

索引
索引
索引的基本原理
索引用来快速查找那么具有特定值的记录,如果没有索引,一般就要查询遍历整张表。
索引的原理:将无序的数据变成有序的查询
- 把创建了索引的列的内容进行排序
- 对排序结果生成倒排表
- 在倒排表内容上拼上数据地址链
- 在查询的时候,先拿到倒排表内容,在取出数据地址链,从而拿到具体数据
索引的设计原则
查询更快,占空间最少
- 出现索引的列,一定是出现在where子句中的列或者连着子句中指定的列
- 基数比较小的表,索引效果不好(还要单独维护索引),没必要在创建索引
- 使用前缀索引,如果对长字符串进行索引,应该指定一个前缀长度,这样可以节省大量的索引空间,如果索引词超过索引的前缀长度,则使用索引排除不匹配的行,然后检查其余行是否可能匹配
- 不要过度索引,索引需要额外的磁盘空间,并降低写操作性能。在修改内容时,索引会进行更新甚至重构,索引列越多,时间越长,所以只保持需要的索引有利于 查询即可
- 定义外键的数据列一定要建立索引
- 更新频繁字段,查询很少涉及的列,重复值比较多,区分度不高的列不适合创建索引
- 尽量扩展索引,不要新建索引。比如表中已经有了a索引,现在要加(a,b)索引,那么只需要修改原来的索引即可。
- 对于定义big,text,image的数据类型不要创建索引
数据结构
索引的数据结构和具体的存储引擎相关,在mysql中使用较多就是hase索引和B+树索引,InnoDB存储引擎默认实现的是B+TREE索引,Memory存储引擎默认是Hash索引。对于哈希索引来说,底层数据结构就是哈希表,因此在绝大多数需求为单条记录查询的时候,可以选择哈希索引,查询性能最快;其余大部分场景,建议使用B+TREE索引。
B+树
B+树是一个平衡的多叉树,叶子节点之间有指针相互链接,在B+树上的常规索引,从根节点到叶子节点的搜索效率基本相当,不会出现大幅度波动,而且基于索引的顺序扫描时,也可以利用双向指针快速左右移动,效率非常高,因此,B+树索引被广泛应用与于数据库,文件系统等场景。
哈希索引
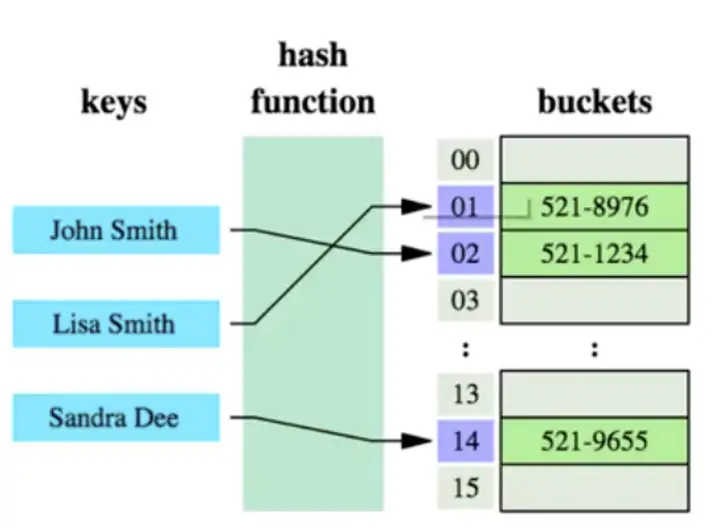
哈希索引采取的是一定的哈希算法,把键值换算成新的哈希值,检索的时候不需要类似B+树那样从根节点到叶子节点逐级查找,只需要一次哈希算法就可以立即定位到相应的位置,速度非常快。
如果是等值查询,那么哈希索引非常有优势,因为只需要进行一次算法就可以找到相应的键值;前提是键值都是唯一的,如果键值不唯一,就需要先找到该键所在的位置,然后在根据链表往后扫描,直到找到相应的数据;
如果是范围查询,就不能用哈希算法了,因为原先有序的键值,经过哈希算法之后,有可能变成不连续的了,也就没办法在利用索引完成范围查询检索;
也无法完成排序,以及模糊查询(部分模糊,本质上就是范围查询)。
哈希索引也不支持多列联合索引的最左匹配原则;(将多个字段隐射成一个hase值,最左匹配原则也就没有任何意义了,没有最左只有一个值)
B+树的索引的关键字检索效率比较平均,不想B树那么波动幅度大,在有大量重复键值的情况下,哈希索引的效率也是极低的,因为存在哈希碰撞问题
索引分类
主键索引(PRIMARY KEY):唯一的标识,主键不可重复,数值不能为null,只能有一个列作为主键
唯一索引(UNIQUE KEY):避免重复的列数据出现,唯一索引可以有多个,数值可以为null
全文索引(FullText):通过倒序排序,快速定位元素
常规索引(INDEX,KEY):默认的
联合索引: 索引可以覆盖多个数据列。
-
可以通过
ALTER TABLE table_name ADD INDEX index_name(column1, column2, column3);创建组合索引
前缀索引
对文本的前几个字符建立索引(具体是几个字符在建立索引时指定),这样索引更小,查询更快。
一般来说,如果需要使用前缀索引,可能是因为整个字段的数据量太大,没必要对整个字段建立索引,前缀索引仅仅是选择一个字段的部分字符作为索引,这样一来节省索引空间,另一方面可以提升索引效率,但是这种方式也会降低索引的选择性
索引的选择性
是指不重复的索引值(基数)和数据表的记录总数的比值,取值范围在0-1之间。索引的选择性越高查询效率越高,因为选择性高的索引可以让mysql在查询中就过滤掉了很多行。但并不是索引选择性越高的索引越好。我们使用前缀索引就用找一个合适的索引选择数

#全列选择性
