

Mysql索引详解
InnoDB页
详解
https://blog.csdn.net/weixin_26786277/article/details/113121272
概念
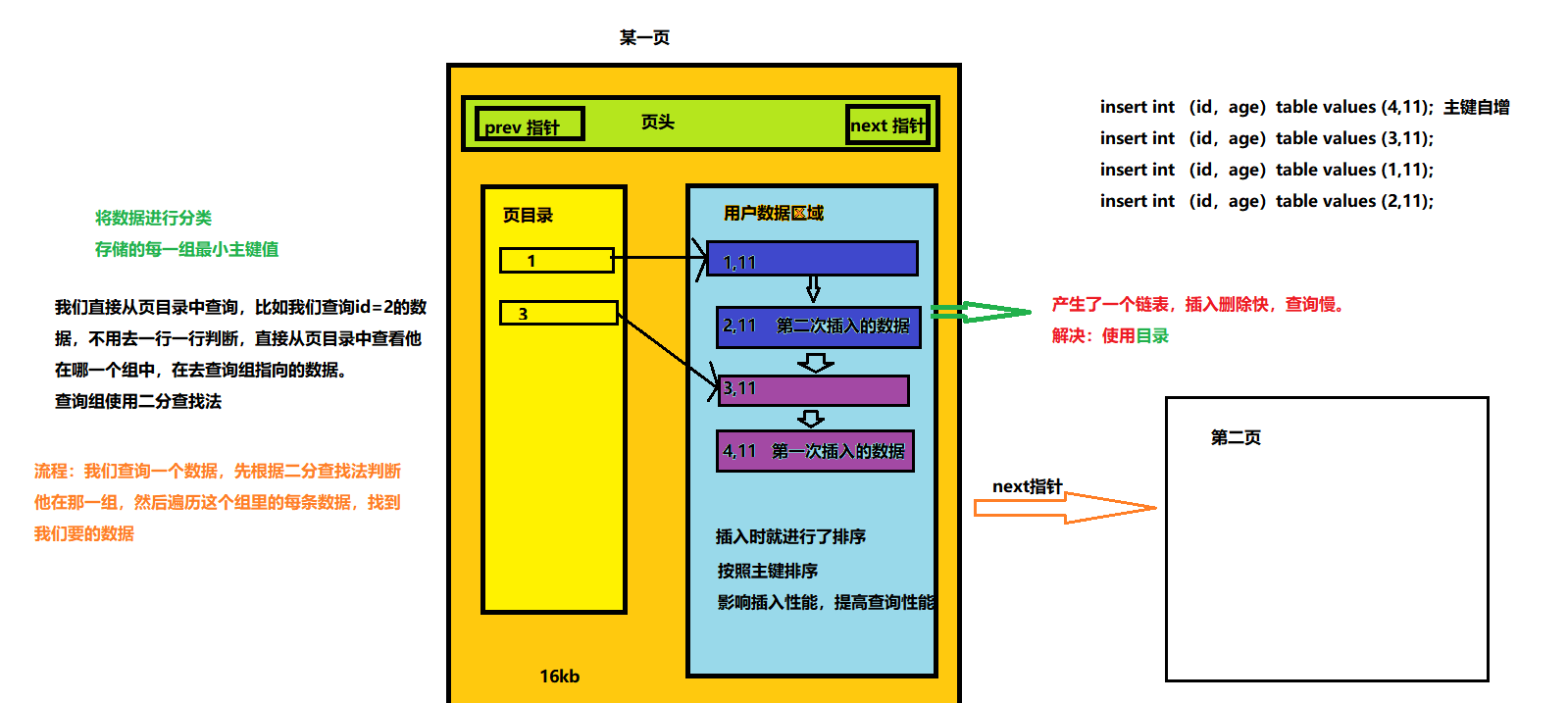
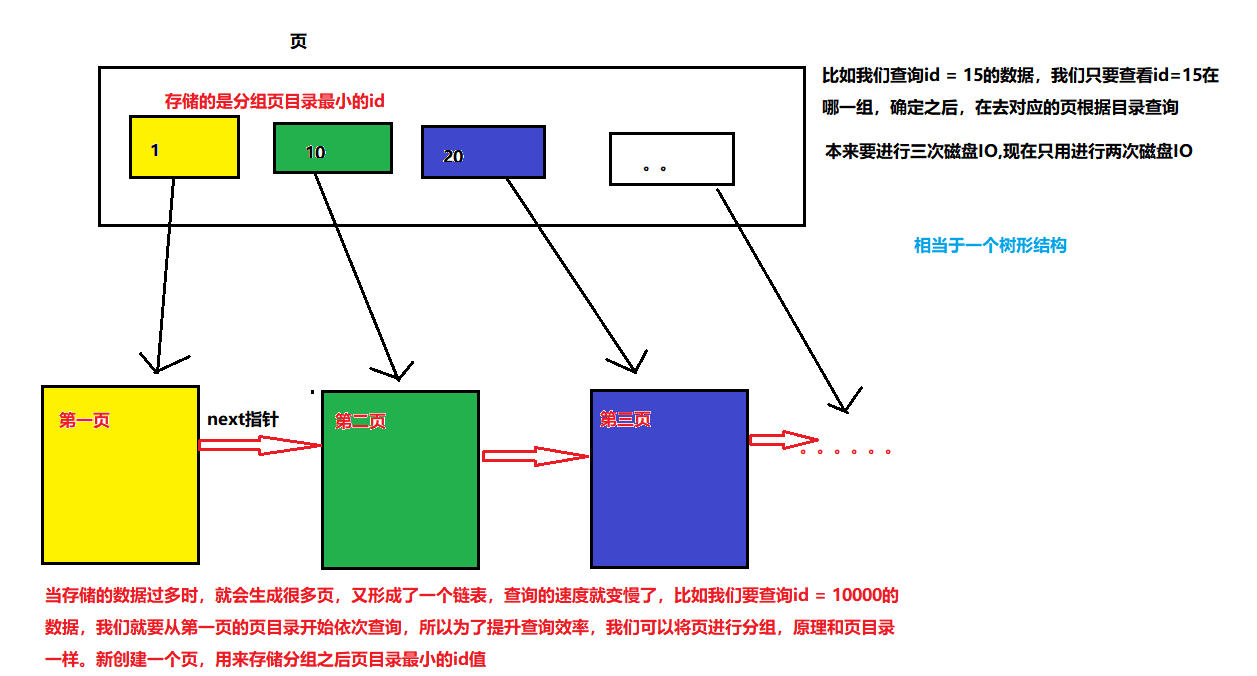
页是InnoDB最小的存储单位,16KB。
why?
如果我们不考虑页,假设表里有八条数据(1,2... 8),这八条数据肯定是在磁盘里面,我们执行select * from table where id = 7; 我们就要从磁盘数据中取出第一行数据id =1,判断不等于在取,id=2不等于在取,直到找到id =7,进行了7次磁盘IO,速度会很慢。