
Mysql基础
简介
Mysql是一种关系型数据库管理系统,瑞典MySQL AB公司开发,属于Oracle旗下产品,是目前最流行的关系型数据库管理系统之一。
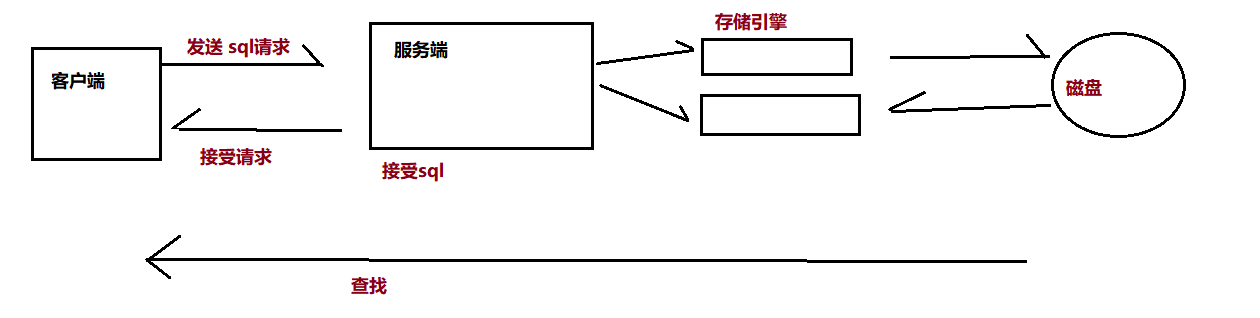
不同的存储引擎使用于不同的应用场景,mysql比较常用的存储引擎有两种:
InnoDB(实现了事务,优化了并发, 其保证了事务就会有重复的数据产生)
MyIASM(查询速度快,没有多余的数据)
那是怎么实现?
通过接口,客户端声明了一系列的接口,不同的存储引擎实现了这些接口,然后就可以调用这些接口了。
MYISAM 和 InnoDB
MYISAM:早些年使用,节约空间,速度快
InnoDB:默认使用,安全性高,支持事务的处理,多表多用户操作,基于磁盘操作
|
MYISAM |
InnoDB |
|
| 事务支持 | 不支持 | 支持 |
| 数据锁 | 表锁 | 行锁 |
| 外键约束 | 不支持 | 支持 |
| 全文索引 | 支持 | 不支持 |
| 表空间大小 | 较小 | 较大,约为MYISAM两倍 |
| 索引 | 非聚簇索引 | 聚簇索引+非聚簇索引 |
| 存储 | 文件中 | 内存中,断电即丢失 |
存储引擎在物理文件上的区别
InnoDB在数据库表中只有一个*.frm文件,以及上级目录的下的ibdata1文件
MYISAM:*.frm 表结构定义文件,*.MYD 数据文件(data),*.MYl 索引文件(index)
所有的数据库文件都存在data目录下,一个文件夹就代表一个数据库,本质上还是文件存储。
查看mysql数据的存储位置
1.cmd 打开小黑窗 2.输入 mysql -u root -p,输入密码 3. mysql -u root -p 4.MySQL 的数据文件就存放在Data目录
所以,如果表的读多于写时,并且不需要事务的支持的,可以将 MyIASM 作为数据库引擎的首选。
InnoDB 适用场景:用于事务处理,具有ACID事务支持,应用于执行大量的insert和update操作的表
MyISAM 适用场景:用于管理非事务表,提供高速检索及全文检索能力,适用于有大量的select操作的表,如 日志表
延伸
一张自增表里面总共有 7 条数据,删除了最后 2 条数据,重启 mysql 数据库,又插入了一条数据,此时 id 是几?
一般情况下,我们创建的表的类型是InnoDB,如果新增一条记录(不重启mysql的情况下),这条记录的id是8;但是如果重启(这条记录的ID是6(7-2+1)。因为InnoDB表只把自增主键的最大ID记录到内存中,所以重启数据库或者对表OPTIMIZE操作,都会使最大ID丢失。
但是,如果我们使用表的类型是MylSAM,那么这条记录的ID就是8。因为MylSAM表会把自增主键的最大ID记录到数据文件里面,重启MYSQL后,自增主键的最大ID也不会丢失。
注:如果在这7条记录里面删除的是中间的几个记录(比如删除的是3,4两条记录),重启MySQL数据库后,insert一条记录后,ID都是8。因为内存或者数据库文件存储都是自增主键最大ID
操作数据库
列的数据类型
数值
tinyint 十分小的数据 1个字节
smallint 较小的数据 2字节
mediumint 中等大小的数据 3字节
int 标准的存储 4字节 常用的
big 较大的数据 8字节
float 浮点数 4字节 精度问题!