SELECT COUNT(DISTINCT column_name) / COUNT(*) FROM table_name
#某一长度的前缀选择性
SELECT COUNT(DISTINCT LEFT (column_name,prefix_length)) / COUNT(*) FROM table_name
# 注意选择合适的 prefix_length,直至计算结果约等于全列选择性的时候,就是最佳结果了。
创建前缀索引
#给指定字段创建前缀索引
alter table table_name add index key (column_name(prefix_length));
alter table table_name add key (column_name(prefix_length));
#查看刚刚创建的前缀索引
show index from column_name;
并是不所有的字段都适合前缀索引,对于TEXT,BLOB列进行索引,或者非常长的VARCHAER列,就必须使用前缀索引,因为MYSQL不允许索引他们的全部长度。但是对于某个字段内容,比如前缀部分相似度很高,此时的前缀索引就效果不明显,采用覆盖索引会更好。
倒序存储:身份证
#倒序存储
# 如果存储身份证号时把它倒过来存,每次查询这么写:
select field_list from t where id_card = reverse('input_id_card_string');
# 由于身份证号最后6位没有地址码这样重复逻辑,所以最后6位可能提供足够的区分度。 实践中也别忘记使用count(distinct)验证区分度哦!
联合索引
先按照第一个数据进行排序,第二个数据在第一个数据排序的基础上在进行排序,以此类推,因此第一个数据是全局有序,其他的数据局部有序(只有上一个数据相同时,他才有序,单看是无序的)
只有先确定了前一个(左侧的值)后,才能确定下一个值。如果有范围查询的话,那么使用范围查询的字段后面的字段索引不会起作用。
将区分度高的字段放在前面,区分度低的字段放后面。像性别、状态这种字段区分度就很低,我们一般放后面。
值得注意的是,in 和 = 都可以乱序,比如有索引(a,b,c),语句 select * from t where c =1 and a=1 and b=1,这样的语句也可以用到最左匹配,因为 MySQL 中有一个优化器,他会分析 SQL 语句,将其优化成索引可以匹配的形式,即 select * from t where a =1 and a=1 and c=1,把你查询的条件调整为和索引一致
最左匹配原则
最左匹配原则都是针对联合索引来说的
最左优先,以最左边的为起点任何连续的索引都能匹配上。同时遇到范围查询(>、<、between、like)就会停止匹配。
例如:b = 2 如果建立(a,b)顺序的索引,是匹配不到(a,b)索引的;但是如果查询条件是a = 1 and b = 2或者a=1(又或者是b = 2 and b = 1)就可以,因为优化器会自动调整a,b的顺序。再比如a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)顺序的索引,d是用不到索引的,因为c字段是一个范围查询,它之后的字段会停止匹配。
面试官:谈谈你对mysql联合索引的认识? - 知乎 (zhihu.com)
联合索引的好处
A:避免回表
在执行计划中,table access by index rowid代表是回表动作。
如在user的id列建有索引,select id from user这个不用回表,直接从索引中读取id的值,而select id,name from user中,不能返回除id列其他的值,所以必须要回表。
如果建有了id和name列的联合索引,则可以避免回表。
另外,建立了id和name的联合索引(id列在在前),则select id from user可以避免回表,而不用单独建立id列的单列索引。
B:两个单列查询返回行较多,同时查返回行较少,联合索引更高效。
如果select * from user where id=2 和select * from user where name='tom' 各自返回的行数比较多,而select * from user where id=2 and name='tom'返回的行数比较少,那么这个时候使用联合索引更加高效。
什么时候该用联合索引以及如何设计组合索引更高效