所以我们要进行优化,使用页数据,这样我们在去取数据的时候,逻辑还是一样的,我们还是取第一行数据,第一行数据不足16kb,但是我们取数据最小单位是页,所以我们会把整条表的数据全部取出来(只要没有超过16KB),把他们放在内存中,这样的话我们磁盘IO只进行了一次,其他的操作都是在内存中,减少了磁盘IO。
内部结构
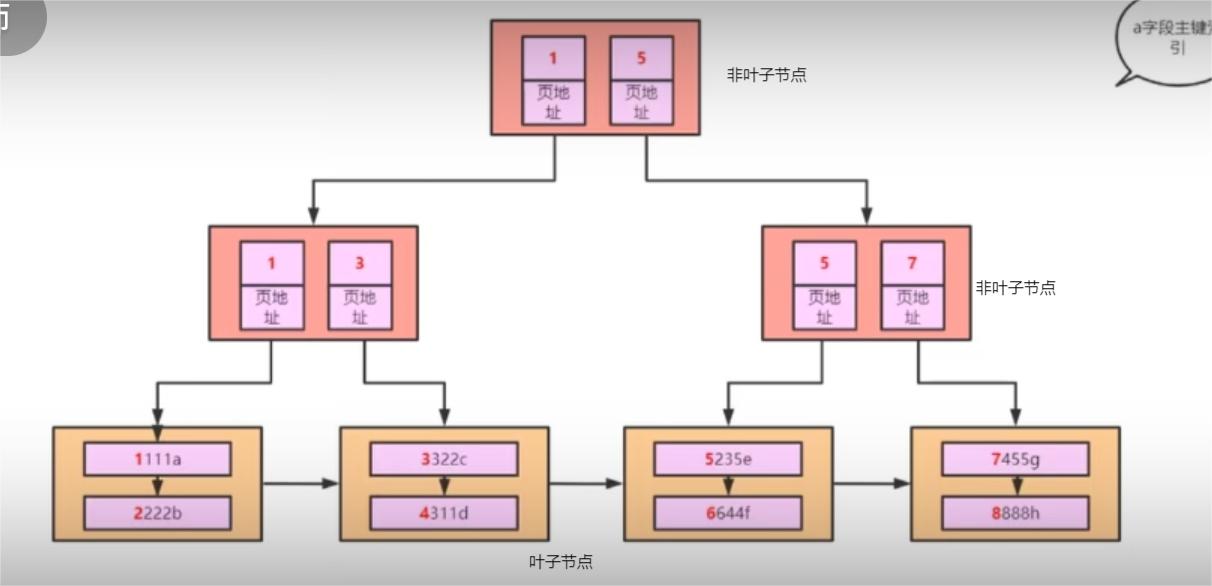
主键索引
我们所看到的这个B+树其实和主键的关系比较大,完全是按照主键的排序一步一步形成的。所以这个B+树就是我们所说的主键索引.
索引就是一个B+树,主键索引就是按照主键排序所生成出来的一个B+树。并且叶子节点存的是我们整张表的数据 。非叶子节点 --- 索引页,叶子节点 ---- 数据页
