

mysql 为啥用b+ 树
原因就是为了减少磁盘io次数,因为b+树所有最终的子节点都能在叶子节点里找见,
所以非叶子节点只需要存`索引范围和指向下一级索引(或者叶子节点)的地址` 就行了,
不需要存整行的数据,所以占用空间非常小,直到找到叶子节点才加载进来整行的数据。
B树非叶子节点也会存数据,所以不适合mysql(以后研究下mongo为啥用b树 再补充)
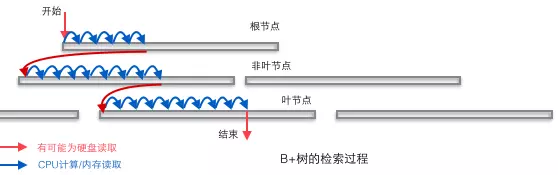
B+树适合作为数据库的基础结构,完全是因为计算机的内存-机械硬盘两层存储结构。内存可以完成快速的随机访问(随机访问即给出任意一个地址,要求返回这个地址存储的数据)但是容量较小。而硬盘的随机访问要经过机械动作(1磁头移动 2盘片转动),访问效率比内存低几个数量级,但是硬盘容量较大。典型的数据库容量大大超过可用内存大小,这就决定了在B+树中检索一条数据很可能要借助几次磁盘IO操作来完成。如下图所示:通常向下读取一个节点的动作可能会是一次磁盘IO操作,不过非叶节点通常会在初始阶段载入内存以加快访问速度。同时为提高在节点间横向遍历速度,真实数据库中可能会将图中蓝色的CPU计算/内存读取优化成二叉搜索树(InnoDB中的page directory机制)。

真实数据库中的B+树应该是非常扁平的,可以通过向表中顺序插入足够数据的方式来验证InnoDB中的B+树到底有多扁平。我们通过如下图的CREATE语句建立一个只有简单字段的测试表,然后不断添加数据来填充这个表。通过下图的统计数据(来源见参考文献1)可以分析出几个直观的结论,这几个结论宏观的展现了数据库里B+树的尺度。
1 每个叶子节点存储了468行数据,每个非叶子节点存储了大约1200个键值,这是一棵平衡的1200路搜索树!
2 对于一个22.1G容量的表,也只需要高度为3的B+树就能存储了,这个容量大概能满足很多应用的需要了。如果把高度增大到4,则B+树的存储容量立刻增大到25.9T之巨!
3 对于一个22.1G容量的表,B+树的高度是3,如果要把非叶节点全部加载到内存也只需要少于18.8M的内存(如何得出的这个结论?因为对于高度为2的树,1203个叶子节点也只需要18.8M空间,而22.1G从良表的高度是3,非叶节点1204个。同时我们假设叶子节点的尺寸是大于非叶节点的,因为叶子节点存储了行数据而非叶节点只有键和少量数据。),只使用如此少的内存就可以保证只需要一次磁盘IO操作就检索出所需的数据,效率是非常之高的。