A:等值查询中,查询条件a返回的条目比较多,查询条件b返回的条目比较多,而同时查询a、b返回的条目比较少,那么适合建立联合索引;
B:对于有等值查询的列和范围查询的列,等值查询的列建在前、范围查询的列建在后比较实用;
C:如第3点A中的另外说到,如果联合索引列的前置列与索引单列一致,那么单列查询可以用到索引,这样就避免了再建单列索引,因此联合索引的前置列应尽量与单列一致;
注意
A:超过3个列的联合索引不合适,否则虽然减少了回表动作,但索引块过多,查询时就要遍历更多的索引块了;
B:建索引动作应谨慎,因为建索引的过程会产生锁,不是行级锁,而是锁住整个表,任何该表的DML操作都将被阻止,在生产环境中的繁忙时段建索引是一件非常危险的事情;
C:对于某段时间内,海量数据表有频繁的更新,这时可以先删除索引,插入数据,再重新建立索引来达到高效的目的。
注意
- 索引并不是越多越好
- 不要对进程变动的数据加索引
- 小数据量的表不需要加索引
- 索引一般加在用来查询的字段上
索引可以极大的提高查询数据的效率,但是会降低插入,删除,更新表的速度,因为执行这些语句时,还有操作索引文件
索引需要占据物理空间,除了数据表占据的空间之外,每个索引还要占一定的物理空间,如果要建立聚簇索引,那么需要的空间就会更大,如果非聚簇索引很多,一旦聚簇索引改变,那么所有的非聚簇索引也会改变
索引失效
- 查询条件中有or,即使有部分条件带索引也会失效,如果所有的查询条件都建有索引,索引不会失效
- like查询以%开头
- 列类型是字符串,查询条件中必须将数据用引号引用起来,否则不走索引
- 索引列上参与计算,使用函数,!=,<>
- 违背最左匹配原则
- 单独引用复合索引的非第一位置的索引列
- 隐式转换,比如我们定义一个字段为char类型,但是查询时把这个字段当成number类型传给where
执行计划
执行计划就是sql的执行查询的顺序,以及如何使用索引查询,返回的结果集的行数。
explain sql; 查看索引
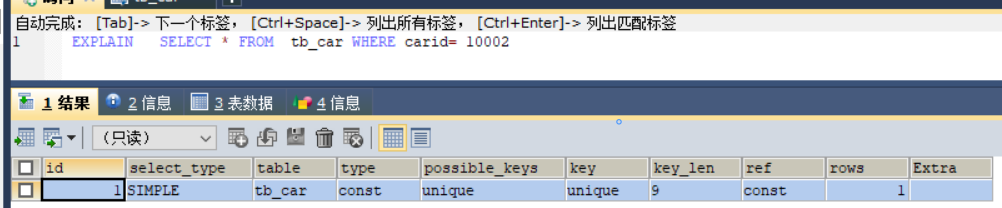
id
select 查询的序列号,标识执行的顺序
-
id 相同,执行顺序由上至下
-
id 不同,如果是子查询,id 的序号会递增,id 值越大优先级越高,越先被执行
select_type
查询的类型,主要是用于区分普通查询、联合查询、子查询等。
-
SIMPLE:简单的 select 查询,查询中不包含子查询或者 union
-
PRIMARY:查询中包含子部分,最外层查询则被标记为 primary
-
SUBQUERY/MATERIALIZED:SUBQUERY 表示在 select 或 where 列表中包含了子查询,MATERIALIZED:表示 where 后面 in 条件的子查询
-
UNION:表示 union 中的第二个或后面的 select 语句
-
UNION RESULT:union 的结果
table
查询涉及到的表。
-
直接显示表名或者表的别名
-
<unionM,N> 由 ID 为 M,N 查询 union 产生的结果
-
<subqueryN> 由 ID 为 N 查询产生的结果
type
访问类型,SQL 查询优化中一个很重要的指标,结果值从好到坏依次是:system > const > eq_ref > ref > range > index > ALL。
-
system:系统表,少量数据,往往不需要进行磁盘IO
-
const:常量连接
-
eq_ref:主键索引(primary key)或者非空唯一索引(unique not null)等值扫描
-
ref:非主键非唯一索引等值扫描
-
range:范围扫描
-
index:索引树扫描
-
ALL:全表扫描(full table scan)
在实际业务中,sql能使用到range, ref级别的索引就算是比较好的了。
possible_keys
查询过程中有可能用到的索引。
key
实际使用的索引,如果为 NULL ,则没有使用索引。
rows
根据表统计信息或者索引选用情况,大致估算出找到所需的记录所需要读取的行数。
filtered
表示返回结果的行数占需读取行数的百分比, filtered 的值越大越好。
Extra
十分重要的额外信息。
-
Using filesort:MySQL 对数据使用一个外部的文件内容进行了排序,而不是按照表内的索引进行排序读取。
-
