
Redis数据库
一、常用的数据库比较
关系型数据库 MySQL
MySQL 是一个最流行的关系型数据库,在互联网产品中应用比较广泛。一般情况下,MySQL 数据库是选择的第一方案,基本上有 80% ~ 90% 的场景都是基于 MySQL 数据库的。因为,需要关系型数据库进行管理,此外,业务存在许多事务性的操作,需要保证事务的强一致性。同时,可能还存在一些复杂的 SQL 的查询。值得注意的是,前期尽量减少表的联合查询,便于后期数据量增大的情况下,做数据库的分库分表。
内存数据库 Redis
随着数据量的增长,MySQL 已经满足不了大型互联网类应用的需求。因此,Redis 基于内存存储数据,可以极大的提高查询性能,对产品在架构上很好的补充。例如,为了提高服务端接口的访问速度,尽可能将读频率高的热点数据存放在 Redis 中。这个是非常典型的以空间换时间的策略,使用更多的内存换取 CPU 资源,通过增加系统的内存消耗,来加快程序的运行速度。
在某些场景下,可以充分的利用 Redis 的特性,大大提高效率。这些场景包括缓存,会话缓存,时效性,访问频率,计数器,社交列表,记录用户判定信息,交集、并集和差集,热门列表与排行榜,最新动态等。
使用 Redis 做缓存的时候,需要考虑数据不一致与脏读、缓存更新机制、缓存可用性、缓存服务降级、缓存穿透、缓存预热等缓存使用问题。
文档数据库 MongoDB
MongoDB 是对传统关系型数据库的补充,它非常适合高伸缩性的场景,它是可扩展性的表结构。基于这点,可以将预期范围内,表结构可能会不断扩展的 MySQL 表结构,通过 MongoDB 来存储,这就可以保证表结构的扩展性。
此外,日志系统数据量特别大,如果用 MongoDB 数据库存储这些数据,利用分片集群支持海量数据,同时使用聚集分析和 MapReduce 的能力,是个很好的选择。
MongoDB 还适合存储大尺寸的数据,GridFS 存储方案就是基于 MongoDB 的分布式文件存储系统。
列族数据库 HBase
HBase 适合海量数据的存储与高性能实时查询,它是运行于 HDFS 文件系统之上,并且作为 MapReduce 分布式处理的目标数据库,以支撑离线分析型应用。在数据仓库、数据集市、商业智能等领域发挥了越来越多的作用,在数以千计的企业中支撑着大量的大数据分析场景的应用。
全文搜索引擎 ElasticSearch
在一般情况下,关系型数据库的模糊查询,都是通过 like 的方式进行查询。其中,like "value%" 可以使用索引,但是对于 like "%value%" 这样的方式,执行全表查询,这在数据量小的表,不存在性能问题,但是对于海量数据,全表扫描是非常可怕的事情。ElasticSearch 作为一个建立在全文搜索引擎 Apache Lucene 基础上的实时的分布式搜索和分析引擎,适用于处理实时搜索应用场景。此外,使用 ElasticSearch 全文搜索引擎,还可以支持多词条查询、匹配度与权重、自动联想、拼写纠错等高级功能。因此,可以使用 ElasticSearch 作为关系型数据库全文搜索的功能补充,将要进行全文搜索的数据缓存一份到 ElasticSearch 上,达到处理复杂的业务与提高查询速度的目的。
ElasticSearch 不仅仅适用于搜索场景,还非常适合日志处理与分析的场景。著名的 ELK 日志处理方案,由 ElasticSearch、Logstash 和 Kibana 三个组件组成,包括了日志收集、聚合、多维度查询、可视化显示等。
二、Redis数据库简介
名称
REmote DIctionary Server(Redis) 是一个由Salvatore Sanfilippo写的key-value存储系统。Redis是一个开源的使用ANSI C语言编写、遵守BSD协议、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。
简介
Redis 是完全开源免费的,遵守BSD协议,是一个高性能的key-value数据库。
Redis 与其他 key - value 缓存产品有以下三个特点:
- Redis支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用。
- Redis不仅仅支持简单的key-value类型的数据,同时还提供list,set,zset,hash等数据结构的存储。
- Redis支持数据的备份,即master-slave模式的数据备份。
优势
- 性能极高 – Redis能读的速度是110000次/s,写的速度是81000次/s 。
- 丰富的数据类型 – Redis支持二进制案例的 Strings, Lists, Hashes, Sets 及 Ordered Sets 数据类型操作。
- 原子 – Redis的所有操作都是原子性的,同时Redis还支持对几个操作全并后的原子性执行。
- 丰富的特性 – Redis还支持 publish/subscribe, 通知, key 过期等等特性。
Redis与其他key-value存储有什么不同?