select * from table where id =5;
走索引:从上往下,利用了索引页,加快了查询速度。 全表扫描:叶子节点从头开始遍历
select * from table where age =5;
只能走全表扫描,因为age字段没有创建对应的索引,这个索引对应的是id字段也就是主键索引,和age不匹配
联合索引
create index idx_t1_ab on table(a,b); ---- 创建一个联合索引-----创建一个B+树,id为主键
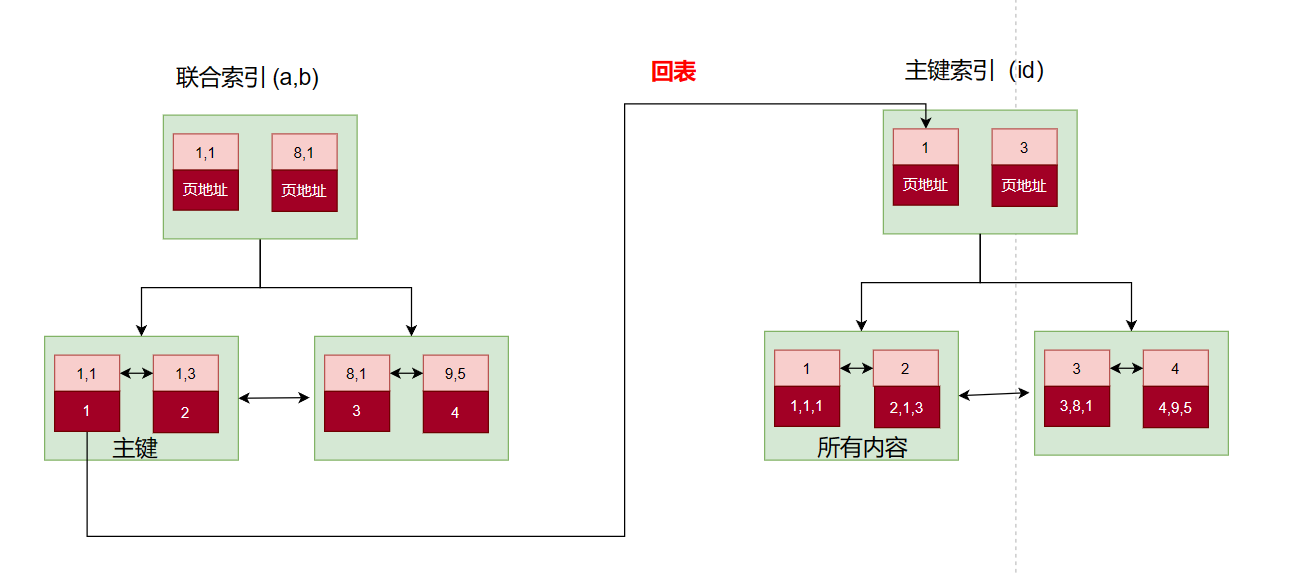
如图所示他们是按照a来进行排序,在a相等的情况下,才按b来排序。
因此,我们可以看到a是有序的。而b是一种全局无序,局部相对有序状态,什么意思呢?