Using temporary:使用临时表保存中间结果,也就是说 MySQL 在对查询结果排序时使用了临时表,常见于order by 或 group by。
-
Using index:表示 SQL 操作中使用了覆盖索引(Covering Index),避免了访问表的数据行,效率高。
-
Using index condition:表示 SQL 操作命中了索引,但不是所有的列数据都在索引树上,还需要访问实际的行记录。
-
Using where:表示 SQL 操作使用了 where 过滤条件。
-
Select tables optimized away:基于索引优化 MIN/MAX 操作或者 MyISAM 存储引擎优化 COUNT(*) 操作,不必等到执行阶段再进行计算,查询执行计划生成的阶段即可完成优化。
-
Using join buffer (Block Nested Loop):表示 SQL 操作使用了关联查询或者子查询,且需要进行嵌套循环计算。
三星索引
★☆☆
定义:查询相关的索引行是相邻的,或者至少相距足够靠近的话
收益:它最小化了必须扫描的索引片的宽度。
实现:把 WHERE 后的等值条件列作为索引最开头的列,如此,必须扫描的索引片宽度就会缩至最短。
★★☆
定义:索引行的顺序与查询语句的需求一致
收益:它排除了排序操作。
实现:将 ORDER BY 列加入到索引中,保持列的顺序
★★★
定义:如果索引行中包含查询语句中的所有列
收益:这避免了访问表的操作(避免了回表操作),只访问索引就可以满足了。
实现:将查询语句中剩余的列都加入到索引中。
三星索引在实际业务中如果无法同时达到,一般我们认为第三颗星最重要,第一和第二颗星重要性差不多,根据业务情况调整这两颗星的优先度
数据库备份
保证重要数据不丢失 ,数据转移
https://blog.csdn.net/weixin_51486343/article/details/113702736
-- 导出
# mysqldump -h 主机 -u用户名 -p 密码 数据库 表名 >物理磁盘位置/文件名
mysqldump -hlocalhost -uroot -p1111 school student >D:/a.sql
# mysqldump -h 主机 -u用户名 -p 密码 数据库 表1 表2 >物理磁盘位置/文件名
mysqldump -hlocalhost -uroot -p1111 school student teacher >D:/b.sql
# mysqldump -h 主机 -u用户名 -p 密码 数据库 >物理磁盘位置/文件名
mysqldump -hlocalhost -uroot -p1111 school >D:/c.sql
-- 导入
#登入之后,切换到指定数据库 source 备份文件
source d:/a.sql
三大范式
第一范式:每个列都不可以再拆分。 ---- 属性不可分割
第二范式:在第一范式的基础上,每张表只能描述一件事情 (非主键列完全依赖于主键,而不能是依赖于主键的一部分。) ---- 主键约束
第三范式:在第二范式的基础上,保证数据库表中的每一列数据都和主键直接相关,而不能间接相关,不能依赖传递(非主键列只依赖于主键,不依赖于其他非主键。) --- 外键约束
一范式就是属性不可分割。属性是什么?就是表中的字段。
不可分割的意思就按字面理解就是最小单位,不能再分成更小单位了。
这个字段只能是一个值,不能被拆分成多个字段,否则的话,它就是可分割的,就不符合一范式。
不过能不能分割并没有绝对的答案,看需求,也就是看你的设计目标而定。
举例:
学生信息组成学生信息表,有姓名、年龄、性别、学号,家庭信息等信息组成。
姓名不可拆分吧?所以可以作为该表的一个字段。
家庭信息包含了人口数量,家庭地址,所以家庭信息可以在进行拆分。简单来说,一范式是关系数据库的基础,但字段是否真的不可拆分,根据你的设计目标而定。
二范式就是要有主键,要求其他字段都依赖于主键。
为什么要有主键?没有主键就没有唯一性,没有唯一性在集合中就定位不到这行记录,所以要主键。
其他字段为什么要依赖于主键?因为不依赖于主键,就找不到他们。更重要的是,其他字段组成的这行记录和主键表示的是同一个东西,而主键是唯一的,它们只需要依赖于主键,也就成了唯一的。
如果有同学不理解依赖这个词,可以勉强用“相关”这个词代替,也就是说其他字段必须和它们的主键相关。因为不相关的东西不应该放在一行记录里。
举例:
学生信息组成学生表,姓名可以做主键么?