Redis运行在内存中但是可以持久化到磁盘,所以在对不同数据集进行高速读写时需要权衡内存,因为数据量不能大于硬件内存。在内存数据库方面的另一个优点是,相比在磁盘上相同的复杂的数据结构,在内存中操作起来非常简单,这样Redis可以做很多内部复杂性很强的事情。同时,在磁盘格式方面他们是紧凑的以追加的方式产生的,因为他们并不需要进行随机访问。另外,和mongodb相比,redis的特点不仅仅是在内存中运行,这样的加载速度更快,另外一个特点是redis的键值对是扁平化的,而不支持像mongodb一样可以深层次嵌套的存储方式。
三、安装Redis数据库
这里以在windows上安装为介绍基础,在github上下载msi文件,然后按步骤安装即可,安装过程中勾选加入环境变量。
然后,我们通过如下方式就可以打开redis服务器,其中redis-server.exe就是服务器执行文件,而redis.windows.conf是相关的配置文件。
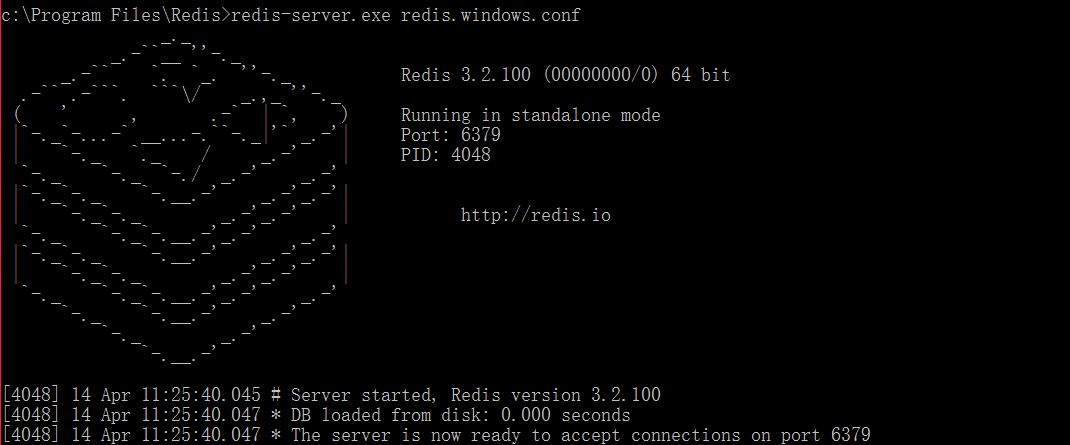
注意:在安装过程中,可能报错“creating server tcp listening socket 127.0.0.1:6379: bind No error”,这时,我们可以通过下面方式来解决,即在cmd中依次运行:
redis-cli.exe shutdown exit redis-server.exe redis.windows.conf
这样,我们就可以成功开启服务器了。即port为6379,然后创建了一个进程。
创建服务器之后,我们就可以另外打开一个cmd,然后作为客户单进行请求链接了,如下所示:

其中 -h 表示指定链接的host主机,使用localhost即可, -p表示端口,即为6379。
注意:因为redis-cli.exe就是redis-cli,且6379是redis的默认端口号,所以我们可以通过redis-cli -h localhost建立链接,如下:
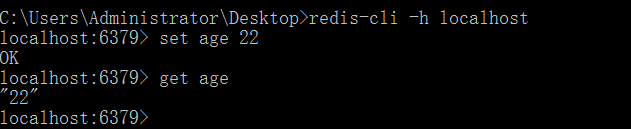
如上所示,相比前者会更加简洁。
- 其中 set age 22,就是进行redis数据库存储了,即设置key为age,设置value为22,在输入的过程中,redis也有会提示。
- 而get age就是读取age这个key的值了。