从全局来看,b的值为1,3,1,5,是无序的,因此直接执行b = 7这种查询条件没有办法利用索引。
从局部来看,当a的值确定的时候,b是有序的。例如a = 1时,b值为1,3是有序的状态。因此,你执行a = 1 and b = 1是a,b字段能用到索引的。而你执行a > 1 and b = 1时,a字段能用到索引,b字段用不到索引。因为a的值此时是一个范围,不是固定的,在这个范围内b值不是有序的,因此b字段用不上索引。
综上所示,最左匹配原则,在遇到范围查询的时候,就会停止匹配。

select * from table where a=1 and b=1; --- 走ab联合索引 select * from table where a=1 ; -- 走ab联合索引,符合最左匹配原则 select * from table where b=1; -- 全文查询,没有b字段的索引,且不符合最左匹配,不走联合索引,b字段是无序的 select * from table where a>1 ; -- 全文查询,因为select * ,需要回表,全文索引比联合索引更快,优先使用全文(索引+3次回表) select * from table where a>8 ; -- ab联合索引,同样需要回表,但是只用回表一次,全文索引需要查询4次,所以优先使用联合索引 select a,b from table where a>1; -- ab联合索引,子节点包含需要展示的内容,不需要回表 select id,a,b from table where a>1; -- ab联合索引,子节点包含需要展示的ab字段,主键id也存在,不需要回表
select b from table; -- 走索引,直接扫描叶子节点,最左匹配原则是从上到下的时候要遵守
覆盖索引
一个sql在执行时,可以利用索引快速查找,并且sql所要查询的字段全部在当前索引对应的字段中,那么就表示此sql走完索引后不用回表了,所需要的字段都在当前索引的叶子节点上了,可以直接作为结果返回。
order by
我们创建联合索引(b,c),a为主键
select * from table order by b,c; -- 不走索引,全表扫描 --- *,查询的是全部数据,需要回表
1.全表扫描,额外排序(内存),不用回表
2.走bc索引,不需要排序,需要回表
select b from table order by b,c; -- 走索引,不需要回表
走索引 ,前提:查询的数据全部是索引字段
|
不加where,order by 符合最左匹配原则 |
order by b order by b,c; |
| 加where,where 使用了索引最左前缀最为常量 | where b =1 order by b where b =1 order by b,c; |
不走索引
| 排序不一致 | order by b desc ,c asc; |
| order by 不符合最左匹配原则 | where f=1 order by c; |
| 其他 | https://blog.csdn.net/weixin_44222272/article/details/106724773 |
我们可以看到每创建一个索引,就会生成一个对应的B+树,他们的叶子节点其实是一样的,都是存储的整张表的数据,就是顺序不一样。所以每创建一个索引就相当于把表数据又复制了一份,资源就会很浪费。并且影响insert和update操作性能。所以我们选择性冗余一些必要的字段和每个数据对应的主键的值。当我们利用这个索引去查找数据的时候,利用主键在去主键索引(聚簇索引)上找完整的数据(回表)。也就是联合索引/非聚簇索引
聚簇索引
参考连接:https://www.jianshu.com/p/fa8192853184
- 聚簇索引就是按照每张表的主键构造一颗B+树,同时叶子节点中存放的就是整张表的行记录数据,也将聚簇索引的叶子节点称为数据页。主键索引就是聚簇索引