不能!因为同名的话,就不唯一了,所以需要学号这样的唯一编码才行。
那么其他字段依赖于主键是什么意思?
就是“张三”同学的年龄和性别等字段,不能存储别人的年龄性别,必须是他自己的,因为张三的学号信息就决定了,这行记录归张三所有,不能给无关人员使用。
三范式就是要消除传递依赖,方便理解,可以看做是“消除冗余”。
消除冗余应该比较好理解一些,就是各种信息只在一个地方存储,不出现在多张表中。
比如说大学分了很多系(中文系、英语系、计算机系……),这个系别管理表信息有以下字段组成:
系编号,系主任,系简介,系架构。
那么再回到学生信息表,张三同学的年龄、性别、学号都有了,我能不能把他的系编号,系主任、系简介也一起存着?
如果你问三范式,当然不行,因为三范式不同意。
因为系编号,系主任、系简介已经存在系别管理表中,你再存入学生信息表,就是冗余了。
三范式中说的传递依赖,就出现了。
这个时候学生信息表中,系主任信息是不是依赖于系编号了?而这个表的主键可是学号啊!
所以按照三范式,处理这个问题的时候,学生表就只能增加一个系编号字段。
这样既能根据系编号找到系别信息,又避免了冗余存储的问题。
规范性和性能问题
关联的表不能超过三张
- 考虑商业化需求和目标(成本,用户体验)数据库的性能更加重要
- 在规范性能的问题的时候,需要适当考虑一下规范性
- 故意给某些表增加一些冗余字段(从多表查询变成单表)
- 故意添加一些计算列(从大数据减低为小数据的查询:索引
JDBC
JDBC 指 Java 数据库连接,是一种标准Java应用编程接口( JAVA API),用来连接 Java 编程语言和广泛的数据库。
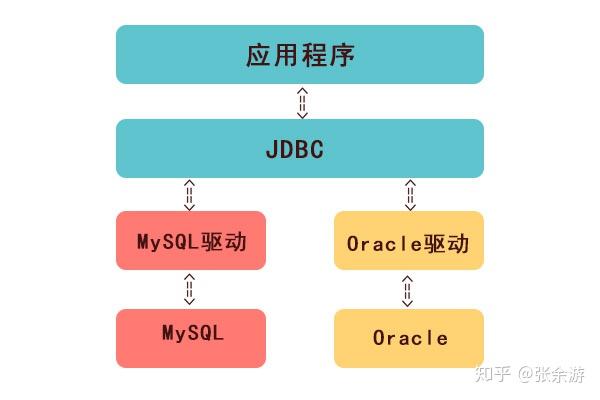
项目连接数据库 ---- maven导入价包
1.Maven详细安装教程_maven安装_慕之寒的博客-CSDN博客
2.IDEA中利用maven自动下载第三方Jar包_cry-newbie的博客-CSDN博客_idea下载jar包
3.Maven添加mysql依赖:https://blog.csdn.net/keyboard_/article/details/114337739
sql注入
SQL注入是什么,如何避免SQL注入? (biancheng.net)
SQL注入是常见的利用程序漏洞进行攻击的方法。
导致sql注入攻击并非系统造成的,而是利用sql语言漏洞获得合法身份登陆系统
例如:
"Select * from users where name='"+uName+"' and pwd='"+uPwd+"' "
如用户在t_name中输入tom or 1= 1 就可以进入系统了。
Select * from users where name = ‘tom’ or 1=‘1’ and pwd=‘123’
