
(7)向指定进程发送一个信息: process.kill(pid[, signal])
process.kill()方法是用来向指定进程发送一个信号,需要注意的时 kill 方法不仅是用来杀死指定进程的,可以是任何POSIX标准信息。
(8)返回内存使用情况:process.memoryUsage()
该方法用于查看内存使用情况:如下;
{ rss: 23105536, heapTotal: 10522624, heapUsed: 5836208 }
(9)延迟方法执行: process.nextTick()
process.nextTick(callback[, arg][, ...])
该方法用于延迟回调函数的执行,nextTick方法会将callback中的回调函数延迟到事件循环的下一次循环中,与setTimeout(fn, 0)相比nextTick方法效率高很多,该方法能在任何I/O事件之前调用我们的回调函数:
(10)设置或者读取进程文件的权限掩码: process.umask([mask])
该方法用于设置或者读取进程文件的权限掩码,子进程从父进程中继承这个掩码。 如果设定了参数mask那么返回旧的掩码,否则返回当前的:
var oldmask, newmask = 0022; oldmask = process.umask(newmask); console.log('原掩码: ' + oldmask.toString(8) + '\n' '新掩码: ' + newmask.toString(8));
(11)返回当前的高精度时间:process.hrtime()
(12)返回node程序已经运行的秒数: process.uptime()
(13)工作目录切换: process.chdir(directory)、process.cwd()
process.chdir()用于改变进程的工作目录。 process.cwd() 方法返回进程当前的工作目录。 示例如下:
console.log('当前目录:' + process.cwd()); try { process.chdir('/tmp'); console.log('新目录:' + process.cwd()); } catch (err) { console.log('chdir: ' + err); } //输出如下 当前目录:/Users/liuht/code/itbilu/demo 新目录:/private/tmp
第二部分:nodejs中进程、线程、单线程理解
这一部分,首先介绍进程和线程,node单线程这些知识的理解,后面介绍如何创建多线程。
- 在开启电脑后,会运行浏览器,微信,视频等软件,然而cpu数量很少,所以使用的时并发的方式,即cpu给不同的进程分配时间片。
- 打开视频,不仅可以有画面,还有音频播放等等,其实是这些进程内的线程在起作用。 一个进程至少要有一个线程。
node和浏览器中的JavaScript都是单线程的。 但是,我们要理解node的单线程到底是什么意思?
实际上, 这里所说的单线程是指我们所编写的代码运行在单线程上,实际上node不是真正的单线程。
比如我们执行 node app.js 时启动了一个进程,但是这个进程并不是只有一个线程,而是同时创建了很多歌线程(比如:异步IO需要的一些IO线程)。
但是,仍然只有一个线程会运行我们编写的代码。 这就是node中单线程的含义。
但是node单线程会导致下面的问题:
- 无法利用多核CPU(只能获得一个CPU的时间分片)。
- 错误就会引起整个应用退出(整个应用就一个进程,挂了就挂了)。
- 大量计算长时间占用CPU,导致阻塞线程内的其他操作(异步IO发不出调用,已完成的异步IO回调不能及时执行)。
第三部分:nodejs子进程的创建方式
在node中,大体有三种创建进程的方法:
- exex / execFile
- spawn
- fork
exec/execFile
exec(command, options, callback) 和 execFile(file, args, options, callback) 比较类似,会使用一个 Buffer 来存储进程执行后的标准输出结果,他们可以一次性在callback里面获取到。不太适合数据量大的场景。
另外,exec会首先创建一个新的shell进程出来,然后执行command; execFile则是直接将可执行的file创建为新进程执行。 所以,execfile 会比 exec 高效一些(后者多了一个shell步骤,前者是直接拿到execfile就执行了)。
exec比较适合来执行 shell 命令, 然后获取输出(比如: exec('ps aux | grep "node" ')),但是 execFile 没有这么实用, 因为它实际上只接受了一个可执行的命令,然后执行(没法使用shell里面的管道之类的东西)。
// child.js console.log('child argv: ', process.argv);
// parent.js const child_process = require('child_process'); const p = child_process.exec( 'node child.js a b', // 执行的命令 {}, (err, stdout, stderr) => { if (err) { // err.code 是进程退出时的 exit code,非 0 都被认为错误 // err.signal 是结束进程时发送给它的信号值 console.log('err:', err, err.code, err.signal); } console.log('stdout:', stdout); console.log('stderr:', stderr); } ); console.log('child pid:', p.pid);
const p = child_process.execFile( 'node', // 可执行文件 ['child.js', 'a', 'b'], // 传递给命令的参数 {}, (err, stdout, stderr) => { if (err) { // err.code 是进程退出时的 exit code,非 0 都被认为错误 // err.signal 是结束进程时发送给它的信号值 console.log('err:', err, err.code, err.signal); } console.log('stdout:', stdout); console.log('stderr:', stderr); } ); console.log('child pid:', p.pid);