- 这个特性决定了索引组织表中数据也是索引的一部分,每张表只能拥有一个聚簇索引
- 聚簇索引默认是主键,如果没有定义主键,InnoDB会选择非空的唯一索引代替。如果没有这样的索引,InnoDB会隐式定义一个主键来作为聚簇索引
- 如果你已经设置了主键为聚簇索引,必须先删除主键,然后添加我们想要的聚簇索引,之后恢复设置主键即可
优势
- 数据访问更快:
- 由于行数据和叶子节点存储在一起,同一页中会有多条数据,访问同一数据的不同行记录时,已经把也加载到了Buffer中,再次访问的时候,会在内存中完成访问,不必访问磁盘
- 这样由于主键和行数据时一起被载入磁盘的,找到叶子节点就可以立即将行数据返回了,如果按照主键ID来组织数据,获得数据更快
- 聚簇索引对主键的排序查找和范围查找速度非常快
- 聚簇索引适合用在排序的场合,非聚簇索引不适合
- 取出一定范围数据的时候,使用用聚簇索引
缺点
- 插入速度严重依赖于插入顺序,按照主键的顺序插入是最快的方式,否则将出现页分裂,严重影响性能。因此,对于InnoDB表,我们一般都会定义一个自增的ID作为主键
- 主键的值是顺序的,所以InnoDB会将每一条记录都存储在上一天记录的后面。
- 当达到页的最大填充因子(InnoDB 默认的最大填充因子是页大小的 15/16,留出部分空间用于以后修改)下一条记录就会被写入到新的页中。
- 一旦数据按照这种顺序的方式被加载,主键也就会近乎与被顺序的记录填满(二级索引页可能是不一样的)
- 维护索引很昂贵,特别是插入新行或者主键被更新导至要分页(page split)的时候。因此,对于InnoDB表,我们一般定义主键不可更新;另外,建议在大量插入新行后,选在负载较低的时间段,通过OPTIMIZE TABLE优化表,因为必须被移动的行数据可能造成碎片。使用独享表空间可以弱化碎片
- 如果主键比较大的时候,那辅助索引将会变得更大,因为辅助索引的叶子存储的是主键值;过长的主键值,会导致非叶子节点占用更多的物理空间
非聚簇索引(辅助索引)
- 将数据存储于索引分开结构,索引结构的叶子节点指向了数据的对应行。
- InnoDB中,在聚集索引之上创建的索引叫做辅助索引
- 辅助索引访问数据总是需要二次查找,第一次找到主键值,第二次根据主键值找到行数据:
- 辅助索引叶子节点存储的不再是行的物理位置,而是主键值。
- 通过辅助索引首先找到的是主键值,再通过主键值查询真正的数据(这个过程称为回表)
- 辅助索引的存储不影响数据在聚簇索引中的组织,所以一张表可以由多个辅助索引。在innodb中有时也称辅助索引为二级索引。
- 非聚簇索引都是辅助索引,像复合索引、前缀索引、唯一索引

InnoDB使用的是聚簇索引,将主键组织到一颗B+树中,而行数据就存储在叶子节点上,如使用"where id = 14"这样的条件查找主键,则按照B+树的检索算法就可以查找到对应的叶子节点,之后获得行数据
如果对Name类进行条件搜索,则需要两个步骤:第一步在辅助索引B+树中检索Name,到达其叶子节点获取对应的主键;第二步使用主键在主索引B+t树中再执行一次B+树的检索操作,最终到达叶子节点即可获取整行数据(重点在于通过其他键需要建立辅助索引)
MyISAM使用的是非聚簇索引,非聚簇索引的两颗B+Tree看上去没有什么不同,节点的结构完全一致,支持存储的内容不同,主键索引B+树的节点存储了主键,辅助键索引B+树存储了复制键。表数据存储在独立的地方,这两棵B+树的叶子节点都使用一个地址指向真正的表数据,对于表数据来说,这两个键没有人任何差别。所以索引树是独立的,通过辅助索引无需访问主键的索引
字符排序
每个地方的字符集编码不同,对应的排序也就不同
隐式转换,就是where 条件字符串类型以一个number类型传入,索引失效


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通