恶意拼接
SELECT * FROM users WHERE user_id = $user_id
# user_id 是传入的参数,如果传入的参数值为“1234; DELETE FROM users” ,语句一执行,就会删除users表的所有数据
SELECT * FROM users WHERE user_id = 1234; DELETE FROM users
-
使用正则表达式过滤传入的参数
-
采用预编译语句集,它内置了处理SQL注入的能力,使用它的setXXX方法传值
-
jsp中调用该函数检查是否包函非法字符
-
传入参数用#{}
面试题:Mybatis中 $ 和 # 的区别?_>no problem<的博客-CSDN博客_ym文件中采用$符号获取参数
分库分表
就是当表中的数据量过大时,整个查询效率就会降低得非常明显。这时为了提升查询效率,就要将一个表中的数据分散到多个数据库的多个表当中。
选择
不管是IO瓶颈,还是CPU瓶颈,最终都会导致数据库的活跃连接数增加,进而逼近甚至达到数据库可承载活跃连接数的阈值。在业务Service来看就是,可用数据库连接少甚至无连接可用。接下来就可以想象了吧(并发量、吞吐量、崩溃)。
1、IO瓶颈
第一种:磁盘读IO瓶颈,热点数据太多,数据库缓存放不下,每次查询时会产生大量的IO,降低查询速度 -> 分库和垂直分表。
第二种:网络IO瓶颈,请求的数据太多,网络带宽不够 -> 分库。
2、CPU瓶颈
第一种:SQL问题,如SQL中包含join,group by,order by,非索引字段条件查询等,增加CPU运算的操作 -> SQL优化,建立合适的索引,在业务Service层进行业务计算。
第二种:单表数据量太大,查询时扫描的行太多,SQL效率低,CPU率先出现瓶颈 -> 水平分表。
概念
分库:将原来单个数据库上的数据拆分到多个数据库
分表:将原来单个表上的数据拆分到多个表中
有两种方式:水平,垂直
- 水平:将数据分散到多张表里,涉及到分区键
- 分库:结构一样,数据不同,没有交集,减少了io和cpu的压力
- 分表:结构一样,数据不同,没有交集,数据量减少了,可以提高sql的查询效率,减少cpu压力
- 垂直:将数据进行拆分,需要一定的重构
- 分库:数据结构不一样,所有的库并集为全数据
- 分表:数据结构不一样,至少有一个交集,用来关联数据,所有的表并集为全量数据
分区键
数据拆分按照什么规则来拆分
按照数值范围:按照id,日期
这样的优点在于:
-
单表大小可控
-
天然便于水平扩展,后期如果想对整个分片集群扩容时,只需要添加节点即可,无需对其他分片的数据进行迁移
-
使用分片字段进行范围查找时,连续分片可快速定位分片进行快速查询,有效避免跨分片查询的问题。
缺点:
-
