redis-cluster(集群)
1.数量太大
一台服务器内存正常是16~256G,假如你的业务需要500G内存, 核心思想都是将数据分片(sharding)存储在多个redis实例中,每一片就是一个redis实例。
各大企业集群方案: twemproxy由Twitter开源 Codis由豌豆荚开发,基于GO和C开发 redis-cluster官方3.0版本后的集群方案
2.数据分布原理图
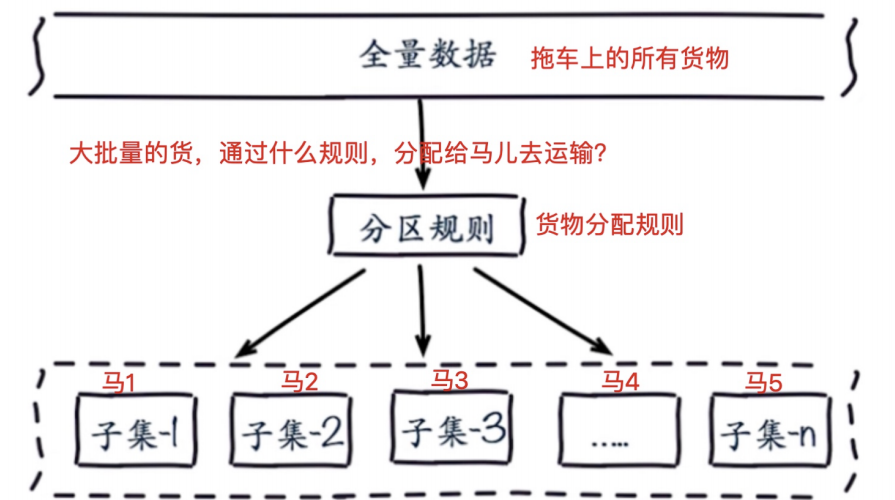
3.数据分布理论
#分布式数据库首要解决把整个数据集按照分区规则映射到多个节点的问题,即把数据集划分到多个节点上,每个节点负责整 个数据的一个子集。
#Redis Cluster采用哈希分区规则,因此接下来会讨论哈希分区规则。
节点取余分区
一致性哈希分区
虚拟槽分区(redis-cluster采用的方式)
数据分区:
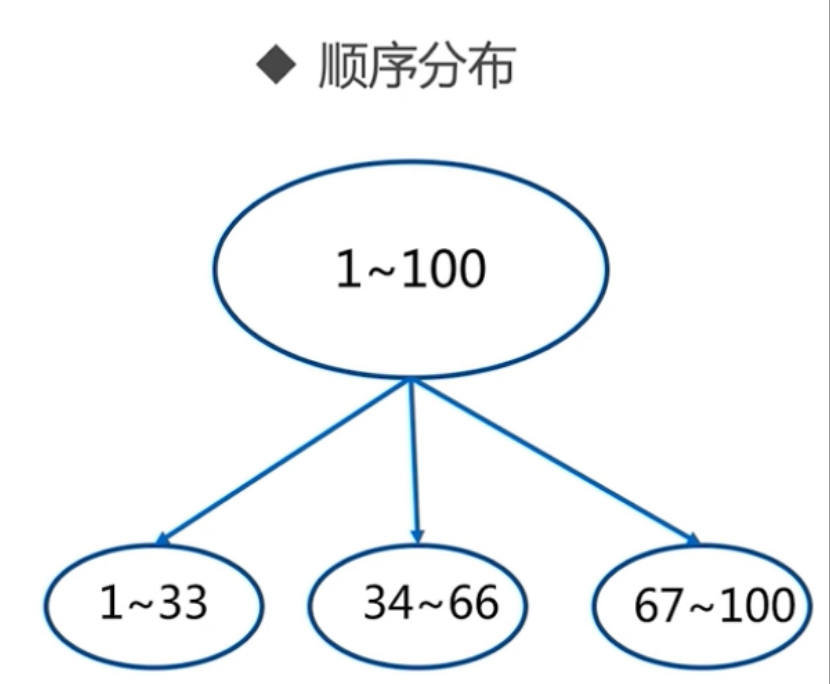
哈希分区:
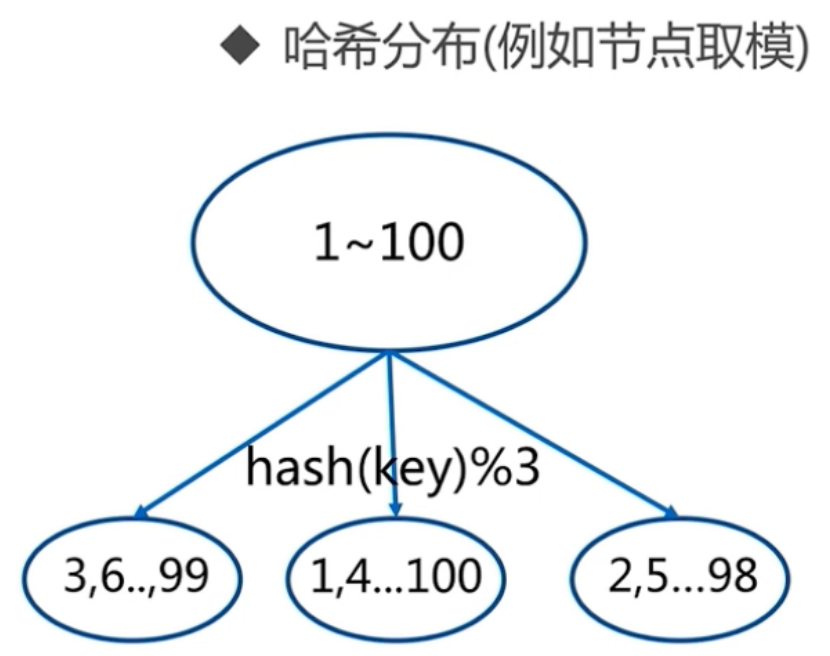
例如按照节点取余的方式,分三个节点
1~100的数据对3取余,可以分为三类