double 浮点数 8字节 精度问题!
decimal 字符串形式的浮点数 金融计算的时候使用
字符串
char 字符串固定大小 0-255
varchar 可变字符串 0-6535 常用,相当与java的String类型
tinytext 微型文本 2^8-1
text 文本串 2^16-1 保存大文本
时间日期
date YYYY-MM-DD,日期
time HH:mm:ss,时间格式
datetime YYYY-MM-DD HH:mm:ss 最常用的时间格式 时区不同,对应的时间不同
timestamp 时间戳,1970.1.1到现在的毫秒数 固定不变,全球统一
year 年份表示
null
没有值,未知
注意,不要使用NULL进行运算,结果为NULL
数据库的字段属性
Unsigned:
无符号的整数,声明了该列不能为负数
Zerofill:
0填充,不足的位数,用0来补充 ,int(3),5 --- 005
自增:
自动在上一条记录的基础上+1(默认),通常用来设计唯一的主键 -- index,必须是整数。
我们可以自定义设置主键的自增的起始值和步长。(高级中设置 一般不用)
非空:
假设设置为不为空,如果不给他赋值,就会报错。
不设置的话,如果不填写值,默认为null
默认:
设置默认值
比如 sex,默认值为男,如果不指定该列的值,则会有默认的值
字符集编码
mysql默认的编码是 Latin1,不支持中文,所以我们要将其设置为UTF-8
1.建表时设置,CHARSET=utf8
2.在my.ini中设置默认编码 character-set-server = utf8(不推荐使用,物理层面修改,通用性降低)
DML语言(增删改查)
where 条件运算符
| 操作符 | 意义 |
| = | 等于 |
| <>,!= | 不等于 |
| >=,<=.... | 大于小于 |
| between ... and ... | 在某个范围 |
| and && | 和 |
| or || | 或 |
| != not |
增 insert
# insert into 表名 (字段名1,字段名2 ....)values (值1,值2) ; # 主键自增可以省略 insert into student (age ,name) values (11,'张三'); #不写表字段,会一一对应,所以数据和字段一定要一一对应 # insert into student values ('张三'); insert into student (age) values (15);
-- 插入多个值
# insert into 表名 (字段名1,字段名2 ....)values (值1),(值2) ;
insert into student (age ,name) values (11,'张三'),(14,'李四'),(15,'王五');
注意事项:
1.字段和字段之间要用逗号隔开
2. 字段可以省略,但是后面的值要一一对应,不能少,顺序也不能变
3.可以同时插入多条数据,values后面的值需要使用,隔开。values(),()....
改 update
# update 表名 set colnum_name=value,[colnum_name=value ...] where 条件;
# 不指定条件也就是不加where,修改的是整张表,不建议使用
update student set name='李四' where id =2;
#修改多个属性,逗号隔开
update student set name='李四',age= 13 where id =2;
update student set name = '美甲' WHERE id BETWEEN 8 AND 9;
注意事项
update 表名 set colnum_name=value,[colnum_name=value ...] where 条件;
1. colnum_name是数据库的列,尽量加上 ‘ ’
2.注意加上筛选条件,如果没有加上,改变的是整个表的数据
3. value 的值可以是一个具体的值,也可以是一个变量(CURRENT_TIME)
4.多个设置属性之间,要用英文逗号隔开
删 delete
# delect from table where 条件 # delect from table;删除整张表 delect from student where id =1;--删除指定数据
TRUNCATE
清空一整个数据库,表的结构和索引不变
#清空 表 TRUNCATE table; TRUNCATE student;
相同点:都能删除元素,不会删除表结构
不同点:TRUNCATE 重新设置自增列,计数器会归0 ,不会影响事务
delect删除的问题