热点数据成为性能瓶颈。连续分片可能存在数据热点,例如按时间字段分片,有些分片存储最近时间段内的数据,可能会被频繁的读写,而有些分片存储的历史数据,则很少被查询
根据数值取模:hase取模
一般采用hash取模mod的切分方式,例如:将 Customer 表根据 cusno 字段切分到4个库中,余数为0的放到第一个库,余数为1的放到第二个库,以此类推。这样同一个用户的数据会分散到同一个库中,如果查询条件带有cusno字段,则可明确定位到相应库去查询。
优点:
-
数据分片相对比较均匀,不容易出现热点和并发访问的瓶颈
缺点:
-
后期分片集群扩容时,需要迁移旧的数据(使用一致性hash算法能较好的避免这个问题)
-
容易面临跨分片查询的复杂问题。比如上例中,如果频繁用到的查询条件中不带cusno时,将会导致无法定位数据库,从而需要同时向4个库发起查询,再在内存中合并数据,取最小集返回给应用,分库反而成为拖累。
按照时间分片:比较容易将热点数据区分出来。
按照目标字段前缀指定进行分区:自定义业务规则分片
垂直分区
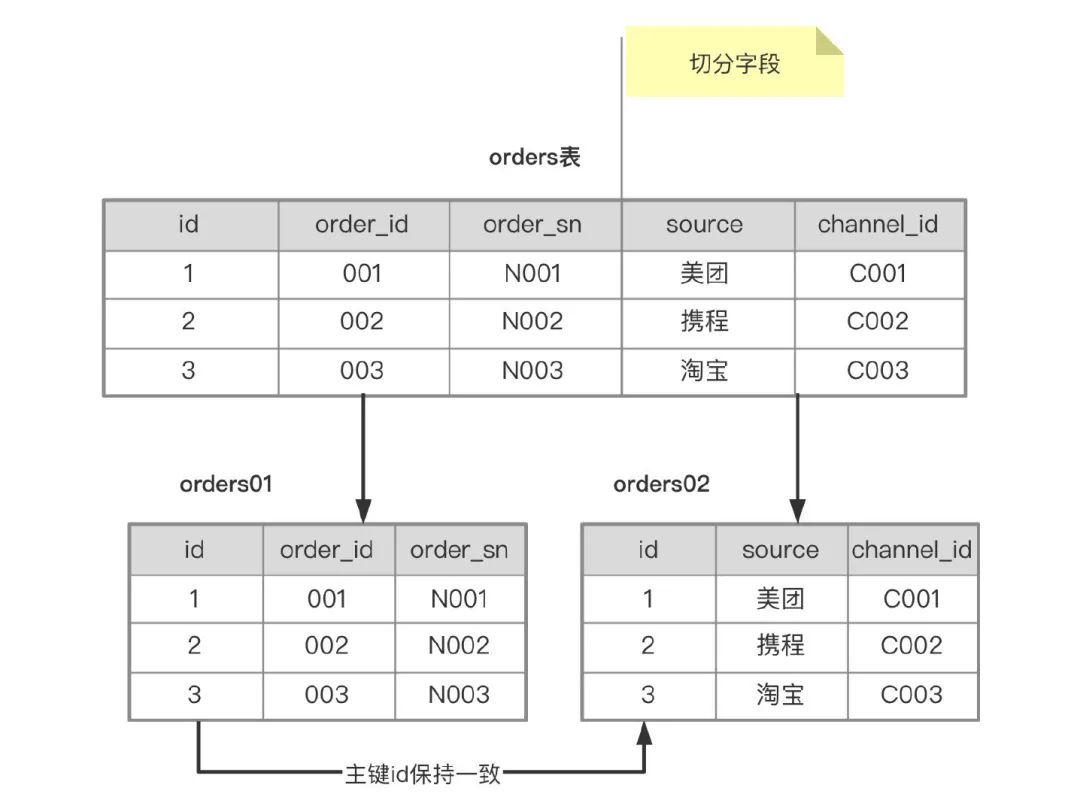
水平分区
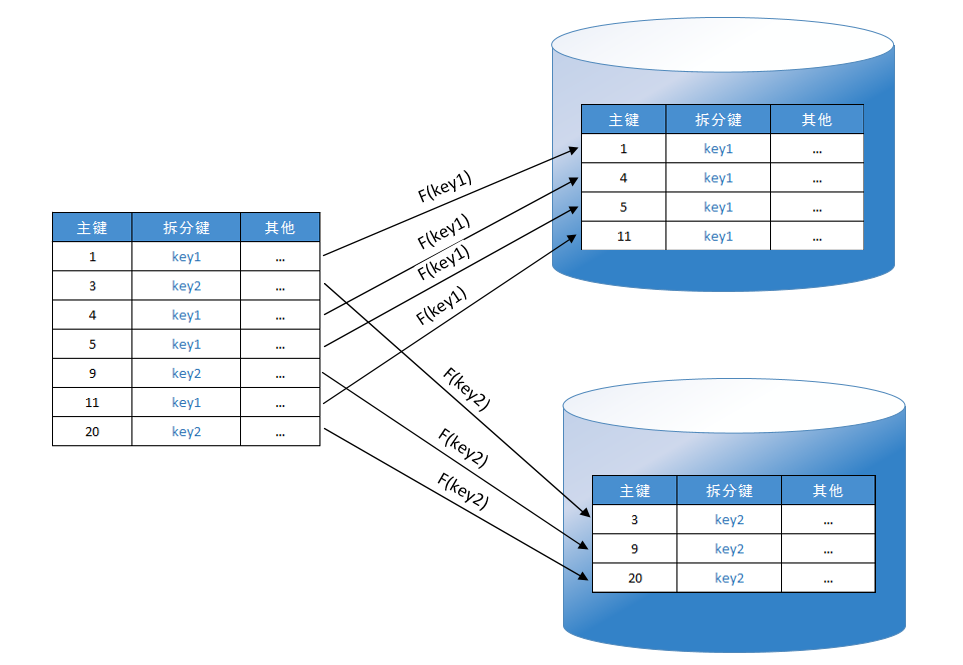
设置唯一主键
UUID :生成简单,基于JVM生成,性能好,不依赖任何第三方主键,没有顺序和业务含义,作为主键不太适合,且不适合范围查询,并且有泄露mac地址的风险(时间戳+硬件编码保证全球唯一)破解难度高
数据库主键:实现简单,单调递增,具有一定的业务可读性,存在暴露业务信息的风险。(多表情况,主键重复)
解决:初始值相同,步长不一样。比如 DB1起始值为1,步长为2,DB2起始值为2。DB1:1,3....,DB2:2,4....,但是我进行增减操作(表),新加一个DB3,要改步长,id值就要重新计算,大量数据修改
DB存在性能瓶颈(数据库能撑起的请求并不多,生成id也要数据库来的话,负担比较大)。
解决:使用redis,mongodb,zk等中间件:增加了系统的复杂度和稳定性
雪花算法:这可能是讲雪花算法最全的文章 - 腾讯云开发者社区-腾讯云 (tencent.com)
产生的问题
MySQL:互联网公司常用分库分表方案汇总! - 知乎 (zhihu.com)
1、联合查询困难
联合查询不仅困难,而且可以说是不可能,因为两个相关联的表可能会分布在不同的数据库,不同的服务器中。
2、需要支持事务
分库分表后,就需要支持分布式事务了。数据库本身为我们提供了事务管理功能,但是分库分表之后就不适用了。如果我们自己编程协调事务,代码方面就又开始了麻烦。
3、跨库join困难
分库分表后表之间的关联操作将受到限制,我们无法join位于不同分库的表,也无法join分表粒度不同的表, 结果原本一次查询能够完成的业务,可能需要多次查询才能完成。 我们可以使用全局表,所有库都拷贝一份。