两个方法还可以传递一些配置项,如下所示:
{ // 可以指定命令在哪个目录执行 'cwd': null, // 传递环境变量,node 脚本可以通过 process.env 获取到 'env': {}, // 指定 stdout 输出的编码,默认用 utf8 编码为字符串(如果指定为 buffer,那 callback 的 stdout 参数将会是 Buffer) 'encoding': 'utf8', // 指定执行命令的 shell,默认是 /bin/sh(unix) 或者 cmd.exe(windows) 'shell': '', // kill 进程时发送的信号量 'killSignal': 'SIGTERM', // 子进程超时未执行完,向其发送 killSignal 指定的值来 kill 掉进程 'timeout': 0, // stdout、stderr 允许的最大输出大小(以 byte 为单位),如果超过了,子进程将被 kill 掉(发送 killSignal 值) 'maxBuffer': 200 * 1024, // 指定用户 id 'uid': 0, // 指定组 id 'gid': 0 }
spawn
spawn(command, args, options)适合用在进程的输入、输出数据量比较大的情况(因为它支持steam的方式,而刚才的exec/execFile都是Buffer,而不支持stream的方式), 可以用于任何命令。
// child.js console.log('child argv: ', process.argv); process.stdin.pipe(process.stdout);
// parent.js const p = child_process.spawn( 'node', // 需要执行的命令 ['child.js', 'a', 'b'], // 传递的参数 {} ); console.log('child pid:', p.pid); p.on('exit', code => { console.log('exit:', code); }); // 父进程的输入直接 pipe 给子进程(子进程可以通过 process.stdin 拿到) process.stdin.pipe(p.stdin); // 子进程的输出 pipe 给父进程的输出 p.stdout.pipe(process.stdout); /* 或者通过监听 data 事件来获取结果 var all = ''; p.stdout.on('data', data => { all += data; }); p.stdout.on('close', code => { console.log('close:', code); console.log('data:', all); }); */ // 子进程的错误输出 pipe 给父进程的错误输出 p.stderr.pipe(process.stderr);
我们可以执行 cat bigdata.txt | node parent.js 来进行测试,bigdata.txt 文件的内容将被打印到终端。
spawn 方法的配置(options)如下:
{ // 可以指定命令在哪个目录执行 'cwd': null, // 传递环境变量,node 脚本可以通过 process.env 获取到 'env': {}, // 配置子进程的 IO 'stdio': 'pipe', // 为子进程独立运行做好准备 'detached': false, // 指定用户 id 'uid': 0, // 指定组 id 'gid': 0 }
fork
fork(modulePath, args, options)实际上是spawn的一个“特例”, 会创建一个新的V8实例。新创建的进程只能用来运行node脚本,不能运行其他命令。
// child.js console.log('child argv: ', process.argv); process.stdin.pipe(process.stdout);
// parent.js const p = child_process.fork( 'child.js', // 需要执行的脚本路径 ['a', 'b'], // 传递的参数 {} ); console.log('child pid:', p.pid); p.on('exit', code => { console.log('exit:', code); });
总结:
- exec/execFile: 使用Buffer来存储进程的输出,可以在回调函数中获取输出结果,不太适合数据量大的情况,可以执行任何命令; 不创建V8实例。
- spawn: 支持stream方式操作输入输出,适合数据量打的情况; 可以执行任何命令; 不创建v8实例; 可以创建常驻的后台进程。
- fork: spawn的一个特例; 只能执行node脚本; 会创建一个 V8 实例; 会建立父子进程的IPC通道,能够进行通信。
同步/异步
大部分时候,子进程的创建是异步的。也就是说,它不会阻塞当前的事件循环,这对于性能的提升很有帮助。
当然,有的时候,同步的方式会更方便(阻塞事件循环),比如通过子进程的方式来执行shell脚本时。
node同样提供同步的版本,比如:
- spawnSync()
- execSync()
- execFileSync()

忽略上面的答案。。
- 显然:无法使用child_process.create() 来创建。
- spawn无法接受callback作为参数。
- execFile确实可以直接执行特定程序,参数不被shell解释,因此更具有安全性。
- fork可以在父子进程之前建立IPC管道,便于进程间通讯。
- 子进程可以是异步的也可以是同步的,大多数时候建立的时异步的,会比较方便。
- execFile不能执行shell命令,而是直接执行文件。