重启数据库中
InnoDB 自增会从新开始(存在内存当中,断电及失)
MyISAM 继续从上一个自增量开始(存在文件中,不会丢失)
一张自增表里面总共有 7 条数据,删除了最后 2 条数据,重启 mysql 数据库,又插入了一条数据,此时 id 是几? 看数据库的存储引擎是什么:
InnoDB:不重启,id =8,重启 id =7-2+1 =6;
因为 InnoDB只会把自增的最大值的id记录保存到内存中也就是id =7,重启之后,内存断电及失,现在id=7-2,又插入了一条,id = 7-2+1;
MyISAM :不重启,id =8,重启 id = 7+1;
因为 MyISAM 把自增最大的值的id记录保存在文件中,也就是id =7,重启之后,文件不会丢失,现在id= 7+1;
如果删除的两个元素是中间,不是末尾的两个元素,那么他们的id都为8。
查 selsct
# select colnum_name newName from table where 条件 select * from student ; select name,age from student where id =1;
# as 设置别名,可以给字段也可以给表
select name as '姓名',age as '年龄' from student where id =1;
# concat 字符拼接
SELECT CONCAT(fname,':') AS 姓名 FROM fuwu WHERE fid = 1;
# DISTINCT 去重
SELECT DISTINCT studentId FROM student;
注意:
1.别名: as
可以给字段,表起别名,有时候字段名或者表名不那名知意,所以我们要给他们取别名
select name as '姓名',age as '年龄' from student where id =1;2.去重: DISTINCT
SELECT DISTINCT studentId FROM student;3.拼接:concat
SELECT CONCAT(fname,':') AS 姓名 FROM fuwu WHERE fid = 1;4. != ,not
SELECT fname FROM fuwu WHERE fid !=1;
SELECT fname FROM fuwu WHERE not fid =1;模糊查询 like
| 运算符 | 语法 | 描述 |
| IS NULL |
a is null |
a为null,true |
| IS NOT NULL | a is not null | a不为null ,true |
| between .. and | a between b and c | a在[b,c]之间,true |
| like | a like b | sql匹配,如果a匹配b,true |
| in | a in (a1,a2...)具体的值 | 假设a在a1或者a2..其中一个值,true |
# is null 查询姓名为空的数据
SELECT name FROM student WHERE name IS NULL;
# is null 查询姓名不为空的数据
SELECT name FROM student WHERE name IS NOT NULL;
# between..and 查询成绩在80到 100 的数据
SELECT name FROM student WHERE score BETWEEN 80 AND 100;
#like % (代表0到任意个字符) _ 一个字符
#查询姓 刘 的同学
SELECT name FROM student WHERE name LIKE '刘%';
#查询姓 刘 后面一个字 的同学
SELECT name FROM student WHERE name LIKE '刘_';
#查询姓 刘 后面两个字 的同学
SELECT name FROM student WHERE name LIKE '刘__';
#查询姓名中有 刘 的同学
SELECT name FROM student WHERE name LIKE '%刘%';
#in 具体的一个或多个值
#查询学号为1,2,3的学生
SELECT name FROM student WHERE id in (1,2,3);
联表查询 join on
| inner join | 如果表中至少有一个匹配,就返回 |
| left join | 会从左表中返回所有的值,即使右表中没有匹配 |
| right join | 会从右表中返回所有的值,即使左表中没有匹配 |
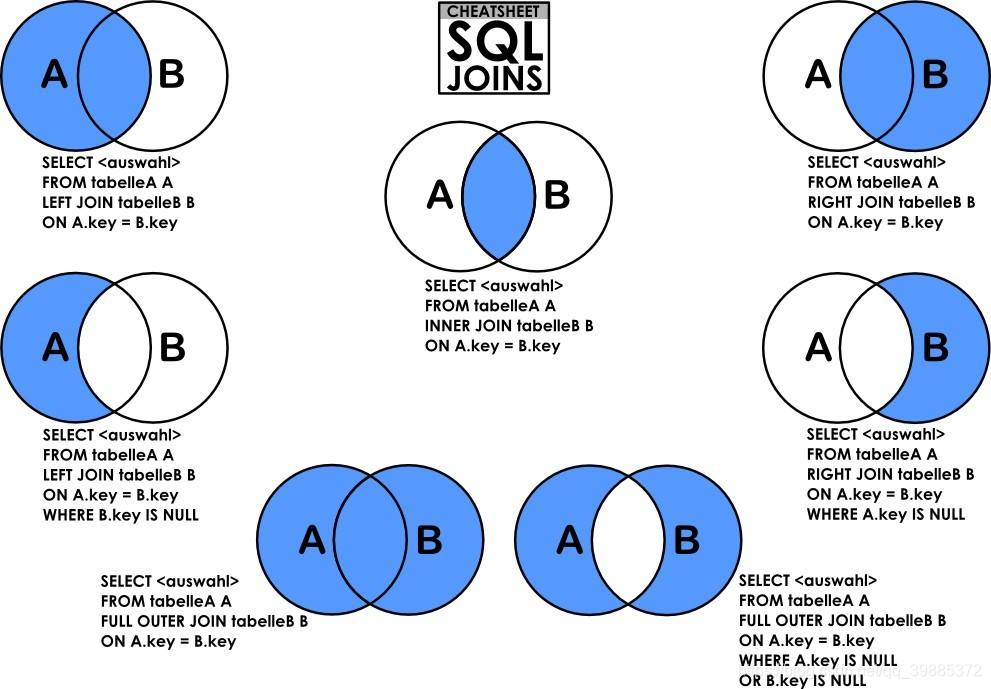