4、结果合并麻烦
比如我们购买了商品,订单表可能进行了拆分等等,此时结果合并就比较困难。
读写分离,主从复制
读写分离实现
基于主从复制的架构,简单来说就是搞一个主库,挂多个从库,然后我们就单单只写主库,主库会自动同步数据到从库
原理
Mysql的主从复制中主要有三个线程:master(bin log dump thread)、slave (I/0 thread 、SQLthread) ,Master一条线程和Slave中的两条线程。
- 主节点 log dump 线程,当 binlog 有变动时,log dump 线程读取其内容并发送给从节点。
- 从节点 I/O线程接收 binlog 内容,并将其写入到 relay log 文件中
- 从节点的SQL 线程读取 relay log 文件内容对数据更新进行重放,最终保证主从数据库的一致性。
注:主从节点使用 binglog 文件+position 偏移量来定位主从同步的位置,从节点会保存其已接收到的偏移量,如果从节点发生宕机重启,则会自动从 position 的位置发起同步。
注意
从库同步主库数据是串行的,也就是说主库上的并行操作,在从库上是串行执行。由于从库从主库拷贝日志以及串行执行的SQL的特点,在高并发场景下,从库的数据一定比主库慢一点,是有延迟的,所以经常出现,刚写入主库的数据可能是读不到的,要过几十毫秒,甚至几百毫秒才能读取到。
这样会产生一个问题就是假设主库挂了,从库处理失败了,这时候从库升为主库后,日志就丢失了。
所以mysq实际上有两个机制,一个是半同步复制,用来解决主数据库数据丢失问题;一个是并行复制,用来解决主从同步延时问题.
半同步复制:主库写入binlog日志之后,就会强制此时立即将数据同步到从库,从库将日志写入本地的relaylog 之后,接着会返回一个ack给主库,主库接收到至少一个从库的ack之后才认为写操作完成了.
并行复制:指的是从库开启多个线程,并行读取relay log中不同库的日志,然后并行存重放不同库的日志,库级别的并行.
延时问题
查看 Seconds_Behind_Master,可以看到从库复制主库的数据落后了几ms
主从延迟较为严重,有一下解决方案:
- 分库:将一个主库拆分为多个主库,每个主库的写并发就减少好几倍,此时主从延迟可以忽略不计
- 打开Mysql支持的并行复制,多个库并行复制。如果说某个库的写入并发就是特别高,单库写并发达到2000/s,并行复制还是没意义
- 重写代码,慎重,插入数据时立马查询可能查询不到
- 如果必须先插入,立马就查询到,然后立马就要反过来执行一些操作,对这个查询设置直连主库,不推荐,读写分离的意义就没了


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通