余数为0
余数为1
余数为2
那么同样的分4个节点就是hash(key)%4 节点取余的优点是简单,客户端分片直接是哈希+取余
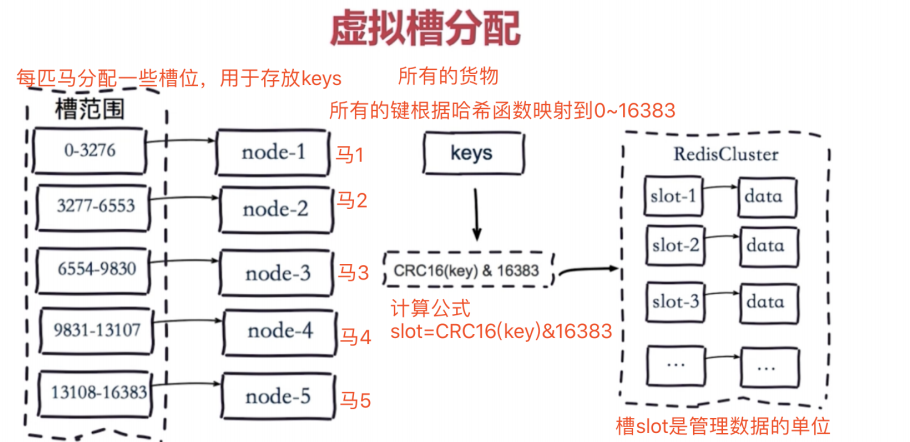
虚拟槽分配
#即使使用哨兵,redis每个实例也是全量数据存储,每个redis存储的内容都是完整的数据。
#为了最大化利用内存,可以采用cluster群集 -->分布式存储,即每台redis存储不同的内容。
采用redis-cluster架构正是满足这种分布式存储要求的集群的一种体现。
redis-cluster架构中,被设计成共有16384个hash slot。
每个master分得一部分slot,其算法为:hash_slot = crc16(key) mod 16384 ,这就找到对应slot。
采用hash slot的算法,实际上是解决了redis-cluster架构下,有多个master节点的时候,数据如何分布到这 些节点上去。
key是可用key,如果有{}则取{}内的作为可用key,否则整个可以是可用key。群集至少需要3主3从,且每个实例 使用不同的配置文件。
程序的道路上一去不复返