由于mysql中没有 full outer join 操作。 所以 6 = 1 union 4;7 =2 union 5;
# INNER JOIN 查询参加考试的学生
select s.name from student as s INNER JOIN result as r on s.studentNO = r.studentNO ;
# LEFT JOIN 左边符合条件的数据
select s.name from student as s LEFT JOIN result as r on s.studentNO = r.studentNO ;
# RIGHT JOIN 右边符合条件的数据
select s.name from student as s LEFT JOIN result as r on s.studentNO = r.studentNO ;
自连接
就是将一个表当成两个表来看
| id | fid 父级id | name |
| 1 | 0 | 人 |
| 2 | 1 | 影帝 |
| 3 | 2 | 朱一龙 |
# 查询子类 对应的父类 SELECT u1.name '子' , u2.name '父' FROM user u1,user u2 WHERE u1.`id` = u2.`fid`
分页,排序
排序:order by --- 升序 ASC , 降序 DESC
#按照id降序排列
SELECT * FROM student ORDER BY id DESC;
#按照id升序排列
SELECT * FROM student ORDER BY id ASC;
# 分页:limit 当前页,页面大小 -- 缓解数据库压力,更好的用户体验
# 0 -- 第一页,1 -- 每页就一行数据
SELECT fname FROM student limit 0,1;
#按照id升序排列并分页
SELECT * FROM student ORDER BY id ASC limit 0,1;
#(当前页-1)*页面大小 = 起始值 ,数据总数/页面大小 = 总页数
子查询
本质:在where语句中嵌套一个子查询语句,由内向外#查询所有学生的考试成绩(学号,科目编号,成绩)降序排列
#使用连接查询
select studentNO,r.subjectNO,studentResult
from result r
inner join subject sub on r.subjectNO = sub.subjectNO
where subjectName = '数学'
order by studentresult desc;
#使用子查询
select studentNO,subjectNO,studentResult
from result
where subjectNO = (
select subjectNO from subject where subjectName ="数学"
)
order by studentresult desc;
函数
| 函数名 | 描述 |
| count() | 计数 |
| sum() | 求和 |
| avg() | 平均值 |
| max() | 最大值 |
| min() | 最小值 |
| ............. | .... |
#查看有多少学生 select count(name) from student ; -- count(指定列),会忽略所有的NULL值
select count(*) from student ; -- count(*) 不会忽略 null值 count(*)和 count(1) 没有本质区别
select count(1) from student ; -- count(1) 不会忽略 null值 没有主键,查询效率最高
注意
WHERE 子句不能和聚合函数一起使用,使用 HAVING 子句,WHERE 子句在分组操作之前起作用,HAVING 子句在分组操作之后起作用
- WHERE 子句对表进行第一次筛选,它紧跟 FROM 之后;
- GROUP BY 子句对 WHERE 的筛选结果进行分组,它必须位于 WHERE 之后;
- HAVING 子句用来对分组的结果进行筛选,它必须位于 GROUP BY 子句之后;
- ORDER BY 子句对最终的结果集进行排序,它位于整个 SQL 语句的最后。
MD5 加密
单向加密 主要目的不是为了加密,而是为了网络传输数据时候防篡改
不安全 用户密码一致 ,生成的密文也是一致的
#插入时加密
insert into people(id,name,pwd)values(1,'哈哈',MD5(123)); # 使用MD5给pwd 加密 update people set pwd = MD5(pwd);
